1.- Defina el concepto de traducción. ¿A qué alude dicho término? ¿Cuál es su significado biológico?
• La traducción es el proceso mediante el cual, a partir de ARN mensajero (ARNm), se sintetizan proteínas. La traducción consiste, pues, en la descodificación de la información genética contenida en el ARNm para que se sintetice una cadena peptídica.
• El término traducción alude a un cambio de lenguaje, ya que los ácidos nucleicos están constituidos por nucleótidos, mientras que las proteínas se caracterizan por sus secuencias de aminoácidos. El ARNm está “escrito” en un lenguaje de 4 signos, o sea, las 4 bases, mientras que las proteínas utilizan 20 signos (los 20 aminoácidos codificables).
• La traducción tiene un significado biológico muy importante en relación con la expresión de los genes, pues posibilita que la información genética contenida en los ácidos nucleicos quede plasmada en forma de proteínas, que son las biomoléculas fundamentales para la organización estructural y funcional de la célula.
2.- ¿Dónde se realiza la traducción? Cite los elementos que intervienen en dicho proceso.
• La traducción o biosíntesis de proteínas tiene lugar en los ribosomas, según la información aportada por el ARNm, que a su vez procede de la transcripción de un gen. Los ribosomas se hallan principalmente en el citosol (también en mitocondrias y cloroplastos).
• Los elementos que intervienen en la traducción son: ARNm, numerosos ARNt, ribosomas, aminoácidos, aminoacil-ARNt ligasas, translocasas, ribozimas (peptidil transferasas), ATP, GTP, así como una serie de proteínas citosólicas llamadas genéricamente factores de traducción (de iniciación, de elongación y de terminación).
3.- ¿Cuáles son las características o propiedades de la traducción del ARN mensajero?
Se consideran las siguientes:
• Es unidireccional. Los ribosomas se desplazan siempre en la misma dirección: desde el extremo 5’ del ARNm hacia el 3’, o sea, en el sentido 5' --> 3'..
• Es reiterativa. Un mismo ARNm puede ser traducido simultáneamente por numerosos ribosomas, constituyendo conjuntos funcionales denominados polirribosomas (polisomas).
• Es selectiva. No todo el ARNm se traduce, pues se descarta una región inicial y otra final.
• Requiere un intérprete o adaptador. Esta función es desempeñada por el ARN transferente. Cada molécula de ARNt se une por el extremo aceptor a un aminoácido específico, y por la zona del anticodón, a un triplete concreto del ARNm (llamado codón).
4.- Haga un comentario sobre el esquema adjunto y aclare el significado de las partes numeradas.

• Una de las propiedades de la traducción del ARN mensajero es ser selectiva. Esto quiere decir que sólo se traduce una parte de la cadena ribonucleotídica, concretamente, la llamada secuencia codificante, que está comprendida entre un codón iniciador y otro terminador. Esta región se encuentra acotada por otras que no se traducen, denominadas UTR (UnTranslated Region).
El extremo 5’p se considera el comienzo de la cadena de ARNm, y el 3’-OH, el final. Estos extremos sirven para designar las dos partes no traducidas, 5'-UTR y 3'-UTR, las cuales delimitan el marco abierto de lectura u ORF (Open Reading Frame).
• Significado de las partes numeradas:
1 = codón iniciador (AUG)
2 = codón terminador (puede ser UAA, UAG o UGA)
3 = secuencia codificante o marco abierto de lectura (ORF)
4 = secuencia 5’ no traducida (5’-UTR o líder)
5 = secuencia 3’ no traducida (3’-UTR o trailer)
5.- Haga un comentario sobre el esquema adjunto y nombre las partes numeradas.

• Este esquema ilustra la hipótesis de Crick sobre la función de adaptador del ARN transferente durante la traducción del ARN mensajero.
Se observa que el aminoácido está unido al ARNt por uno de los extremos, mientras que un triplete nucleotídico específico, llamado anticodón, situado en la zona opuesta, “reconoce” a su codón en el ARNm estableciendo enlaces de hidrógeno entre las bases complementarias.
• Significado de las partes numeradas:
1 = aminoácido
2 = extremo aceptor
3 = ARN transferente
4 = triplete anticodón
5 = ARN mensajero
6 = codón
6.- Haga un comentario sobre el esquema adjunto identificando las partes numeradas. ¿Qué particularidad presenta el “brazo T”?

• El esquema representa la estructura secundaria de un ARNt de levadura específico para el aminoácido fenilalanina. Este modelo característico, conocido como “hoja de trébol”, se debe a los enlaces por puente de hidrógeno que se establecen en algunas regiones entre los pares de bases: guanina-citosina y adenina-uracilo.
• Significado de las partes numeradas:
1 = anticodón
2 = brazo del anticodón
3 = brazo variable
4 = extremo 5’-P (comienzo de la cadena nucleotídica)
5 = extremo 3’-OH (aceptor del aminoácido)
• Los ARN transferentes contienen casi un 10 % de bases modificadas. El llamado “brazo T” hace referencia a la presencia de timina, lo cual es una rareza ya que las bases características de todos los ARN son: adenina, guanina, citosina y uracilo (la timina es propia del ADN).
7.- ¿Cuántos nucleótidos contienen los ARN transferentes? Escriba la fórmula del primero y del último (consulte su libro).
• Generalmente, los ARNt están formados por un número de nucleótidos comprendido entre 70 y 90, siendo el primero de la cadena la guanosina 5’ monofosfato, y el último, la adenosina 5’ monofosfato, que tiene libre el OH de la posición 3’ y sirve para unirse con el aminoácido correspondiente.
De manera muy simplificada, la cadena general de los ARNt es:
(5’p)G-… (80 nucleótidos)… -C-C-A(3’-OH).
• Fórmula de los nucleótidos de los extremos:

8.- ¿Qué son los ribosomas? Haga un esquema.
• Los ribosomas son orgánulos celulares desprovistos de membrana cuya función es sintetizar proteínas.
Los ribosomas existen tanto en células eucarióticas como procarióticas y en ellos se distinguen dos subunidades desiguales, que pueden separarse mediante ultracentrifugación, pues sus coeficientes de sedimentación varían según el tamaño y la forma.
Estructuralmente, cada ribosoma constituye un enorme complejo macromolecular formado por 3 ó 4 moléculas de ARN ribosómico y un número variable de proteínas asociadas, que suele oscilar entre 50 y 80, dependiendo del organismo en cuestión.
Las proteínas ribosómicas de la subunidad grande suelen designarse con la letra L (large): L1, L2,…, y las de la subunidad pequeña, con la S: S1, S2,… No hay que confundir esta “S”, de la palabra inglesa small, con la unidad del coeficiente de sedimentación (S = Svedberg).
• Lo usual en los esquemas es dibujar un contorno sencillo y más o menos redondeado:

La zona superficial del ribosoma la forma el principalmente el ARN ribosómico, sobre todo en las regiones que sirven para el mutuo reconocimiento de las subunidades.
9.- Características de los ribosomas de células procariotas (ilustre con un esquema).
En una célula procariota suelen existir entre 10.000 y 15.000 ribosomas. Estos ribosomas miden unos 18 nanómetros de diámetro y presentan un coeficiente de sedimentación cuyo valor es 70 S.
Los ribosomas que se suelen tomar como modelo son los de la bacteria Escherichia coli. La subunidad mayor (50 S) contiene 2 ARNr (23 S y 5 S) y 31 proteínas distintas (L1, L2,…, L31). La subunidad menor (30 S) posee una molécula de ARNr (16 S) y 21 proteínas diferentes (S1, S2,…, S21). Las proteínas de las subunidades se designan con las letras L o S (del inglés large, grande ysmall, pequeña).
Esquema:

En resumen: los ribosomas de células procariotas son del tipo 70 S y están constituidos por 3 ARNr y unas 50 proteínas.
Nota.- Al ensamblarse las subunidades quedan parcialmente superpuestas, razón por la cual no coincide el valor del coeficiente de sedimentación del conjunto (70 S) con la suma de los correspondientes a las subunidades individualizadas (50 S y 30 S).
10.- Características de los ribosomas de células eucariotas (ilustre con un esquema).
Los ribosomas de células eucariotas tienen un diámetro comprendido entre 20 y 22 nanómetros, siendo la constante de sedimentación 80 S (ver nota).
La subunidad pequeña (40 S) posee una molécula de ARNr (18 S) y de 30 a 33 proteínas diferentes: S1, S2, S3… La subunidad grande (60 S) contiene 3 moléculas de ARNr (coeficientes de sedimentación: 23 S, 5 S y 5,8 S) y de 45 a 50 proteínas distintas: L1, L2, L3… Como se indicó en una cuestión anterior, las proteínas de las subunidades se designan con las letras L o S (del inglés large, grande y small, pequeña).
Esquema:

En resumen: los ribosomas de células eucariotas son del tipo 80 S y están constituidos por 4 ARNr y unas 80 proteínas.
Nota.- Los ribosomas que se hallan en el interior de mitocondrias y cloroplastos son del tipo 70 S, es decir, similares a los de células procariotas, circunstancia que constituye un buen argumento a favor de la teoría endosimbióntica.
11.- Función del ribosoma.
La función de los ribosomas es sintetizar las proteínas celulares.
En relación con dicha función es conveniente realizar las siguientes consideraciones:
• El ribosoma no puede traducir directamente el ADN. Por ello, ciertas regiones del ADN se transcriben previamente en ARN mensajeros (ARNm).
• El ribosoma asegura que se siga la secuencia de decodificación especificada por el ARNm, de modo que las proteínas se sinteticen correctamente.
• El código genético se traduce en la subunidad pequeña. El ensamblaje secuencial de los aminoácidos que integran la cadena proteica tiene lugar en la subunidad grande.
Resumiendo: el ribosoma es el orgánulo celular que traduce el código genético en instrucciones funcionales (proteínas), proceso que tiene lugar en todos los organismos.
12.- ¿Por qué algunos autores consideran al ribosoma como una gran ribozima?
Las actividades propias del ribosoma, como la decodificación del mensaje genético, la acción peptidil transferasa y la translocación son propiedades intrínsecas del ARN ribosómico. Por esta razón hay autores que consideran al ribosoma como la mayor de las ribozimas conocidas.
Nota.- Las ribozimas son cadenas de ARN con actividad catalítica.
14.- ¿A qué se llama “protorribosoma”?
Ciertos segmentos de la secuencia de los ARN ribosómicos se han conservado a lo largo de la evolución a través de los reinos Eubacteria, Arquea y Eucaria (Animales, Plantas y Hongos).
Para algunos autores, la conservación secuencial existente en regiones concretas de los ARN ribosómicos es tal, que cabe suponer que todos los ribosomas existentes en los organismos actuales descienden de un primitivo “protorribosoma”.
Desde el punto de vista evolutivo, el protorribosoma equivale a la hipotética estructura ancestral presente en las primeras células para biosintetizar proteínas.
15.- ¿Qué relación existe entre el nucléolo y los ribosomas?
Considerando los ribosomas de células eucariotas, es en el nucléolo donde se transcriben los genes de ARN ribosómico, teniendo también lugar la asociación con las proteínas ribosómicas, que llegan al núcleo desde el citoplasma por los poros nucleares, constituyendo los complejos macromoleculares propios de cada subunidad.
Las subunidades ribosómicas grandes y pequeñas, una vez formadas en el interior del núcleo, son desplazadas hacia el citoplasma a través de los poros nucleares, permaneciendo separadas hasta el momento de unirse al ARN mensajero para realizar la biosíntesis de proteínas.
16.- Suponga que el ribosoma de la figura adjunta es de célula procariota. Indique los coeficientes de sedimentación. Busque imágenes en Internet de alguna subunidad.


• Ribosoma (procariota): 70 S. Subunidades: 30 S y 50 S.
17.- Indique los coeficientes de sedimentación de los ribosomas adjuntos.

Los coeficientes de sedimentación de ambos tipos de ribosomas y de las correspondientes subunidades son los siguientes:

18.- ¿Cuál es el significado de la letra “S” en las constantes o coeficientes de sedimentación?
La S o unidad Svedberg es la que se emplea para indicar el coeficiente de sedimentación de una partícula o macromolécula en los análisis de ultracentrifugación.
La letra S es utilizada en honor del científico sueco Theodor Svedberg, galardonado con el premio Nobel de Química en 1926. Gracias a su invención de la ultracentrífuga y a la metodología analítica, fue posible la separación de macromoléculas o partículas en las dispersiones coloidales y otros sistemas dispersos, así como la medición precisa del coeficiente de sedimentación.
19.- ¿Qué representa el esquema adjunto? Identifique las partes numeradas.

• Este esquema representa un ribosoma.
Se observa la existencia de los tres sitios característicos, que alojarán sendas moléculas de ARN transferente durante la traducción del ARN mensajero.
• Partes numeradas:
1 = subunidad grande
2 = subunidad pequeña
3 = sitio A (para el aminoacil-ARNt)
4 = zona de unión con el ARN mensajero
5 = sitio E (del ingés exit, salida)
6 = sitio P (para el peptidil-ARNt)
20.- ¿Qué representa el esquema adjunto? Identifique las partes numeradas.

• Este esquema representa un ribosoma.
• Partes numeradas:
1 = subunidad grande
2 = subunidad pequeña
3 = sitio P (peptidil, peptidilo)
4 y 5 = no se puede precisar cuál de ellos es el sitio A (aminoacil, aminoacilo) o el E (exit).
21.- Buscando imágenes del ribosoma en Internet se ha encontrado la figura adjunta. Nombre las partes numeradas.

Se trata de un ribosoma de célula procariota (70 S).
Partes numeradas:
1 = extremo 5’ del ARN mensajero
2 = sitio E (exit)
3 = sitio P (peptidilo)
4 = sitio peptidiltransferasa
5 = sitio A (aminoacilo)
6 = subunidad grande (50 S)
7 = subunidad pequeña (30 S)
8 = extremo amino terminal de la cadena polipeptídica
22.- ¿Qué son las secuencias de Shine-Dalgarno? Haga un esquema.
Son secuencias características del ARN mensajero de las células procariotas, localizadas en las proximidades del codón iniciador AUG, las cuales se aparean con regiones específicas de ARN ribosómico 16 S, propio de la subunidad menor del ribosoma, mediante enlaces por puente de hidrógeno (pph), forzando así una localización concreta del triplete AUG en la iniciación de la síntesis de proteínas.
Esquema:

24.- Interprete el esquema siguiente y nombre las partes numeradas.

• Se trata de un polirribosoma o polisoma, es decir, un conjunto de ribosomas (color azul) asociados a una misma molécula de ARN mensajero, que se van desplazando durante el proceso de traducción, posibilitando la síntesis de numerosas cadenas de una misma proteína.
El color rojo corresponde a la cadena peptídica, que se va alargando progresivamente, a medida que el ribosoma se desplaza por el ARNm (en sentido 5’ --> 3’).
Se observa que el conjunto tiende a adoptar una disposición en espiral.
• Los nombres de las partes numeradas son:
1 = proteína sintetizada, ya desprendida
2 = subunidad ribosómica mayor libre
3 = subunidad ribosómica menor libre
4 = extremo 5’p (inicial) del ARN mensajero
5 = extremo inicial (amino terminal) de la cadena peptídica
6 = ribosoma (con la subunidad menor orientada hacia la zona interna de la espiral).
25.- En relación con los ribosomas, ¿con qué figura está de acuerdo, A o B? Justifique la respuesta.

Todos los dibujos son igualmente válidos (el color es irrelevante). El ribosoma funcional está constituido por dos subunidades desiguales, una mayor que otra, que se asocian al comenzar la traducción del ARN mensajero y se separan cuando este proceso finaliza.
Dado que la traducción tiene carácter reiterativo, cada vez que se inicia o se repite el proceso, las subunidades pueden asociarse de cualquier manera, aunque siempre una grande con otra pequeña.
1.- ¿Cuál es la señal del ARN mensajero que marca el inicio de la traducción?
La señal de inicio utilizada en la traducción es un triplete AUG (5’-AUG-3’), denominado codón iniciador, que se halla muy próximo al extremo 5’ del ARN mensajero.
Nota.- De forma excepcional, los procariotas pueden emplear como señales de inicio los tripletes GUG o UUG.
2.- ¿Cuál es el aminoácido que figura al comienzo de la cadena polipeptídica sintetizada?
El codón iniciador AUG determina que todas las proteínas sintetizadas empiecen por el aminoácido metionina (M, Met) en las células eucariotas, o bien, por formilmetionina (fMet) en las procariotas (ver nota). Con frecuencia, el aminoácido inicial desaparece durante el procesado postraduccional.
Nota.- Cuando las células procariotas, excepcionalmente, utilizan como codón iniciador GUG o UUG (en vez de AUG), tiene lugar la incorporación de fMet en ambos casos.
La síntesis proteica en orgánulos eucarióticos tales como mitocondrias y cloroplastos también empieza con fMet.
3.- Escriba la fórmula de los aminoácidos metionina y formilmetionina (consulte su libro).
Ambos son aminoácidos azufrados, como puede observarse en las fórmulas. La formilmetionina se caracteriza por la presencia de un grupo formilo (H-C=O) ligado al N de la metionina.

4.- Cite las fases o etapas que suelen considerarse en la traducción del ARN mensajero.
Las fases características o fundamentales de la traducción son tres: iniciación, elongación y terminación, cada una de las cuales requiere un aporte energético (ATP, GTP) y una serie factores proteicos específicos.
Cabe señalar que hay libros en los que el mecanismo de la traducción es desarrollado en cinco fases: activación de los aminoácidos, iniciación, elongación, terminación y maduración o procesado de la proteína.
Los autores que consideran 3 fases interpretan que otros procesos, tales como la activación y la maduración, tienen carácter complementario y no son estrictamente fases de la traducción.
5.- Escriba un resumen de la traducción considerando las tres etapas fundamentales (excluya la activación y la maduración).
El proceso de la traducción, omitiendo la activación de los aminoácidos y el procesado postraduccional (maduración), se puede resumir así:
• Iniciación. El comienzo de la traducción se caracteriza por la formación del complejo de iniciación (80 S en eucariotas, 70 S en procariotas), que está integrado por un ribosoma unido al ARNm y al ARNt iniciador cargado con el primer aminoácido (metionina en eucariotas, formilmetionina en procariotas).
Esta fase requiere aporte energético (GTP, ATP) y proteínas citosólicas llamadas factores de iniciación.
• Elongación. La cadena peptídica se va alargando por unión covalente de sucesivos aminoácidos (enlaces peptídicos), cada uno de los cuales es situado previamente en el ribosoma por su correspondiente ARNt, en función de los enlaces específicos que deben establecerse entre el codón (ARNm) y el anticodón (ARNt).
Cada ribosoma se va desplazando a lo largo del ARNm de tres en tres tripletes (translocación), en sentido 5’ --> 3’.
Esta fase precisa proteínas citosólicas llamadas factores de elongación y aporte energético (GTP).
• Terminación. El final de la síntesis proteica está señalado en el ARNm por uno de estos tres codones de terminación: UAA, UAG o UGA, llamados mudos o sin sentido. Tras la fijación de un factor de liberación a uno de ellos tiene lugar la separación de la cadena peptídica y de las subunidades ribosómicas, las cuales pueden reiniciar el proceso.
Esta fase requiere el concurso de factores de liberación.
6.- ¿Cuándo se dice que un ARN transferente está “cargado”?
Un ARNt se considera “cargado” cuando se ha unido a su aminoácido específico, estableciéndose un enlace tipo éster entre el 3’-OH del ARNt (extremo aceptor) y el grupo carboxilo del aminoácido, el cual queda “activado”.
El conjunto formado por la molécula de aminoácido unida a otra de ARN transferente recibe la denominación de aminoacil-ARNt.
Estrictamente, las uniones entre los aminoácidos y sus respectivos ARNt no son fases de la traducción, pero resultan absolutamente necesarias para posibilitar dicho proceso.
7.- ¿En qué consiste la activación de los aminoácidos? Escriba la reacción general (sin fórmulas).
• La activación de los aminoácidos proteicos consiste en la unión de cada uno de ellos a su ARN transferente específico, mediante acción enzimática, proceso que tiene lugar en el citosol (así como en el interior de cloroplastos y mitocondrias).
Estas reacciones de activación son catalizadas por un grupo de enzimas dependientes de ATP y Mg2+, denominadas genéricamente “aminoacil-ARNt ligasas”, de las cuales hay 20 distintas, una para cada aminoácido. Cada una de ellas es muy específica tanto para el aminoácido como para el ARNt respectivo (ver nota).
• La reacción general de activación es:
ATP + aminoácido + ARNt —› aminoacil-ARNt + AMP + PPi
El pirofosfato o difosfato (PPi) es hidrolizado a fosfato inorgánico, razón por la cual el proceso activador presenta un balance energético favorable.
De esta forma, cada aminoácido queda unido al extremo aceptor de un ARNt específico, resultando que un gran número de transferentes se encuentran enlazados covalentemente a sus aminoácidos respectivos antes de iniciarse la traducción.
8.- ¿Qué tipo de enlace se establece entre el aminoácido y el ARN transferente? Haga un esquema.
• El aminoácido se une al ARNt mediante un enlace covalente tipo éster, quedando constituido el correspondiente aminoacil-ARNt. La unión se establece entre el grupo carboxilo del aminoácido y el llamado extremo aceptor del ARNt (que, generalmente, es la posición 3’-OH).
• Esquema:

9.- Escriba sin fórmulas la reacción de activación del aminoácido leucina (L, Leu) y el nombre de la enzima que cataliza el proceso.
• La reacción es:
ATP + leucina + ARNtLeu —› leucil-ARNtLeu + AMP + PPi
(O bien: ATP + leucina + ARNtL —› leucil-ARNtL + AMP + PPi)
• La enzima activadora es: leucina-ARNtLeu ligasa
10.- Escriba sin fórmulas la reacción de activación de los aminoácidos serina (Ser, S) y tirosina (Tyr, Y), así como el nombre de la enzima activadora correspondiente.
• Activación de la serina:
ATP + serina + ARNtSer —› seril-ARNtSer + AMP + PPi
Enzima activadora: serina-ARNtSer ligasa
• Activación de la tirosina:
ATP + tirosina + ARNtY —› tirosil-ARNtY + AMP + PPi
Enzima activadora: tirosina-ARNtY ligasa
14.- Escriba sin fórmulas la reacción de activación catalizada por “EC 6.1.1.9” (busque en Internet).
• “EC 6.1.1.9” corresponde a la enzima: valina-ARNtV ligasa
• La reacción de activación es la siguiente:

15.- ¿Por qué se dice que las enzimas aminoacil-ARNt ligasas son doblemente específicas? Escriba la reacción global.
• Cada aminoacil-ARNt ligasa resulta doblemente específica porque, por un lado, debe reconocer a uno de los 20 aminoácidos, y por otro, a un tipo concreto de ARN transferente (gracias a una decena de nucleótidos referenciales situados en posiciones críticas, que difieren de un ARNt a otro).
• La reacción global que catalizan dichas enzimas es la siguiente:

Este proceso requiere la presencia de iones Mg2+ y está favorecido por la hidrólisis del pirofosfato:
PPi + H2O —› 2 Pi + energía
16.- ¿Por qué se dice en algunos libros que la reacción de activación de los aminoácidos ocurre en dos etapas? (Aclare la respuesta con esquemas).
La acción enzimática de cada aminoacil-ARNt ligasa determina, en primer lugar, que el aminoácido se una al AMP, quedando enlazado seguidamente con su ARN transferente específico, formando el aminoacil-ARNt.
Esquemáticamente (E = enzima, a = aminoácido):

Se observa que en la 1ª etapa se forma un aminoacil-AMP unido a la enzima, siendo en la 2ª cuando tiene lugar la transferencia al ARNt para formar el aminoacil-ARNt.
17.- En relación con la pregunta anterior, haga un esquema de la estructura molecular de los “aminoacil-AMP” y “aminoacil-ARNt”.
• La estructura molecular de los aminoacil-AMP (adenilatos de aminoacilo), que se forman en el centro activo de las enzimas aminoacil-ARNt ligasas, es la siguiente:

• La acción enzimática determina, seguidamente, que el grupo aminoacilo sea transferido al extremo aceptor del ARNt, quedando constituido el aminoacil-ARNt:

Se observa que el aminoácido queda unido al ARNt mediante un enlace covalente tipo éster.
18.- En relación con la unión de los aminoácidos a sus correspondientes ARN transferentes, ¿qué esquema le parece más correcto, A o B?

En principio puede considerarse que ambos esquemas son correctos, pues según la posición concreta de la esterificación se distinguen dos subtipos de enzimas aminoacil-ARNt ligasas:
• Subtipo I: la unión del aminoácido tiene lugar en el hidroxilo 2’ del nucleótido terminal del ARNt (figura A), pero seguidamente es trasladado a la posición 3’ por isomerización.
• Subtipo II: la esterificación se produce directamente sobre el hidroxilo 3’ del correspondiente ARNt (figura B).
20.- ¿En qué fase de la traducción tiene lugar la formación de los enlaces peptídicos? Explique cómo se establece el primero de ellos.
• Los enlaces peptídicos se forman durante la fase de elongación, gracias a la acción catalítica del complejo enzimático peptidil transferasa. Estos enlaces son los que posibilitan el progresivo alargamiento de la cadena peptídica que se sintetiza.
• Recordemos que el enlace peptídico se establece entre los grupos carboxilo y amino de sendos aminoácidos. Esquema:

La situación previa para la formación del primer enlace peptídico es que cada aminoácido está unido mediante enlace tipo éster a su ARN transferente, constituyendo el correspondiente aminoacil-ARNt. Esquema:

El mecanismo de la reacción está fundamentado en la interacción del grupo amino del 2º aminoácido con el carboxilo del 1º, lo cual implica la rotura del enlace éster que lo une al ARNt1. Esquema:

La reacción formadora del enlace peptídico es idéntica durante el transcurso de la biosíntesis proteica. Cabe observar que el primer aminoácido de la cadena peptídica presenta el grupo amino libre (-NH2).
22.- ¿Qué representa la estructura molecular adjunta? Identifique las partes numeradas.

• Esta estructura representa una cadena peptídica formada por n aminoácidos, el último de los cuales está unido al ARN transferente, conjunto que constituye el llamado peptidil-ARNt.
• Partes numeradas:
1 = ARN transferente, específico del último aminoácido
2 = enlace peptídico
3 = grupo amino terminal (propio del 1er aminoácido)
4 = radical o cadena lateral del 2º aminoácido
5 = enlace éster, establecido entre el grupo carboxilo del último aminoácido y el extremo 3’-OH del ARNt.
6 = enlace N-glucosídico (entre la ribosa y la base nitrogenada)
23.- ¿Cómo se separa la cadena peptídica sintetizada del último ARN transferente al que permanece unida? Haga esquemas.
La separación de la cadena peptídica también es llevada a cabo por el complejo enzimático peptidil transferasa, que en este caso final, cuando un factor de liberación ocupa el sitio A del ribosoma (en lugar de otro aminoacil-ARNt), hidroliza el enlace éster que une la cadena peptídica al extremo 3' del ARNt. En otras palabras: la cadena peptídica queda libre al ser "transferida" a una molécula de agua.
Esquema de la situación previa:

Esquema resultante de la actividad peptidil transferasa:

Se observa que el primer aminoácido de la cadena peptídica sintetizada tiene libre el grupo amino, y el último, el carboxilo.
24.- ¿Qué entiende por maduración o procesado de la proteína sintetizada?
Esto significa que la cadena peptídica sintetizada y liberada se pliega adoptando la conformación tridimensional característica para ser funcional (proteína nativa).
Antes o después del plegamiento, dicha cadena puede sufrir algunas transformaciones por acción enzimática, tales como: eliminación del primer aminoácido, incorporación de grupos metilo, carboxilo u otros en los radicales de ciertos aminoácidos, o bien, establecer uniones con oligosacáridos o grupos prostéticos.
Tal serie de transformaciones recibe también la denominación de procesado postraduccional.
25.- (Consulte el código genético). Prediga el resultado y escriba una conclusión acerca del experimento realizado utilizando como molde, en un sistema de síntesis proteica libre de células, el polinucleótido:

Según la clave genética, AAA codifica a la lisina (Lys) y AAC, a la asparagina (Asn). El polipéptido resultante es:
H2N-Lys-(Lys)n-Asn-COOH
Puesto que la asparagina es el residuo carboxilo terminal, el codón AAC debió ser el último en traducirse.
Conclusión: el ARN mensajero se traduce en el sentido 5’ –› 3’.
Nota.- En las células procariotas el ARNm puede ser traducido mientras se completa la transcripción, dado que su extremo 5’ interacciona con los ribosomas instantes después de ser sintetizado.
26.- Si un ARN mensajero está formado por 600 nucleótidos, ¿puede ser posible que la cadena peptídica sintetizada tenga tan solo 60 aminoácidos? Justifique la respuesta.
Considerando que los 600 nucleótidos forman la secuencia codificante del ARNm, cabe esperar que la proteína sintetizada posea 200 aminoácidos, dado que cada uno está codificado por un codón o triplete de nucleótidos.
Si la proteína resultante tiene 60 aminoácidos caben dos posibilidades: que la presencia de un codón mudo o sin sentido interrumpa la síntesis, o bien, que la secuencia codificante conste de 180 nucleótidos, correspondiendo el resto a las regiones que no se traducen (5’-UTR y 3’-UTR).
27.- En relación con la traducción o biosíntesis de proteínas, ordene las siguientes frases de la manera correcta:
• El ribosoma se desplaza un triplete en el sentido 5’ –› 3’.
• Posteriormente se une la subunidad mayor.
• El ARNm se une a la subunidad menor del ribosoma.
• Al lugar A llega otro ARNt con el siguiente aminoácido.
• Ahora el dipéptido se halla en el lugar P (peptidil) y queda libre el lugar A (aminoacil).
• Se unen ambos aminoácidos mediante un enlace peptídico.
La ordenación correcta de las frases anteriores es la siguiente:
• El ARNm se une a la subunidad menor del ribosoma.
• Posteriormente se une la subunidad mayor.
• Al lugar A llega otro ARNt con el siguiente aminoácido.
• Se unen ambos aminoácidos mediante un enlace peptídico.
• El ribosoma se desplaza un triplete en el sentido 5’ –› 3’.
• Ahora el dipéptido se halla en el lugar P (peptidil) y queda libre el lugar A (aminoacil).
28.- ¿Cuál es el destino de las proteínas sintetizadas? ¿A qué se llama péptido señal (secuencia señalizadora)?
• El destino de las proteínas sintetizadas varía según la ubicación de los ribosomas que han intervenido en el proceso:
Ribosomas libres. El destino de las proteínas sintetizadas por los ribosomas libres es alguno de los siguientes: citosol, membrana plasmática, citoesqueleto, mitocondrias, plastos, peroxisomas, núcleo (histonas, polimerasas, etc.).
Ribosomas del RER. El destino de las proteínas sintetizadas por ribosomas asociados al retículo endoplasmático rugoso es: el complejo de Golgi y los lisosomas.
• Por lo que respecta al péptido señal (o secuencia señalizadora), las proteínas recién sintetizadas suelen presentar uno o varios de ellos, que sirven para determinar su ubicación posterior en función de los receptores específicos de la membrana de los orgánulos. La ausencia de péptido señal determina que la proteína quede en el citosol.
29.- Escriba un comentario sobre el esquema adjunto, indicando el significado de las figuras numeradas y de las letras A y B.

Este esquema representa la maduración de la insulina.
• La figura 1 corresponde a la preproinsulina, observándose en su cadena peptídica 4 regiones diferenciadas, siendo “A” la secuencia señal (color rojo).
• La figura 2 es la proinsulina, formada cuando se pierde la secuencia señal del extremo N-terminal. La letra B está marcando la parte denominada péptido C (color azul), que será eliminado por un doble corte proteolítico.
• La figura 3 representa el estado final, es decir, la insulina madura, plegada y funcional, observándose los tres puentes disulfuro característicos, dos intercatenarios y uno intracatenario.
Nota.- La insulina es la hormona hipoglucémica que se produce en el páncreas, concretamente, en las células beta de los islotes de Langerhans, en forma de un precursor inactivo.
La insulina activa está integrada por 51 aminoácidos, 30 en la cadena B y 21 en la A, siendo ésta reconocible por su puente disulfuro intracatenario. La secuencia fue descubierta por el bioquímico inglés F. Sanger, que fue galardonado con un premio Nobel.
La deficiencia de insulina desencadena la diabetes mellitus.
30.- ¿Por qué se dice que los ARN mensajeros presentan inestabilidad metabólica?
Se dice que los ARN mensajeros presentan inestabilidad metabólica porque su existencia en el interior de la célula es limitada, al ser degradados por nucleasas específicas. Tal circunstancia implica que debe existir una síntesis frecuente de los ARNm, lo cual requiere una transcripción activa del gen correspondiente.
En las células procariotas, el transcrito primario de un gen sirve como ARNm y suele tener una vida media muy corta (minutos). Sin embargo, el periodo funcional de los ARNm eucariotas es mayor, puesto que la caperuza y la cola adquiridas durante el procesado postranscripcional parecen conferir cierta protección frente a las nucleasas.
1.- Interprete el esquema adjunto y nombre las partes numeradas.

• Este esquema sirve para ilustrar la fase de iniciación del proceso de la traducción. El llamado complejo de iniciación está aún incompleto ya que no ha sido dibujada la subunidad ribosómica mayor.
• Los nombres de las partes numeradas son:
1 = extremo 5’ del ARN mensajero
2 = subunidad ribosómica menor
3 = codón iniciador (5’-AUG-3’)
4 = anticodón (3’-UAC-5’) del ARNt iniciador.
5 = aminoácido unido al extremo aceptor (3’) del ARNt, conjunto que constituye un aminoacil-ARNt. Dada la presencia del codón AUG, podría tratarse de la metionina (eucariotas) o la formilmetionina (procariotas).
6 = extremo 5’ del ARNt iniciador
7 = sitio o lugar A (aminoacilo)
8 = segundo codón del ARNm
9 = extremo 3’ del ARNm
2.- Interprete el esquema adjunto indicando el paso inmediato posterior. Nombre las partes numeradas. ¿Cuántos enlaces como el señalado con el nº 7 se formarían?

• Este esquema representa el comienzo de la elongación. Se observa que el complejo de iniciación está formado y que el siguiente aminoacil-ARNt (con el anticodón GCA) ha ocupado el sitio A.
• El paso inmediato posterior es la formación del primer enlace peptídico, que se establece entre el primer aminoácido (color amarillo) y el segundo (verde), según reacción catalizada por el complejo enzimático peptidil transferasa.
• Los nombres de las partes numeradas son:
1 = extremo 5’ del ARN mensajero
2 = subunidad ribosómica menor
3 = subunidad ribosómica mayor
4 = sitio P, ocupado por el ARNt iniciador
5 = arginina (según el codón 5’-CGU-3’). Cada aminoácido se halla unido al extremo aceptor de su ARNt específico.
6 = sitio A, ocupado por el arginil-ARNtArg.
7 = enlace por puente de hidrógeno (pph)
8 = extremo 3’ del ARN mensajero
• La interacción codón-anticodón se produce por apareamiento antiparalelo, mediante la formación de enlaces por puente de hidrógeno (pph), entre las cadenas de ARNm y de ARNt.
Dado que se forman 2 enlaces pph entre el par AU, y 3 entre el GC, se formarían 7 enlaces entre 5’-AUG-3’ y 3’-UAC-5’. En el segundo caso, entre 5’-CGU-3’ y 3’-GCA-5’, se formarían 8.
3.- Interprete el esquema adjunto y nombre las partes numeradas.

• Este esquema representa la fase de iniciación. La subunidad ribosómica menor se ha desplazado por el ARN mensajero (en sentido 5’ --> 3’), con el aporte energético del ATP, hasta encontrar el codón iniciador, el cual queda emparejado con el anticodón del ARNt iniciador (que en este dibujo está situado en la zona del sitio P).
• Partes numeradas:
1 = caperuza 5’ del ARNm
2 = extremo 3’ del ARNm
3 = región que no se traduce (5’-UTR)
4 = enlace tipo éster
5 = aminoacil-ARNt iniciador
6 = zona parcial del sitio P
7 = zona parcial del sitio A
4.- Interprete el esquema adjunto e identifique las partes numeradas.

• Este esquema ilustra el comienzo de la elongación, justo antes de la formación del primer enlace peptídico.
• Partes numeradas:
1 = caperuza 5’ del ARNm (propia de los ARNm eucarióticos)
2 = extremo 3’ del ARNm
3 = subunidad ribosómica menor (40 S)
4 = sitio E (exit)
5 = subunidad ribosómica mayor (60 S)
6 = primer aminoácido (metionina en la biosíntesis eucariótica)
7 = siguiente aminoácido
8 = enlace covalente, tipo éster
9 = sitio P, ocupado por el aminoacil-ARNt iniciador: ARNtMet
10 = sitio A, ocupado por el siguiente aminoacil-ARNt
5.- Haga una interpretación del esquema adjunto y nombre las partes numeradas.

• Este esquema ilustra la fase de elongación, tras la formación del primer enlace peptídico. También se observa que el ribosoma, concretamente la subunidad mayor, ha realizado la transposición (o translocación).
• Partes numeradas:
1 = región que no se traduce (5’-UTR)
2 = caperuza 5’ del ARNm
3 = ARNt libre o saliente, situado en el sitio E (exit)
4 = subunidad ribosómica mayor (translocada)
5 = primer aminoácido (metionina)
6 = segundo aminoácido
7 = enlace peptídico
8 = enlace éster
9 = zona del sitio A en la subunidad mayor
10 = dipeptidil-ARNt
11 = extremo 3’ del ARNm
6.- Interprete el esquema adjunto e indique el significado de los números y de las letras.

• Este esquema ilustra la fase de elongación. Se observa que la cadena peptídica consta de 4 aminoácidos y está a punto de ser incorporado el 5º.
• Los números representan aminoácidos, de los cuales los 4 primeros ya están unidos.
• Partes marcadas con letras:
A = ARNt saliente (estaba unido al aminoácido nº 3)
B = sitio E (exit)
C = enlace peptídico
D = enlace éster
E = peptidil-ARNt (en el sitio P)
F = aminoacil-ARNt (en el sitio A)
G = subunidad ribosómica menor
H = extremo 3’ del ARN mensajero
7.- Interprete el esquema adjunto e indique el significado de los números y de las letras.

• Este esquema ilustra la fase de elongación. Se observa que la cadena peptídica consta de 5 aminoácidos y que ha tenido lugar un desplazamiento de la subunidad ribosómica mayor.
• Los números representan aminoácidos, de los cuales los 5 primeros ya están unidos.
• Partes marcadas con letras:
A = subunidad ribosómica menor
B = extremo 3’ del ARN mensajero
C = peptidil-ARNt (en el sitio P)
D = sitio A (que será ocupado por el siguiente aminoacil-ARNt cuando avance la subunidad menor para completar la translocación)
E = subunidad ribosómica mayor
F = enlace peptídico
G = enlace éster
H = ARNt saliente (que estaba unido al aminoácido nº 4), situado en el sitio E.
8.- Interprete el esquema adjunto e identifique las partes numeradas.

• Este esquema representa el comienzo de la fase de terminación. Cuando aparece en el ARNm un codón “stop” o sin sentido, que señala el fin de la traducción, el sitio A del ribosoma es ocupado por un factor proteico de terminación.
• Partes numeradas:
1 = ARN mensajero
2 = región que no se traduce (3’-UTR)
3 = extremo 3’ del ARNm
4 = factor de liberación o terminación, ocupando el sitio A
5 = enlace éster
6 = último aminoácido de la cadena sintetizada
7 = enlace peptídico
8 = peptidil-ARNt (alojado en el sitio P)
9 = sitio E
9.- ¿Qué representa el esquema adjunto? Identifique las partes numeradas.

• Este esquema representa la terminación de la traducción, que se caracteriza por la separación de los componentes que han intervenido en el proceso.
• Partes numeradas:
1 = subunidad ribosómica mayor
2 = cadena peptídica sintetizada
3 = enlace peptídico
4 = ARN transferente
5 = factor de liberación
6 = ARN mensajero
7 = subunidad ribosómica menor
10.- Cite la fase que representa el esquema adjunto. Nombre las partes numeradas. (Consulte el código genético).

• Este esquema representa el comienzo de la elongación.
• Partes numeradas:
1 = codón iniciador (5’-AUG-3’)
2 = extremo 5’ del ARNm
3 = extremo 3’ del ARNm
4 = ARNt iniciador portando el aminoácido metionina (eucariotas) o formilmetionina (procariotas).
5 = aminoacil-ARNt, concretamente, valil-ARNtV
6 = sitio P
7 = sitio A
8 = enlace tipo éster
9 = valina (según el codón 5’-GUU-3’)
10 = sitio o centro peptidil transferasa
11.- ¿Qué es el “centro peptidil transferasa”?
El sitio o centro peptidil transferasa es una cavidad de la subunidad ribosómica grande, en la cual se desarrolla la actividad catalítica de polimerización de aminoácidos, es decir, la formación de cada uno de los enlaces peptídicos, acción llevada a cabo por el llamado complejo enzimático peptidil transferasa.
Este complejo enzimático posee varios componentes proteicos, pero en la catálisis intervienen ribozimas integradas en el ARN ribosómico de la subunidad mayor, concretamente, el ARNr 28 S (eucariotas) o el ARNr 23 S (procariotas).
12.- ¿Cuáles son los diversos “sitios” que suelen considerarse en el ribosoma?
Se consideran los siguientes:
• Sitio A (aminoacilo o aceptor), donde entra el aminoacil-ARNt en cada ciclo de elongación.
• Sitio P (peptidilo o donador), en el cual se aloja el peptidil-ARNt.
• Sitio E (de eyección o salida), que está ocupado por el ARNt que ha quedado libre.
• Sitio peptidil transferasa, que se halla en la subunidad mayor, cerca del enlace que une los ARNt con su péptido y su aminoácido. En este sitio está localizado el complejo enzimático peptidil transferasa (cuya actividad catalítica reside en el ARN ribosómico).
13.- Interprete el esquema adjunto y nombre las partes numeradas.

• Este esquema ilustra la fase de elongación, justo después de formarse un enlace peptídico entre el aminoácido que estaba unido al ARNt del sitio P y el del sitio A.
• Partes numeradas:
1 = extremo 5’ del ARNm
2 = extremo 3’ del ARNm
3 = enlace por puente de hidrógeno
4 = ARNt iniciador sin el aminoácido que portaba
5 = dipeptidil-ARNt Val
6 = valina (según el codón 5’-GUU-3’)
7 = metionina (eucariotas) o formilmetionina (procariotas)
8 = enlace tipo éster
9 = enlace peptídico
10 = sitio o centro peptidil transferasa
14.- Interprete el esquema adjunto e identifique las partes numeradas.

• Este esquema ilustra la fase de elongación, observándose que ha tenido lugar la transposición (translocación), que se caracteriza por el avance del ribosoma tres nucleótidos en el ARNm, en el sentido 5’ —> 3’.
• Partes numeradas:
1 = ARNt iniciador libre o saliente (en este esquema no está representado el sitio E).
2 = codón iniciador
3 = extremo 5’ del ARNm
4 = extremo 3’ del ARNm
5 = segundo codón: 5’-GUU-3’
6 = sitio A libre (que instantes después será ocupado por el siguiente aminoacil-ARNt)
7 = dipeptidil-ARNt Val (Met-Val-ARNtV), alojado en el sitio P (antes de la translocación estaba en el sitio A)
8 = sitio del complejo enzimático peptidil transferasa
9 = enlace peptídico
10 = metionina (eucariotas) o formilmetionina (procariotas)
15.- Interprete el esquema adjunto y nombre las partes numeradas. (Consulte la clave genética).

• El esquema representa la fase de elongación. Se observa que el dipeptidil-ARNt está alojado en el sitio P y que el lugar A está ocupado por otro aminoacil-ARNt.
• Partes numeradas:
1 = codón iniciador: 5’-AUG-3’
2 = segundo codón: 5’-GUU-3’
3 = tercer codón: 5’-CAU-3
4 = extremo 3’ del ARNm
5 = dipeptidil-ARNt Val
6 = sitio P
7 = histidil-ARNtH
8 = sitio A
9 = enlace tipo éster
10 = histidina (según el codón 5’-CAU-3’)
11 = sitio o centro peptidil transferasa
12 = enlace peptídico
16.- Interprete el esquema adjunto y nombre las partes numeradas. (Consulte la tabla del código genético).

• Este esquema representa la fase de elongación. Se observa que el tripeptidil-ARNt está alojado en el sitio A y que el lugar P está ocupado por el ARNt cuyo aminoácido ha sido adicionado a la cadena peptídica que se está sintetizando. El tripeptidil-ARNt, cuando tenga lugar otra translocación, volverá a ocupar el sitio P.
• Partes numeradas:
1 = codón iniciador (5’-AUG-3’)
2 = extremo 3’ del ARNm
3 = ARNt específico de la valina (ARNtV)
4 = tripeptidil-ARNtH, concretamente: Met-Val-His-ARNtH.
5 = sitio o centro peptidil transferasa
6 = enlace tipo éster
7 = histidina (según el codón 5’-CAU-3’)
8 = valina (según el codón 5’-GUU-3’)
9 = metionina (según el codón 5’-AUG-3’)
17.- Escriba un comentario sobre el esquema adjunto e identifique las partes numeradas.

• Este esquema representa la primera fase de la traducción, concretamente, el comienzo de la iniciación. Se observa la unión de la subunidad ribosómica menor (40 S) con el ARN transferente iniciador, portador del primer aminoácido. Además, dicha subunidad interacciona con la caperuza del ARN mensajero.
• Partes numeradas:
1 = ARNt iniciador (con el anticodón 3’-UAC-5’)
2 = metionina (Met, M)
3 = subunidad ribosómica menor (40 S)
4 = ARN mensajero (ARNm)
5 = caperuza de metil guanosina trifosfato, propia de los ARN mensajeros eucarióticos (extremo 5’)
6 = codón iniciador (5’-AUG-3’)
7 = extremo 3’ del ARNm
Nota.- El proceso representado requiere factores de iniciación y aporte energético (GTP).
18.- Interprete el esquema adjunto e identifique las partes numeradas. ¿Qué aminoácidos estarían en las posiciones tercera y última? (Consulte el código genético).

• Este esquema corresponde a la fase de elongación. Se observa que ya se ha formado el enlace peptídico entre los dos primeros aminoácidos y que está teniendo lugar el desplazamiento del ribosoma (transposición, translocación), el cual avanza exactamente tres nucleótidos en el sentido 5’ --> 3’, si bien la subunidad mayor se mueve poco antes que la menor, proceso que requiere aporte energético (GTP) y un factor de elongación.
• Partes numeradas:
1 = metionina (codificada por el triplete AUG)
2 = treonina (codificada por el triplete ACU)
3 = liberación del ARNtMet desde el sitio E (exit)
4 = ARN mensajero eucariótico (con caperuza 5’)
5 = codón mudo o sin sentido (“stop” de la traducción)
6 = dipeptidil-ARNt (concretamente: Met-Thr-ARNtThr)
7 = sitio P, ocupado por el dipeptidil-ARNt
8 = sitio A, que será ocupado por el siguiente aminoacil-ARNt (no representado).
9 = subunidad ribosómica menor (40 S)
• El tercer aminoácido sería la fenilalanina, según el codón UUU. Esto pasaría cuando quede completada la transposición por el avance de la subunidad menor, de forma que el sitio A sea ocupado por el siguiente aminoacil- ARNt (fenilalanil-ARNtF).
• El último aminoácido de la cadena sintetizada sería la lisina, dado que el último codón (que antecede a la señal de “stop”) es AAA.
19.- ¿Qué representa el esquema adjunto? Nombre las partes numeradas. ¿Qué significado tienen las letras UAC?

• Este esquema representa el comienzo de la fase de iniciación, observándose que la subunidad ribosómica menor se ha asociado, en el sitio o lugar A, con el aminoacil-ARNt iniciador. Esta asociación requiere la intervención de un factor de iniciación y el aporte energético del GTP.
• Partes numeradas:
1 = sitio o lugar E
2 = sitio o lugar P
3 = sitio o lugar A
4 = ARNt iniciador “cargado” (aminoacil-ARNti)
5 = aminoácido iniciador: metionina (eucariotas) o formilmetionina (procariotas)
6 = enlace tipo éster
7 = factor de iniciación
• Las letras UAC representan el anticodón del ARNt iniciador, que posteriormente se emparejará con el codón AUG. Estos emparejamientos tienen carácter antiparalelo, por lo que la polaridad de los tripletes citados será: 3’-UAC-5’ y 5’-AUG-3’.
20.- Interprete el esquema adjunto indicando cómo se ha formado el conjunto representado. Nombre las partes numeradas.
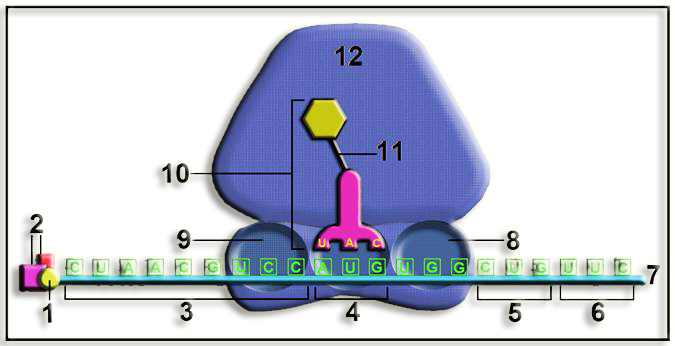
• La subunidad ribosómica menor, unida con el metionil-ARNt, interacciona con factores de iniciación y la caperuza del ARNm, desplazándose por esta cadena, con el aporte energético del ATP, hasta que el anticodón UAC reconoce al codón iniciador, AUG. Entonces se une la subunidad mayor constituyendo el conjunto denominado complejo de iniciación 80 S, que se mueve tres nucleótidos en el sentido 5’ --> 3’, de forma que el metionil-ARNt iniciador (que estaba en el sitio A) queda alojado en el sitio P. Se observa que en este preciso momento los sitios E y A están libres.
• Partes numeradas:
1 = caperuza 5’ del ARNm
2 = factores de iniciación
3 = región que no se traduce (5’-UTR o líder)
4 = codón iniciador (5’-AUG-3’), situado en el lugar P. Se observa que dicho triplete queda emparejado con el anticodón 3’-UAC-5’.
5 = codón 3º (5’-CUG-3’)
6 = codón 4º (5’-UUC-3’)
7 = extremo 3’ del ARNm
8 = sitio o lugar A
9 = sitio o lugar E
10 = aminoacil-ARNt, concretamente: metionil-ARNtM
11 = enlace tipo éster
12 = subunidad ribosómica mayor (60 S)
21.- Escriba un comentario sobre el esquema adjunto y nombre las partes numeradas. (Consulte el código genético).

• Este esquema representa la fase de elongación, observándose que los sitios E, P y A están ocupados por sendos ARNt. Los sucesivos aminoácidos que se van añadiendo a la cadena quedan unidos mediante un enlace peptídico (gracias a la acción del complejo enzimático peptidil transferasa). En este momento la cadena consta de 3 aminoácidos y está a punto de ser adicionado el 4º.
• Partes numeradas:
1 = caperuza 5’ del ARNm
2 = codón iniciador (5’-AUG-3’)
3 = región que no se traduce (5’-UTR o líder)
4 = extremo 3’ del ARNm
5 = tripeptidil-ARNt, concretamente: Met-Trp-Leu-ARNtLeu. Este ARNt ocupa el sitio P.
6 = aminoacil-ARNt, concretamente: fenilalanil-ARNtF. Ocupa el sitio A.
7 = enlace tipo éster
8 = fenilalanina (según el codón UUC)
9 = leucina (según el codón CUG)
10 = triptófano (según el codón UGG)
11 = metionina (según el codón AUG)
12 = enlace peptídico
13 = ARNtTrp libre o saliente, alojado en el sitio E (exit)
22.- ¿En qué consiste la transposición (o translocación)?
Consiste en el desplazamiento del ribosoma, que avanza exactamente 3 nucleótidos por el ARNm, en el sentido 5’à 3’. Las subunidades ribosómicas no se trasladan a la vez, sino que en primer lugar avanza la subunidad mayor y, seguidamente, la menor. Para ello se necesita un factor de elongación y el aporte energético del GTP.
La translocación provoca que el ARNt descargado del sitio P vaya al sitio E, y el ARNt portador del péptido en el sitio A, se mueva al P.
23.- ¿Es cierto que en determinados momentos el peptidil-ARNt ocupa el sitio A en lugar del sitio P? Justifique la respuesta.
Eso es cierto, pero justo antes de la translocación, pues el péptido del peptidil-ARNt (alojado en el sitio P) se transfiere al aminoacil-ARNt, que ocupa el sitio A. Cuando se completa el ciclo de elongación y tiene lugar la translocación, el peptidil-ARNt queda situado en el sitio P, dejando libre el sitio A para la entrada del siguiente aminoacil-ARNt.
24.- En un libro de 2º de Bachillerato aparece la ilustración adjunta. Escriba un comentario e indique qué representa el compuesto numerado (“1”). Haga un esquema del enlace que se ha formado.

• La biosíntesis de proteínas es inhibida por muchos antibióticos, uno de los cuales es la puromicina, que tiene una estructura similar a un aminoacil-ARNt, lo que le permite ocupar el sitio A de los ribosomas (procariotas y eucariotas).
Seguidamente, el complejo enzimático peptidil transferasa cataliza la transferencia de la cadena peptídica, no a otro aminoácido, sino a la puromicina, formando “peptidil-puromicina”, lo cual provoca la terminación prematura de la síntesis proteica.
• El compuesto marcado con el nº 1 se refiere al complejo peptidil-puromicina, que no al no poder adicionar nuevos aminoácidos determina la interrupción de la síntesis.
• Se ha formado un enlace peptídico al interaccionar el grupo amino de la puromicina con el carboxilo del último aminoácido del peptidil-ARNt sintetizado hasta ese momento.
Esquema:

25.- Interprete el esquema adjunto y nombre las partes numeradas (consulte la clave genética). ¿Qué significado tiene el triplete AAG?

• Este esquema representa el final de la elongación y el comienzo de la terminación. El ribosoma se desplaza por el ARNm, en sentido 5’à3’, hasta que encuentra un codón “stop” o sin sentido (en este caso, UAA). Entonces se incorpora en el sitio A un factor de terminación provocando que se detenga la síntesis de la cadena peptídica.
• Partes numeradas:
1 = subunidad ribosómica menor
2 = ARN mensajero
3 = extremo 3’ del ARNm
4 = ARNt saliente
5 = sitio E (exit)
6 = factor de liberación o terminación
7 = enlace peptídico
8 = histidina (penúltimo aminoácido, codificado por CAU)
9 = fenilalanina (último aminoácido, codificado por UUC)
• El triplete AAG es el anticodón del ARNtF, situado frente al codón UUC.
Recordemos que la interacción codón-anticodón tiene lugar por apareamiento antiparalelo, mediante la formación de enlaces por puente de hidrógeno (en este caso se formarían 7: dos entre cada par AU y tres entre GC).
En el sitio P se observa que el ARNtF es portador de la cadena sintetizada, conjunto que constituye el peptidil-ARNtF.
26.- Interprete el esquema adjunto y nombre las partes numeradas.

• Este esquema representa la terminación del proceso de la traducción, fase mediada por factores de liberación (ver nota), dando como resultado la separación de los componentes que han intervenido en dicho proceso. Las subunidades ribosómicas pueden reiniciar otro ciclo de traducción.
• Partes numeradas:
1 = ARN mensajero
2 = ARNt libre
3 = ARNt libre
4 = factor de liberación
5 = subunidad ribosómica mayor
6 = cadena peptídica sintetizada (suelen tener numerosos aminoácidos)
Nota.- Los factores de liberación se designan con las siglas RF (del inglés, release factor) y son los que interactúan con los codones de terminación (el RF1, con UAA o UAG, y el RF2, con UAA o UGA).
Asimismo, dichos factores inducen la liberación de la cadena peptídica, la cual abandona el ribosoma por medio de un túnel que atraviesa la subunidad grande y que comienza en la cavidad peptidil transferasa.
27.- ¿Son funcionales las cadenas peptídicas recién sintetizadas?
En general, los polipéptidos recién sintetizados no son funcionales, ya que deben adquirir la conformación tridimensional adecuada para desempeñar su actividad.
Las chaperonas son proteínas que posibilitan el plegamiento correcto de la cadena peptídica recién sintetizada.
La actuación de las chaperonas es importante puesto que, generalmente, las proteínas recién sintetizadas son incapaces por sí solas de alcanzar el plegamiento tridimensional para ser funcionales (conformación nativa).
Las chaperonas se descubrieron a finales de la década de 1970 y, actualmente, las más conocidas son aquellas cuya masa molecular se aproxima a 60 mil unidades de masa atómica, o sea, 60 kDa, que suelen designarse como chaperoninas.
Cabe advertir que las chaperoninas no son enzimas, pues no modifican covalentemente al sustrato con el que interaccionan, sino que actúan como moldes, facilitando que el polipéptido desplegado pueda alcanzar su estructura tridimensional nativa.
28.- ¿Son perdurables las proteínas celulares?
No, ya que la vida media de las proteínas varía desde unos minutos a varios días.
Las ciclinas, que regulan el ciclo celular, son degradadas rápidamente. Por el contrario, las tubulinas que forman los microtúbulos tienen una vida más larga.
La actividad celular requiere que todas las proteínas sean renovadas continuamente. A este respecto cabe señalar que, en las células procariotas, la velocidad de la síntesis proteica oscila en torno a 15 aminoácidos por segundo, siendo menor en las eucariotas, ya que se suelen adicionar de 2 a 5 aminoácidos por segundo.
Las proteínas más o menos defectuosas al término de su período funcional, así como las que muestran un plegamiento incorrecto, deben ser eliminadas para no interferir con el funcionamiento celular. En las células eucariotas, tal eliminación ocurre en los lisosomas y en los proteasomas.
29.- ¿Qué son los proteasomas (o proteosomas)?
Los proteasomas son agregados de múltiples subunidades proteicas, que delimitan una zona cilíndrica central, llamada cámara proteolítica, cuya función es degradar proteínas defectuosas o de vida corta, para lo cual se requiere el aporte energético del ATP.
Las proteínas que deben ser destruidas han sido previamente “ubiquitinadas”. La adición de varias moléculas de ubiquitina, un polipéptido de 76 aminoácidos, constituye la señal reconocible por los complejos moleculares de los proteasomas para introducirlas en la cámara proteolítica.
1.- ¿Cómo y cuándo se lleva a cabo la transmisión de la información genética?En los organismos pluricelulares, la transmisión de la información genética, se realiza en dos momentos del ciclo del individuo: cuando el individuo se reproduce y cuando el individuo crece. Cuando el individuo se reproduce, la información genética se transmite a los descendientes, y constituye lo que se conoce con el nombre de herencia biológica. Cuando se produce el crecimiento del individuo, las células se dividen mediante mitosis; también en este caso, se transmite la información genética completa a las células hijas que se obtienen. Tanto en un caso como en el otro, para que se pueda transmitir la información genética es necesario realizar una copia previa de esta. Este proceso; es decir, la realización de una copia del ADN, se denomina replicación o duplicación del ADN.
2.- ¿Qué es la transcripción?
La transcripción constituye la primera etapa que tiene lugar en el proceso de la expresión genética. Mediante este proceso, la información genética (secuencia de nucleótidos de un fragmento del ADN) se transforma en una secuencia de aminoácidos; es decir, en una proteína. La transcripción consiste, como su nombre indica, en copiar la información (secuencia de nucleótidos) de un fragmento del ADN, el correspondiente a un gen, en una molécula de ARN. En este proceso, por consiguiente, tomando como molde o patrón una de las cadenas del fragmento del ADN, se sintetiza una molécula de ARN, cuya secuencia de nucleótidos será complementaria con dicha cadena de ADN. En las células eucariotas, el proceso ocurre en el núcleo, mientras que en las células procariotas, debido a que no hay un núcleo definido, tiene lugar en el citoplasma. La transcripción es similar en eucariotas y en procariotas, aunque presenta algunas diferencias. Este proceso se realiza gracias a la acción de unos enzimas denominados ARN-polimerasas, que van uniendo ribonucleótidos mediante enlaces fosfodiéster en dirección 5' 3', de forma complementaria a los nucleótidos de la cadena del ADN patrón, y teniendo en cuenta que en el ARN no hay timina y la base complementaria de la adenina será el uracilo. En la síntesis de los ARNs se utilizan ribonucleótidos trifosfatos, que se hidrolizan y aportan la energía necesaria para formar los enlaces fosfodiéster. Como consecuencia de la transcripción, los ARNs que se obtienen se denominan ARNs transcritos primarios. En muchos casos sufrirán un proceso de maduración, mediante el cual se transforman en ARNs maduros (mensajeros, ribosómicos, transferentes), que intervendrán en la síntesis de proteínas.
La transcripción constituye la primera etapa que tiene lugar en el proceso de la expresión genética. Mediante este proceso, la información genética (secuencia de nucleótidos de un fragmento del ADN) se transforma en una secuencia de aminoácidos; es decir, en una proteína. La transcripción consiste, como su nombre indica, en copiar la información (secuencia de nucleótidos) de un fragmento del ADN, el correspondiente a un gen, en una molécula de ARN. En este proceso, por consiguiente, tomando como molde o patrón una de las cadenas del fragmento del ADN, se sintetiza una molécula de ARN, cuya secuencia de nucleótidos será complementaria con dicha cadena de ADN. En las células eucariotas, el proceso ocurre en el núcleo, mientras que en las células procariotas, debido a que no hay un núcleo definido, tiene lugar en el citoplasma. La transcripción es similar en eucariotas y en procariotas, aunque presenta algunas diferencias. Este proceso se realiza gracias a la acción de unos enzimas denominados ARN-polimerasas, que van uniendo ribonucleótidos mediante enlaces fosfodiéster en dirección 5' 3', de forma complementaria a los nucleótidos de la cadena del ADN patrón, y teniendo en cuenta que en el ARN no hay timina y la base complementaria de la adenina será el uracilo. En la síntesis de los ARNs se utilizan ribonucleótidos trifosfatos, que se hidrolizan y aportan la energía necesaria para formar los enlaces fosfodiéster. Como consecuencia de la transcripción, los ARNs que se obtienen se denominan ARNs transcritos primarios. En muchos casos sufrirán un proceso de maduración, mediante el cual se transforman en ARNs maduros (mensajeros, ribosómicos, transferentes), que intervendrán en la síntesis de proteínas.
3.- ¿Qué aportaciones realizó Severo Ochoa al descifrado del código genético?
evero Ochoa (1905-1993), médico y bioquímico español, fue uno de los pioneros en el descifrado del código genético. Su contribución a esta tarea fue el descubrimiento del enzima polinucleótido fosforilasa. Este enzima es capaz de sintetizar ARN a partir de ribonucleótidos, sin necesidad de un molde de ADN. Gracias a este enzima, se pudieron sintetizar cadenas de ARN con un solo tipo de ribonucleótido; una de ellas fue la cadena formada únicamente por uracilo (poli U); a partir de esta cadena, y en presencia de todos los aminoácidos, se obtenía un polipéptido formado únicamente por fenilalanina. De ello se deducía que el codón que codificaba la fenilalanina era el UUU. Este proceso se repitió posteriormente con otros ARNs formados por un solo nucleótido (A, C y G), así se dedujeron los aminoácidos codificados por los codones AAA, CCC y GGG. Con posterioridad, otros investigadores, como Kornberg y Khorana, descubrieron lo que codifican el resto de los codones que forman el código genético.
evero Ochoa (1905-1993), médico y bioquímico español, fue uno de los pioneros en el descifrado del código genético. Su contribución a esta tarea fue el descubrimiento del enzima polinucleótido fosforilasa. Este enzima es capaz de sintetizar ARN a partir de ribonucleótidos, sin necesidad de un molde de ADN. Gracias a este enzima, se pudieron sintetizar cadenas de ARN con un solo tipo de ribonucleótido; una de ellas fue la cadena formada únicamente por uracilo (poli U); a partir de esta cadena, y en presencia de todos los aminoácidos, se obtenía un polipéptido formado únicamente por fenilalanina. De ello se deducía que el codón que codificaba la fenilalanina era el UUU. Este proceso se repitió posteriormente con otros ARNs formados por un solo nucleótido (A, C y G), así se dedujeron los aminoácidos codificados por los codones AAA, CCC y GGG. Con posterioridad, otros investigadores, como Kornberg y Khorana, descubrieron lo que codifican el resto de los codones que forman el código genético.
4.- Dada la siguiente secuencia de nucleótidos del ARNm: AGC UAU AUG CGC ACG CAA ACC CCA AUU UAG AUA. a) Diga cuáles son los codones de iniciación y de terminación de esta secuencia, si es que presentan alguno. ¿Qué aminoácidos codifican estos codones? b) Esta secuencia, ¿podría dar lugar a un péptido? En caso afirmativo, ¿cuántos aminoácidos tendría? c) Si entre las bases subrayadas se introduce una adenina, ¿qué ocurriría en el péptido obtenido?
a) En esta secuencia el codón de iniciación es el AUG, que está ocupando el tercer lugar. Este codón codifica el aminoácido metionina, por ello, todas las proteínas en principio comienzan por este aminoácido; posteriormente, muchas de ellas lo eliminan. En esta secuencia el codón de terminación es el UAG, que se encuentra localizado en penúltimo lugar. Estos codones no codifican ningún aminoácido, por ello, se les denomina también codones mudos o sin sentido. Provocan la separación del ribosoma y el final de la síntesis proteica, ya que no existe ningún ARNt cuyo anticodón sea complementario con ellos.
a) En esta secuencia el codón de iniciación es el AUG, que está ocupando el tercer lugar. Este codón codifica el aminoácido metionina, por ello, todas las proteínas en principio comienzan por este aminoácido; posteriormente, muchas de ellas lo eliminan. En esta secuencia el codón de terminación es el UAG, que se encuentra localizado en penúltimo lugar. Estos codones no codifican ningún aminoácido, por ello, se les denomina también codones mudos o sin sentido. Provocan la separación del ribosoma y el final de la síntesis proteica, ya que no existe ningún ARNt cuyo anticodón sea complementario con ellos.
b) Esta secuencia daría lugar a un péptido que tendría siete aminoácidos. El primer aminoácido estaría codificado por el tercer codón, que es el de iniciación (AUG), y el último estaría codificado por el noveno codón (AUU), que es el anterior al codón de terminación. El péptido codificado sería el siguiente: H2N-Met - Arg - Thr - Gln - Thr - Pro - Ile-COOH
c) Si se adiciona una adenina entre las bases subrayadas, UAG AUA, la secuencia de nucleótidos en su extremo final se altera quedando de la siguiente manera: UAA GAU A. Por lo tanto se ha modificado el codón de terminación UAG y se ha transformado en el codón UAA. Esto no implica ningún cambio en el péptido, puesto que este nuevo codón también es un codón de terminación, con lo cual el péptido seguirá teniendo siete aminoácidos.
5.- ¿A qué se denomina sitio A y sitio P del ribosoma?
El ribosoma es la estructura celular encargada de leer los codones del ARNm, y de ir uniendo a ellos, temporalmente, los complejos aminoacil-ARNt, cuyos anticodones sean complementarios con el ARNm. Cada uno de estos aminoacil-ARNt aportará un determinado aminoácido, que posteriormente se unirán y formarán la proteína. El ribosoma consta de dos subunidades que, al inicio de la síntesis, se unen. En ellos se diferencian dos sitios o centros de unión, en donde los ARNt se unen mediante sus anticodones con los codones del ARNm. Estos sitios son: El sitio A o aminoacil. Es el lugar del ribosoma donde se van incorporando los nuevos aminoacil-ARNt. Aquí el aminoacil-ARNt se une por su anticodón con el correspondiente codón del ARNm. El sitio P o peptidil es el lugar del ribosoma donde se encuentran los peptidil-ARNt, es decir, los ARNt que están unidos a la cadena peptídica en formación con los codones del ARNm.
El ribosoma es la estructura celular encargada de leer los codones del ARNm, y de ir uniendo a ellos, temporalmente, los complejos aminoacil-ARNt, cuyos anticodones sean complementarios con el ARNm. Cada uno de estos aminoacil-ARNt aportará un determinado aminoácido, que posteriormente se unirán y formarán la proteína. El ribosoma consta de dos subunidades que, al inicio de la síntesis, se unen. En ellos se diferencian dos sitios o centros de unión, en donde los ARNt se unen mediante sus anticodones con los codones del ARNm. Estos sitios son: El sitio A o aminoacil. Es el lugar del ribosoma donde se van incorporando los nuevos aminoacil-ARNt. Aquí el aminoacil-ARNt se une por su anticodón con el correspondiente codón del ARNm. El sitio P o peptidil es el lugar del ribosoma donde se encuentran los peptidil-ARNt, es decir, los ARNt que están unidos a la cadena peptídica en formación con los codones del ARNm.
6.- ¿Cómo actúan las hormonas esteroides en el control de la expresión génica?
Las hormonas esteroides (estrógenos, corticoides, etc), debido a su carácter hidrófobo, pueden atravesar fácilmente la membrana plasmática por difusión y penetrar dentro de la célula. Una vez en el citoplasma se unen a proteínas receptoras específicas, formándose el complejo hormona-receptor , que es transportado hasta el núcleo a través de los poros de la membrana nuclear. Una vez en el núcleo, se fijan sobre un intensificador del ADN e inducen la transcripción de determinados genes.
Las hormonas esteroides (estrógenos, corticoides, etc), debido a su carácter hidrófobo, pueden atravesar fácilmente la membrana plasmática por difusión y penetrar dentro de la célula. Una vez en el citoplasma se unen a proteínas receptoras específicas, formándose el complejo hormona-receptor , que es transportado hasta el núcleo a través de los poros de la membrana nuclear. Una vez en el núcleo, se fijan sobre un intensificador del ADN e inducen la transcripción de determinados genes.
7.- Indica lo que representa el esquema que se escribe a continuación, señala los procesos que se representan en él y en qué lugares de la célula eucariota tienen lugar. ADN-ARN-- Proteína
Mediante este esquema se representa cómo fluye la información genética en una célula. Este flujo de la información genética constituye lo que se conoce como dogma central de la biología molecular, que fue enunciado por F. Crik en 1970. Según este esquema, se copia la información (secuencia de nucleótidos) de un fragmento del ADN en el ARNm. A este proceso se le denomina transcripción y, en las células eucariotas, tiene lugar en el núcleo. Posteriormente, este ARNm sale del núcleo y lleva la información hasta los ribosomas del citoplasma, los cuales la leen, traduciéndola en una secuencia de aminoácidos; es decir, en una cadena polipeptídica. En este proceso interviene también el ARNt, que se encarga de llevar los aminoácidos hasta los ribosomas y colocarlos en el orden que determina la secuencia de nucleótidos de ARNm.
Mediante este esquema se representa cómo fluye la información genética en una célula. Este flujo de la información genética constituye lo que se conoce como dogma central de la biología molecular, que fue enunciado por F. Crik en 1970. Según este esquema, se copia la información (secuencia de nucleótidos) de un fragmento del ADN en el ARNm. A este proceso se le denomina transcripción y, en las células eucariotas, tiene lugar en el núcleo. Posteriormente, este ARNm sale del núcleo y lleva la información hasta los ribosomas del citoplasma, los cuales la leen, traduciéndola en una secuencia de aminoácidos; es decir, en una cadena polipeptídica. En este proceso interviene también el ARNt, que se encarga de llevar los aminoácidos hasta los ribosomas y colocarlos en el orden que determina la secuencia de nucleótidos de ARNm.
8.- Señalar las principales diferencias en la síntesis del ARNm en las células eucariotas y en las procariotas.
Las principales diferencias son las siguientes: En las células procariotas, el enzima que cataliza la síntesis del ARNm es el mismo que cataliza la síntesis de los demás ARNs, mientras que en las células eucariotas hay un enzima específico para catalizar la síntesis de este ARNm,, este enzima esla ARN-polimerasa II. En las células eucariotas, cuando ya se han transcrito los treinta primeros nucleótidos, al extremo 5' del ARNm que se está formando, se le añade el nucleótido metil-guanosina trifosfato, que forma una especie de caperuza. Esta sirve para proteger este extremo de la acción de las nucleasas cuando el ARNm sale del núcleo. Esto no ocurre en las células procariotas. Otra diferencia es que en las células eucariotas, una vez que se ha formado el ARNm transcrito, por acción de la enzima poli-A polimerasa, se adiciona al extremo 3' de este compuesto un fragmento de unos doscientos nucleótidos de adenina que forma una cola denominada poli-A. Esta cola contribuye al transporte del ARNm fuera del núcleo. En las células procariotas, el ARNm que se transcribe no contiene intrones, es ya funcional y no necesita pasar por un proceso de maduración. En la células eucariotas, sin embargo, el ARNm transcrito no es funcional, contiene intrones y necesita pasar por un proceso de maduración, en el cual, mediante un proceso de corte y empalme, se eliminan los intrones y los exones se unen entre sí.
Las principales diferencias son las siguientes: En las células procariotas, el enzima que cataliza la síntesis del ARNm es el mismo que cataliza la síntesis de los demás ARNs, mientras que en las células eucariotas hay un enzima específico para catalizar la síntesis de este ARNm,, este enzima es
9.- ¿Es posible que, si se altera la secuencia de nucleótidos de un fragmento de ADN que lleva información para la síntesis de una proteína, no se vea afectada dicha proteína? ¿A qué es debido? Escribe un ejemplo.
Sí que es posible que se altere la secuencia de nucleótidos de un fragmento del ADN sin que ello implique una alteración en la secuencia de aminoácidos que forma la proteína. Esto es debido a que el código genético está degenerado y, por lo tanto, hay más codones que aminoácidos, existiendo codones diferentes para un mismo aminoácido. Estos codones difieren en la tercera base en la mayoría de los casos, aunque hay alguna excepción, como en el caso de los aminoácidos: leucina, serina y arginina, en los que no difieren en la tercera base sino en otras. Por consiguiente, si la alteración del ADN solo afecta a la base en que se diferencian los codones (generalmente la tercera base), no se alteraría la secuencia de aminoácidos, ya que se obtendría un codón sinónimo, que codificará el mismo aminoácido. Vamos a escribir un ejemplo de lo dicho anteriormente; primero escribimos una secuencia de ADN y el péptido que a partir de él se obtiene, y a continuación un ADN mutado de tal forma que el péptido siga siendo el mismo. En el ejemplo que se ha descrito las bases alteradas se han señalado subrayándolas. En este caso, a pesar de que en el ADN se han producido tres alteraciones, el péptido no se ha visto afectado. Mediante estas alteraciones se han obtenido tres codones sinónimos a los iniciales, que codificarán los mismos aminoácidos.
Sí que es posible que se altere la secuencia de nucleótidos de un fragmento del ADN sin que ello implique una alteración en la secuencia de aminoácidos que forma la proteína. Esto es debido a que el código genético está degenerado y, por lo tanto, hay más codones que aminoácidos, existiendo codones diferentes para un mismo aminoácido. Estos codones difieren en la tercera base en la mayoría de los casos, aunque hay alguna excepción, como en el caso de los aminoácidos: leucina, serina y arginina, en los que no difieren en la tercera base sino en otras. Por consiguiente, si la alteración del ADN solo afecta a la base en que se diferencian los codones (generalmente la tercera base), no se alteraría la secuencia de aminoácidos, ya que se obtendría un codón sinónimo, que codificará el mismo aminoácido. Vamos a escribir un ejemplo de lo dicho anteriormente; primero escribimos una secuencia de ADN y el péptido que a partir de él se obtiene, y a continuación un ADN mutado de tal forma que el péptido siga siendo el mismo. En el ejemplo que se ha descrito las bases alteradas se han señalado subrayándolas. En este caso, a pesar de que en el ADN se han producido tres alteraciones, el péptido no se ha visto afectado. Mediante estas alteraciones se han obtenido tres codones sinónimos a los iniciales, que codificarán los mismos aminoácidos.
10.- Al analizar el ADN de un organismo extraterrestre se ha observado que posee las mismas bases que el ADN de un organismo terrestre, si bien sus proteínas solo contienen dieciséis aminoácidos distintos. ¿Podría el código genético de estos organismos estar formado por parejas de nucleótidos? ¿Crees qué tendría alguna desventaja respecto al código genético de los organismos terrestres?
Como en estos organismos hay dieciséis aminoácidos diferentes, que forman sus proteínas, al menos tienen que existir dieciséis codones diferentes para que cada aminoácido esté determinado por un codón diferente. Por lo tanto, el código genético de estos organismos puede estar formado por parejas de nucleótidos, ya que con las cuatro bases que forman el ADN de estos organismos se pueden formar dieciséis parejas diferentes (variaciones con repetición de cuatro elementos tomados de dos en dos), que serán codones suficientes para codificar todos sus aminoácidos. A diferencia de lo que ocurre en los organismos terrestres, este código hipotético no estaría degenerado; cada aminoácido estaría codificado solamente por un codón; es decir, no habría codones sinónimos. Esto supondría una desventaja, puesto que cualquier alteración, por mínima que fuese, que se produjese en la secuencia de bases del ADN afectaría a la proteína que se sintetiza. Esto no ocurre en el caso de los organismos terrestres, ya que, debido a que el código está degenerado, aquellos cambios que hacen que los codones se transformen en sus sinónimos no producen alteraciones en la proteína que se sintetiza. Tampoco habrá codones sin sentido que indiquen el final, este se tendrá que determinar de otra forma distinta.
Como en estos organismos hay dieciséis aminoácidos diferentes, que forman sus proteínas, al menos tienen que existir dieciséis codones diferentes para que cada aminoácido esté determinado por un codón diferente. Por lo tanto, el código genético de estos organismos puede estar formado por parejas de nucleótidos, ya que con las cuatro bases que forman el ADN de estos organismos se pueden formar dieciséis parejas diferentes (variaciones con repetición de cuatro elementos tomados de dos en dos), que serán codones suficientes para codificar todos sus aminoácidos. A diferencia de lo que ocurre en los organismos terrestres, este código hipotético no estaría degenerado; cada aminoácido estaría codificado solamente por un codón; es decir, no habría codones sinónimos. Esto supondría una desventaja, puesto que cualquier alteración, por mínima que fuese, que se produjese en la secuencia de bases del ADN afectaría a la proteína que se sintetiza. Esto no ocurre en el caso de los organismos terrestres, ya que, debido a que el código está degenerado, aquellos cambios que hacen que los codones se transformen en sus sinónimos no producen alteraciones en la proteína que se sintetiza. Tampoco habrá codones sin sentido que indiquen el final, este se tendrá que determinar de otra forma distinta.
11.- ¿Qué son y cómo se forman los aminoacil-ARNt?
Los aminoacil-ARNt son complejos moleculares formados por un aminoácido y un ARNt específico al cual se une. Estos complejos se forman en el hialoplasma, en una fase previa a la traducción. De esta manera, los aminoácidos, que van a formar parte de las proteínas, son transportados hasta los ribosomas, donde se unirán en el orden que determinan los codones del ARNm. La formación de estos complejos se realiza gracias a la acción de unos enzimas específicos, llamados aminoacil-ARNt-sintetasas. Estos enzimas catalizan la unión entre un aminoácido y un ARNt, siempre que este posea un determinado anticodón, puesto que este triplete de nucleótidos del ARNt es lo que va a determinar con qué aminoácido se va a unir. La unión entre el aminoácido y el ARNt se produce mediante un enlace éster, que se forma entre el grupo carboxilo (-COOH) del aminoácido y el grupo -OH del extremo 3' del ARNt, localizado en el brazo aceptor. El extremo siempre finaliza en la secuencia CCA. Esta reacción es muy endergónica. La energía necesaria se obtiene de la hidrólisis del ATP, que se transforma en AMP y dos grupos fosfato.
Los aminoacil-ARNt son complejos moleculares formados por un aminoácido y un ARNt específico al cual se une. Estos complejos se forman en el hialoplasma, en una fase previa a la traducción. De esta manera, los aminoácidos, que van a formar parte de las proteínas, son transportados hasta los ribosomas, donde se unirán en el orden que determinan los codones del ARNm. La formación de estos complejos se realiza gracias a la acción de unos enzimas específicos, llamados aminoacil-ARNt-sintetasas. Estos enzimas catalizan la unión entre un aminoácido y un ARNt, siempre que este posea un determinado anticodón, puesto que este triplete de nucleótidos del ARNt es lo que va a determinar con qué aminoácido se va a unir. La unión entre el aminoácido y el ARNt se produce mediante un enlace éster, que se forma entre el grupo carboxilo (-COOH) del aminoácido y el grupo -OH del extremo 3' del ARNt, localizado en el brazo aceptor. El extremo siempre finaliza en la secuencia CCA. Esta reacción es muy endergónica. La energía necesaria se obtiene de la hidrólisis del ATP, que se transforma en AMP y dos grupos fosfato.
12.- ¿Por qué es necesario el control de la expresión genética y cuándo tiene lugar?
En el ADN de las células, tanto procariotas como eucariotas, se localiza toda la información genética que precisan para poder sintetizar sus proteínas. La expresión de esta información da lugar a las diferentes proteínas. La producción excesiva de proteínas resulta innecesaria y costosa energéticamente, y suele ocasionar alteraciones. Por todo ello, en los seres vivos se han desarrollado unos mecanismos que controlan la expresión génica de las células, permitiendo que los genes solo se expresen cuando sea necesario sintetizar la proteína que codifican. De esta manera, se evita el despilfarro molécular y energético. El control de la expresión génica es mucho más complejo y menos conocido en eucariotas que en procariotas, y se realiza principalmente en la transcripción.
En el ADN de las células, tanto procariotas como eucariotas, se localiza toda la información genética que precisan para poder sintetizar sus proteínas. La expresión de esta información da lugar a las diferentes proteínas. La producción excesiva de proteínas resulta innecesaria y costosa energéticamente, y suele ocasionar alteraciones. Por todo ello, en los seres vivos se han desarrollado unos mecanismos que controlan la expresión génica de las células, permitiendo que los genes solo se expresen cuando sea necesario sintetizar la proteína que codifican. De esta manera, se evita el despilfarro molécular y energético. El control de la expresión génica es mucho más complejo y menos conocido en eucariotas que en procariotas, y se realiza principalmente en la transcripción.
13.- ¿Qué es un gen?
Un gen es la unidad estructural y funcional de la herencia, que se transmite de padres a hijos a través de los gametos y que determina la aparición de una característica observable; es decir, el fenotipo. Durante mucho tiempo no se supo cuál era su naturaleza química, y se desconocía su localización; Mendel denominó a estas unidades factores hereditarios. Hoy se sabe que los genes son fragmentos de ADN, excepto en algunos virus que tienen como material genético ARN. Se localizan en los cromosomas, que es donde se encuentra el ADN. Los genes se expresan cuando la información que contienen se traduce en un proteína, que realizará una determinada función biológica. Su función es la de llevar la información necesaria para realizar las funciones celulares o su regulación.
Un gen es la unidad estructural y funcional de la herencia, que se transmite de padres a hijos a través de los gametos y que determina la aparición de una característica observable; es decir, el fenotipo. Durante mucho tiempo no se supo cuál era su naturaleza química, y se desconocía su localización; Mendel denominó a estas unidades factores hereditarios. Hoy se sabe que los genes son fragmentos de ADN, excepto en algunos virus que tienen como material genético ARN. Se localizan en los cromosomas, que es donde se encuentra el ADN. Los genes se expresan cuando la información que contienen se traduce en un proteína, que realizará una determinada función biológica. Su función es la de llevar la información necesaria para realizar las funciones celulares o su regulación.
14.- ¿Qué papel desempeña la ARN-polimerasa ?
La ARN-polimerasa es el enzima que se encarga de catalizar la síntesis de los ARNs, tomando como patrón el ADN. Este enzima realiza las siguientes funciones: Identifica y se une secuencias determinadas del ADN, llamadas secuencias promotoras, que indicarán dónde se inicia la transcripción y qué cadena del ADN se transcribe. Una vez fijado al ADN, produce un desenrollamiento de una vuelta de hélice. Va leyendo la secuencia de nucleótidos, de la cadena del ADN que se transcribe, en dirección 3' 5'. Va uniendo ribonucleótidos mediante enlaces fosfodiéster, haciéndolo en dirección 5' 3'. Estos ribonucleótidos que une serán complementarios con los nucleótidos de la cadena del ADN que se transcribe. (El complementario de la adenina, como en el ARN no hay timina, será el uracilo). Utiliza ribonucleótidos trifosfato que, antes de unirse, se hidrolizan, y, de esa forma, se obtiene la energía necesaría para formar el enlace.
15.- ¿Por qué decimos que el código genético está degenerado? ¿Representa esto alguna ventaja?
El código genético se dice que está degenerado porque hay más codones diferentes que aminoácidos y, por consiguiente, todos los aminoácidos, excepto el triptófano y la metionina, están codificados por más de un codón. A estos codones distintos, que determinan un mismo aminoácido, se les llama codones sinónimos. Además, hay tres codones que señalan el final de la síntesis (codones mudos), debido a que no codifican ningún aminoácido. El que el código genético esté degenerado se debe a que cada codón, como se ha demostrado experimentalmente, está formado por tres nucleótidos y, por consiguiente, con los cuatro nucleótidos posibles (A,G,C y U), el número de codones diferentes que puede existir es de 64, de los cuales 61 codifican aminoácidos. Esto quiere decir que hay muchos más codones que aminoácidos para codificar; por ello es por lo que un mismo aminoácido puede estar codificado por más de un codón. La degeneración del código genético no es un fallo del código, ya que cada secuencia de nucleótidos del ARNm solo se traduce en una determinada proteína, y constituye una ventaja, puesto que permite que, si se produce un cambio en un nucleótido (sustitución de un nucleótido por otro), en ocasiones no se traduce en una alteración en los aminoácidos de la proteína; es decir, este cambio puede dar lugar a la aparición de un codón sinónimo que codificaría el mismo aminoácido y, por consiguiente, la proteína no cambiaría.
El código genético se dice que está degenerado porque hay más codones diferentes que aminoácidos y, por consiguiente, todos los aminoácidos, excepto el triptófano y la metionina, están codificados por más de un codón. A estos codones distintos, que determinan un mismo aminoácido, se les llama codones sinónimos. Además, hay tres codones que señalan el final de la síntesis (codones mudos), debido a que no codifican ningún aminoácido. El que el código genético esté degenerado se debe a que cada codón, como se ha demostrado experimentalmente, está formado por tres nucleótidos y, por consiguiente, con los cuatro nucleótidos posibles (A,G,C y U), el número de codones diferentes que puede existir es de 64, de los cuales 61 codifican aminoácidos. Esto quiere decir que hay muchos más codones que aminoácidos para codificar; por ello es por lo que un mismo aminoácido puede estar codificado por más de un codón. La degeneración del código genético no es un fallo del código, ya que cada secuencia de nucleótidos del ARNm solo se traduce en una determinada proteína, y constituye una ventaja, puesto que permite que, si se produce un cambio en un nucleótido (sustitución de un nucleótido por otro), en ocasiones no se traduce en una alteración en los aminoácidos de la proteína; es decir, este cambio puede dar lugar a la aparición de un codón sinónimo que codificaría el mismo aminoácido y, por consiguiente, la proteína no cambiaría.
16.- A continuación se escribe la secuencia de nucleótidos de un fragmento de la cadena codificante del ADN: 3' AAG CAA TGT GGG CGG AGA CCA 5': a) Determinar la secuencia de nucleótidos del ARNm correspondiente e indicar su polaridad. b) Utilizando el código genético, determinar la secuencia de aminoácidos que produce la traducción de este ARNm. c) ¿Qué mínimo cambio tendría que ocurrir para que apareciese en cuarto lugar el aminoácido histidina en este péptido?
a) El ARNm, que se obtiene por transcripción de este fragmento de ADN, será complementario y antiparalelo con la hebra del ADN molde que se use. Por lo tanto, la secuencia de nucleótidos y la polaridad del fragmento de ARNm será la siguiente: Hebra de ADN molde 3' AAG CAA TGT GGG CGG AGA CCA 5'. RNA 5' UUC GUU ACA CCC GCC UCU GGU 3'.
a) El ARNm, que se obtiene por transcripción de este fragmento de ADN, será complementario y antiparalelo con la hebra del ADN molde que se use. Por lo tanto, la secuencia de nucleótidos y la polaridad del fragmento de ARNm será la siguiente: Hebra de ADN molde 3' AAG CAA TGT GGG CGG AGA CCA 5'. RNA 5' UUC GUU ACA CCC GCC UCU GGU 3'.
b) La secuencia de aminoácidos que determina este ARNm será la siguiente: H2N-Phe - Val - Thr - Pro - Ala - Ser - Gly-COOH.
c) Para que en esta secuencia de aminoácidos apareciese en el cuarto lugar el aminoácido histidina en lugar de prolina, tendría que modificarse el codón CCC que codifica el aminoácido prolina por alguno de los que codifica el aminoácido histidina, que son: CAU y CAC. Por lo tanto, el mínimo cambio que tendría que producirse sería el de sustituir la citosina, que ocupa el segundo lugar en el codón CCC por la base adenina, con lo cual el codón CCC se convertiría en CAC. Por consiguiente, en el ADN se tendría que sustituir una base por otra: en este caso, se sustituiría una base púrica (guanina) por una pirimidínica (timina); a esta mutación se la denomina transversión. Según todo lo dicho, nos quedaría: Sin mutación: ADN: 3'AAG CAA TGT GGG CGG AGA CCA 5'. ARNm 5'UUC GUU ACA CCC GCC UCU GGU 3'. Péptido: H2N-Phe -Val -Thr -Pro -Ala -Ser -Gly-COOH. Con mutación: ADN: 3'AAG CAA TGT GTG CGG AGA CCA 5'. ARNm: 5'UUC GUU ACA CAC GCC UCU GGU 3'. Péptido: H2N-Phe -Val -Thr -His -Ala -Ser -Gly-COOH.
17.- ¿Es cierto que en las células eucariotas todas las proteínas tienen el aminoácido metionina en el extremo N-terminal?
En principio, sí que es cierto que todas las proteínas de las células eucariotas recién sintetizadas, comienzan por el aminoácido metionina; esto es debido a que el codón de iniciación, que será el primer codón que lee el ribosoma en las células eucariotas, es AUG, por lo que el primer. aminoacil-ARNt que llega al sitio A será aquel cuyo anticodón es UAC, es decir, será el ARNt-metionina. Posteriormente, en muchos casos este primer aminoácido se elimina, por lo que no siempre el primer aminoácido de las proteínas eucariotas es la metionina.
En principio, sí que es cierto que todas las proteínas de las células eucariotas recién sintetizadas, comienzan por el aminoácido metionina; esto es debido a que el codón de iniciación, que será el primer codón que lee el ribosoma en las células eucariotas, es AUG, por lo que el primer. aminoacil-ARNt que llega al sitio A será aquel cuyo anticodón es UAC, es decir, será el ARNt-metionina. Posteriormente, en muchos casos este primer aminoácido se elimina, por lo que no siempre el primer aminoácido de las proteínas eucariotas es la metionina.
18.- Explica cómo funciona el operón lac o sistema de regulación inducible.
El modelo operón de regulación de la expresión génica puede ser de dos tipos: inducible y represible, según se trate de una ruta catabólica o anabólica. El operón lactosa u operón lac de E.coli es un sistema de regulación inducible. Este sistema de regulación interviene en el catabolismo de la lactosa. La bacteria (E.coli), cuando se encuentra en un medio rico en lactosa y pobre en glucosa, utiliza la lactosa como fuente de carbono. En el catabolismo de la lactosa intervienen tres enzimas: -galactosidasa, permeasa y transacetilasa. Estos enzimas están codificados por tres genes estructurales contiguos, que se sitúan a continuación del operador. Si hay glucosa en el medio, el gen regulador se transcribe y produce la proteína represora, que tiene dos lugares de unión: uno de ellos sirve para unirse al operador y bloquearlo, impidiendo quela ARN-pol se una al promotor, y, por lo tanto, no se produce la transcripción de los genes estructurales. El otro lugar de unión sirve para que, cuando no hay glucosa, la lactosa se una a la proteína represora, altere su configuración y haga que se desprenda del operador, permitiendo que se transcriban los genes estructurales y se sinteticen los enzimas que catabolizan la lactosa.
El modelo operón de regulación de la expresión génica puede ser de dos tipos: inducible y represible, según se trate de una ruta catabólica o anabólica. El operón lactosa u operón lac de E.coli es un sistema de regulación inducible. Este sistema de regulación interviene en el catabolismo de la lactosa. La bacteria (E.coli), cuando se encuentra en un medio rico en lactosa y pobre en glucosa, utiliza la lactosa como fuente de carbono. En el catabolismo de la lactosa intervienen tres enzimas: -galactosidasa, permeasa y transacetilasa. Estos enzimas están codificados por tres genes estructurales contiguos, que se sitúan a continuación del operador. Si hay glucosa en el medio, el gen regulador se transcribe y produce la proteína represora, que tiene dos lugares de unión: uno de ellos sirve para unirse al operador y bloquearlo, impidiendo que
19.- ¿Quién enunció la hipótesis un gen, un enzima ? ¿Qué dice dicha hipótesis?
El médico inglés Garrod, en la primera década del siglo XX descubrió que una enfermedad metabólica, la alcaptonuria, caracterizada entre otras cosas porque los individuos eliminan orina negra debido a la eliminación de ácido homogentísico, era causada por una anomalía hereditaria. Supuso que los enfermos carecían del enzima que metaboliza el ácido homogentísico. Fue la primera vez que se relacionó un gen con un enzima. En los años cuarenta, G. Beadle y E. Tatum, en experiencias realizadas con el moho Neuroespora crassa, estudiaron las consecuencias de los cambios génicos o mutaciones. Comprobaron que la alteración en un gen suponía una variación fenotípica, que consistía en el fallo en el funcionamiento de un enzima. Propusieron la hipótesis de un gen, un enzima. Según esta hipótesis, cada gen, que es un fragmento de ADN, lleva la información necesaria para la síntesis de una proteína enzimática. Posteriormente, esta hipótesis ha sido modificada, reformulándose como un gen, un polipéptido. Esto se ha debido a que muchas proteínas no son enzimas, y a que muchas proteínas están formadas por más de una cadena polipeptídica, cada una de las cuales está codificada por un fragmento de ADN. Hoy se sabe que muchos genes no se expresan, y algunos regulan la expresión.
El médico inglés Garrod, en la primera década del siglo XX descubrió que una enfermedad metabólica, la alcaptonuria, caracterizada entre otras cosas porque los individuos eliminan orina negra debido a la eliminación de ácido homogentísico, era causada por una anomalía hereditaria. Supuso que los enfermos carecían del enzima que metaboliza el ácido homogentísico. Fue la primera vez que se relacionó un gen con un enzima. En los años cuarenta, G. Beadle y E. Tatum, en experiencias realizadas con el moho Neuroespora crassa, estudiaron las consecuencias de los cambios génicos o mutaciones. Comprobaron que la alteración en un gen suponía una variación fenotípica, que consistía en el fallo en el funcionamiento de un enzima. Propusieron la hipótesis de un gen, un enzima. Según esta hipótesis, cada gen, que es un fragmento de ADN, lleva la información necesaria para la síntesis de una proteína enzimática. Posteriormente, esta hipótesis ha sido modificada, reformulándose como un gen, un polipéptido. Esto se ha debido a que muchas proteínas no son enzimas, y a que muchas proteínas están formadas por más de una cadena polipeptídica, cada una de las cuales está codificada por un fragmento de ADN. Hoy se sabe que muchos genes no se expresan, y algunos regulan la expresión.
20.- ¿Qué son las secuencias promotoras?
Las secuencias promotoras, también denominadas centros promotores, son ciertas secuencias de nucleótidos localizados en distintos lugares de una u otra cadena del ADN patrón. Señalan el lugar de unión dela ARN-polimerasa , y su función es indicar dónde se inicia la transcripción y cuál de las dos hebras del ADN se transcribe. En las células procariotas existen dos centros promotores, situados a distinta distancia del lugar de inicio de la transcripción; estos centros son: El primero, cuya secuencia de bases es TTGACA, se localiza unos treinta y cinco nucleótidos antes del punto de inicio de la transcripción. El segundo se sitúa diez nucleótidos antes del punto de inicio, y su secuencia de bases es TATAAT. En las células eucariotas también existen centros promotores; los más frecuentes son dos, que tienen las siguientes secuencias: TATA y CAAT. Se localizan unos veinticinco nucleótidos antes del inicio de la transcripción.
Las secuencias promotoras, también denominadas centros promotores, son ciertas secuencias de nucleótidos localizados en distintos lugares de una u otra cadena del ADN patrón. Señalan el lugar de unión de
21.- Define los siguientes términos: Codón. Codón sinónimo. Codón sin sentido. Codón de inicio.
Codón. Es cada uno de los tripletes de nucleótidos que forman el ARNm. Existen 64 codones distintos que constituyen el código genético. Cada uno de estos codones, excepto tres, codifican un aminoácido. Ejemplo: UUU codifica para fenilalanina. Codón sinónimo. Son aquellos codones diferentes que codifican el mismo aminoácido. Existen estos codones porque hay más tripletes de nucleótidos que aminoácidos, por ello, todos los aminoácidos, excepto la metionina y el triptófano, están codificados por más de un codón. Estos codones, en la mayoría de los casos, solo difieren en un nucleótido, generalmente el tercero, aunque hay excepciones. Por ejemplo, los codones CCU y CCC son sinónimos, ambos codifican la prolina; en este caso solo difieren en el tercer nucleótido, lo que suele ser lo más frecuente. Los codones CUG y UUA también son sinónimos, ya que codifican el mismo aminoácido, la leucina; en este caso, difieren en más de un nucleótido. Codón sin sentido. También denominado codón mudo; es un codón que no codifica ningún aminoácido. En el código genético existen tres codones mudos: UAA, UAG y UGA. Estos codones son importantes porque indican el final de la síntesis de proteínas. Codón de inicio. Es el codón con el que siempre se inicia la síntesis de proteínas; este codón, en las células eucariotas, es AUG, que codifica el aminoácido metionina. Por ello, y en principio, todas las proteínas comenzarían por este aminoácido, si bien posteriormente muchas de ellas lo eliminan.
Codón. Es cada uno de los tripletes de nucleótidos que forman el ARNm. Existen 64 codones distintos que constituyen el código genético. Cada uno de estos codones, excepto tres, codifican un aminoácido. Ejemplo: UUU codifica para fenilalanina. Codón sinónimo. Son aquellos codones diferentes que codifican el mismo aminoácido. Existen estos codones porque hay más tripletes de nucleótidos que aminoácidos, por ello, todos los aminoácidos, excepto la metionina y el triptófano, están codificados por más de un codón. Estos codones, en la mayoría de los casos, solo difieren en un nucleótido, generalmente el tercero, aunque hay excepciones. Por ejemplo, los codones CCU y CCC son sinónimos, ambos codifican la prolina; en este caso solo difieren en el tercer nucleótido, lo que suele ser lo más frecuente. Los codones CUG y UUA también son sinónimos, ya que codifican el mismo aminoácido, la leucina; en este caso, difieren en más de un nucleótido. Codón sin sentido. También denominado codón mudo; es un codón que no codifica ningún aminoácido. En el código genético existen tres codones mudos: UAA, UAG y UGA. Estos codones son importantes porque indican el final de la síntesis de proteínas. Codón de inicio. Es el codón con el que siempre se inicia la síntesis de proteínas; este codón, en las células eucariotas, es AUG, que codifica el aminoácido metionina. Por ello, y en principio, todas las proteínas comenzarían por este aminoácido, si bien posteriormente muchas de ellas lo eliminan.
22.- ¿Habrá más de una secuencia de ADN que codifique el péptido cuya secuencia de aminoácidos es: H2N-Met-His-Ser-Trp-Gly-COOH?
Sí que hay más de una secuencia de nucleótidos de ADN diferente que codifica el mismo péptido. Esto se debe a que todos los aminoácidos excepto dos, la metionina y el triptófano, están codificados por más de un codón, y, por lo tanto, el triplete de nucleótidos que forma el ADN puede ser cualquiera de los que codifica el aminoácido en cuestión. En el caso del péptido del enunciado, el número de secuencias diferentes que lo codifican será el siguiente: Metionina: solo lo determina un codón: AUG. Histidina: los codones que lo codifican son: CAU, CAC. Serina: los codones que lo determinan son: UCU, UCC, UCA, UCG, AGU, AGC. Triptófano: solo lo codifica el codón: UGG. Glicina: los codones que lo codifican son: GGU, GGC, GGA, GGG. Según esto, el número de ARNm que lleva la información para sintetizar este péptido será: N de ARNm = 1 x 2 x 6 x 1 x 4 = 48. Cada uno de los ARNm se obtiene por transcripción de una de las cadenas del fragmento del ADN, por lo tanto, el número de secuencias de ADN diferentes que codifican este péptido será también 48. Algunos de estos 48 ARNm son los siguientes: 5'AUG CAU UCU UGG GGU 3'. 5'AUG CAC UCU UGG GGU 3'. 5'AUG CAU UCC UGG GGU 3'. 5'AUG CAU UCC UGG GGG 3'. 5'AUG CAC UCG UGG GGA 3'. Los ADNS que, por transcripción. han dado estos ARNm son los siguientes: 3'TAC GTA AGA ACC CCA 5'. 3'TAC GTG AGA ACC CCA 5'. 3'TAC GTA AGG ACC CCA 5'. 3'TAC GTA AGG ACC CCC 5'. 3'TAC GTG AGC ACC CCT 5'
Sí que hay más de una secuencia de nucleótidos de ADN diferente que codifica el mismo péptido. Esto se debe a que todos los aminoácidos excepto dos, la metionina y el triptófano, están codificados por más de un codón, y, por lo tanto, el triplete de nucleótidos que forma el ADN puede ser cualquiera de los que codifica el aminoácido en cuestión. En el caso del péptido del enunciado, el número de secuencias diferentes que lo codifican será el siguiente: Metionina: solo lo determina un codón: AUG. Histidina: los codones que lo codifican son: CAU, CAC. Serina: los codones que lo determinan son: UCU, UCC, UCA, UCG, AGU, AGC. Triptófano: solo lo codifica el codón: UGG. Glicina: los codones que lo codifican son: GGU, GGC, GGA, GGG. Según esto, el número de ARNm que lleva la información para sintetizar este péptido será: N de ARNm = 1 x 2 x 6 x 1 x 4 = 48. Cada uno de los ARNm se obtiene por transcripción de una de las cadenas del fragmento del ADN, por lo tanto, el número de secuencias de ADN diferentes que codifican este péptido será también 48. Algunos de estos 48 ARNm son los siguientes: 5'AUG CAU UCU UGG GGU 3'. 5'AUG CAC UCU UGG GGU 3'. 5'AUG CAU UCC UGG GGU 3'. 5'AUG CAU UCC UGG GGG 3'. 5'AUG CAC UCG UGG GGA 3'. Los ADNS que, por transcripción. han dado estos ARNm son los siguientes: 3'TAC GTA AGA ACC CCA 5'. 3'TAC GTG AGA ACC CCA 5'. 3'TAC GTA AGG ACC CCA 5'. 3'TAC GTA AGG ACC CCC 5'. 3'TAC GTG AGC ACC CCT 5'
23.- Explicar cómo finaliza la síntesis proteica.
La síntesis proteica finaliza cuando, tras la última translocación del ribosoma, alguno de los codones de terminación llega al sitio A del ribosoma. Estas señales de terminación pueden ser: UAA, UGA y UAG, y son codones que no codifican ningún aminoácido. Por lo tanto, no habrá ningún ARNt cuyo anticodón sea complementario con ellos, y, por consiguiente, cuando esto ocurre, no entrará ningún aminoacil-ARNt al sitio A. Estos codones de terminación son reconocidos y se unen a un factor de liberación, que puede ser el FR1 o el FR2. Dicha unión activa la enzima peptidil-transferasa que, en este caso, produce lo siguiente: Hidroliza la unión entre el ARNt y la cadena peptídica recién formada. Esta abandona el ribosoma, quedando libre. Hace que abandonen el ribosoma el ARNt y el ARNm. Este último, al poco de abandonar el ribosoma, es destruido. Provoca la separación de las dos subunidades del ribosoma. En esta etapa también se requiere energía, que se obtiene de la hidrólisis del GTP.
La síntesis proteica finaliza cuando, tras la última translocación del ribosoma, alguno de los codones de terminación llega al sitio A del ribosoma. Estas señales de terminación pueden ser: UAA, UGA y UAG, y son codones que no codifican ningún aminoácido. Por lo tanto, no habrá ningún ARNt cuyo anticodón sea complementario con ellos, y, por consiguiente, cuando esto ocurre, no entrará ningún aminoacil-ARNt al sitio A. Estos codones de terminación son reconocidos y se unen a un factor de liberación, que puede ser el FR1 o el FR2. Dicha unión activa la enzima peptidil-transferasa que, en este caso, produce lo siguiente: Hidroliza la unión entre el ARNt y la cadena peptídica recién formada. Esta abandona el ribosoma, quedando libre. Hace que abandonen el ribosoma el ARNt y el ARNm. Este último, al poco de abandonar el ribosoma, es destruido. Provoca la separación de las dos subunidades del ribosoma. En esta etapa también se requiere energía, que se obtiene de la hidrólisis del GTP.
24.- Si en los organismos pluricelulares todas las células tienen el mismo ADN, ¿por qué tienen distintas formas y funciones?
En los seres pluricelulares, todas las células tienen la misma información genética; es decir, el mismo ADN, ya que todas las células se forman mediante divisiones mitóticas sucesivas, a partir de una célula inicial. Por consiguiente, todas las células deberían ser iguales y realizar las mismas funciones; sin embargo, no es así; en estos seres aparecen grupos de células que adquieren una determinada forma y se especializan en realizar una determinada función. A estos grupos de células se les denomina tejidos. La diferenciación celular, que ocurre en estos seres vivos y que da lugar a los diferentes tejidos, es otra consecuencia de la regulación de la expresión genética. La diferenciación celular se produce porque, aunque todas las células de un organismo pluricelular tienen el mismo ADN, es decir, los mismos genes, estos no se expresan en todas por igual; en algunas células se expresan unos genes y se reprimen otros, mientras que en otras células son genes diferentes los que se expresan y se reprimen. Así por ejemplo, los genes de la hemoglobina solo se expresan en los eritrocitos, los de la melanina, únicamente en las células dérmicas, etc. Estos genes, en otras células que no sean estas, estarán reprimidos.
En los seres pluricelulares, todas las células tienen la misma información genética; es decir, el mismo ADN, ya que todas las células se forman mediante divisiones mitóticas sucesivas, a partir de una célula inicial. Por consiguiente, todas las células deberían ser iguales y realizar las mismas funciones; sin embargo, no es así; en estos seres aparecen grupos de células que adquieren una determinada forma y se especializan en realizar una determinada función. A estos grupos de células se les denomina tejidos. La diferenciación celular, que ocurre en estos seres vivos y que da lugar a los diferentes tejidos, es otra consecuencia de la regulación de la expresión genética. La diferenciación celular se produce porque, aunque todas las células de un organismo pluricelular tienen el mismo ADN, es decir, los mismos genes, estos no se expresan en todas por igual; en algunas células se expresan unos genes y se reprimen otros, mientras que en otras células son genes diferentes los que se expresan y se reprimen. Así por ejemplo, los genes de la hemoglobina solo se expresan en los eritrocitos, los de la melanina, únicamente en las células dérmicas, etc. Estos genes, en otras células que no sean estas, estarán reprimidos.
25.- Enumera los distintos experimentos llevados a cabo que han demostrado que el ADN es la molécula portadora de la información genética.
El descubrimiento de que el ADN era la molécula portadora de la información genética ha sido uno de los grandes descubrimientos de la biología en siglo XX. Los principales acontecimientos que han conducido hasta esta conclusión han sido los siguientes: En1869, F . Miecher descubrió los ácidos nucleicos. Los denominó nucleína , porque estaban presentes en el núcleo de las células. Posteriormente, se descubrió que los cromosomas de las células eucariotas estaban formados por ADN y proteínas. A comienzos de este siglo, se descartó que el ADN fuese el portador de la información genética por su aparente simplicidad. Se creía que la información la portaban las proteínas. En 1928, el bacteriólogo F. Griffith realizó experimentos con la bacteria Streptococcus pneumoniae, causante de la neumonía humana. De esta bacteria existen dos cepas distintas: la cepa S (formada por células capsuladas, que es virulenta) y la cepa R (formada por células no capsuladas, que no es virulenta). A partir de estas bacterias, Griffith demostró que la cepa R adquiría la capacidad de producir cápsula (que es lo que determina la virulencia), gracias una sustancia no identificada, denominada principio transformante, procedente de las bacterias S. En la década de los cuarenta, O.T. Avery, C. MacLeod y M. McCarty obtuvieron distintas moléculas de las bacterias S (virulentas) muertas y observaron si transformaban las bacterias R (no virulentas). Comprobaron que el principio transformante, que modificaba las bacterias R y las hacia producir cápsula, era el ADN. En1952, A .D. Hershey y M. Chase demostraron de forma concluyente que el ADN, y no una proteína del fago T2, es la molécula portadora de la información genética, que se introduce en la bacteria para la reproducción viral. En 1953, J. Watson y F. Crick mostraron el modelo de doble hélice, que explicaba cómo se almacenaba y transmitía la información genética. Hoy ya nadie duda de la función e importancia del ADN.
El descubrimiento de que el ADN era la molécula portadora de la información genética ha sido uno de los grandes descubrimientos de la biología en siglo XX. Los principales acontecimientos que han conducido hasta esta conclusión han sido los siguientes: En
26.- ¿Cómo se produce la fase de maduración en los ARN mensajeros?
La fase de maduración es la última etapa del proceso de transcripción. En ella, los ARNs transcritos sufren una serie de cambios, mediante los cuales se transforman en los ARNs maduros y funcionales. En las células procariotas, debido a que los genes son continuos, el ARNm que se obtiene por transcripción del ADN ya es funcional, sin necesidad de sufrir ningún proceso de maduración. En las células eucariotas, debido a que los genes no son continuos, sino que poseen fragmentos con información denominados exones, entre los que hay intercalados otros fragmentos carentes de información llamados intrones. Por esta razón, los ARNm transcritos tienen que pasar por un proceso de maduración, mediante el cual se eliminan los intrones y el ARNm transcrito se transforma en ARNm funcional. Esta eliminación se realiza mediante un proceso de corte y empalme, en el cual se cortan los intrones y los exones se unen entre sí. El proceso se realiza gracias a la acción de unos enzimas llamados ribonucleoproteínas pequeñas nucleolares (RNPpn) o espliceosoma.
La fase de maduración es la última etapa del proceso de transcripción. En ella, los ARNs transcritos sufren una serie de cambios, mediante los cuales se transforman en los ARNs maduros y funcionales. En las células procariotas, debido a que los genes son continuos, el ARNm que se obtiene por transcripción del ADN ya es funcional, sin necesidad de sufrir ningún proceso de maduración. En las células eucariotas, debido a que los genes no son continuos, sino que poseen fragmentos con información denominados exones, entre los que hay intercalados otros fragmentos carentes de información llamados intrones. Por esta razón, los ARNm transcritos tienen que pasar por un proceso de maduración, mediante el cual se eliminan los intrones y el ARNm transcrito se transforma en ARNm funcional. Esta eliminación se realiza mediante un proceso de corte y empalme, en el cual se cortan los intrones y los exones se unen entre sí. El proceso se realiza gracias a la acción de unos enzimas llamados ribonucleoproteínas pequeñas nucleolares (RNPpn) o espliceosoma.
27.- ¿Por qué los codones que forman el código genético tienen que estar formados por tres nucleótidos?
Quien primero propuso que los codones que forman el código genético debían estar formados por tripletes de nucleótidos fue el físico estadounidense G. Gamow, el mismo que enunció la hipótesis del Big- Bang acerca del origen del universo. El razonamiento por el que los codones tienen que ser tripletes de nucleótidos es el siguiente: Si cada codón estuviese formado por un solo nucleótido, únicamente habría cuatro codones diferentes, y no serían suficientes para que codones diferentes pudiesen codificar los veinte aminoácidos proteicos. Esto implicaría que un mismo codón tendría que codificar más de un aminoácido, lo cual significaría que una determinada información se pudiese traducir de más de una manera; es decir, una misma información podría dar lugar a más de una proteína. Si cada codón estuviese formado por dos nucleótidos, el número de codones diferentes que se podría formar con los cuatro nucleótidos que forman el ARN, serían 16 (variaciones con repetición de cuatro elementos tomados de dos en dos), los cuales siguen siendo insuficientes para poder codificar a los veinte aminoácidos proteicos; se plantearía el mismo problema que en el caso anterior. Si los codones estuviesen formados por tres nucleótidos, el número de codones diferentes que se pueden formar con los cuatro nucleótidos es de 64 (variaciones con repetición de cuatro elementos tomados de tres en tres), que serán suficientes para poder codificar todos los aminoácidos proteicos. Como hay más codones que aminoácidos, una mayoría va a estar codificada por más de un codón; además, pueden quedar codones que no codificarían ningún aminoácido e indicarían el final de la síntesis. Posteriormente, Crik, utilizando mutágenos, demostró que los codones del código genético están formados por tripletes de nucleótidos.
Quien primero propuso que los codones que forman el código genético debían estar formados por tripletes de nucleótidos fue el físico estadounidense G. Gamow, el mismo que enunció la hipótesis del Big- Bang acerca del origen del universo. El razonamiento por el que los codones tienen que ser tripletes de nucleótidos es el siguiente: Si cada codón estuviese formado por un solo nucleótido, únicamente habría cuatro codones diferentes, y no serían suficientes para que codones diferentes pudiesen codificar los veinte aminoácidos proteicos. Esto implicaría que un mismo codón tendría que codificar más de un aminoácido, lo cual significaría que una determinada información se pudiese traducir de más de una manera; es decir, una misma información podría dar lugar a más de una proteína. Si cada codón estuviese formado por dos nucleótidos, el número de codones diferentes que se podría formar con los cuatro nucleótidos que forman el ARN, serían 16 (variaciones con repetición de cuatro elementos tomados de dos en dos), los cuales siguen siendo insuficientes para poder codificar a los veinte aminoácidos proteicos; se plantearía el mismo problema que en el caso anterior. Si los codones estuviesen formados por tres nucleótidos, el número de codones diferentes que se pueden formar con los cuatro nucleótidos es de 64 (variaciones con repetición de cuatro elementos tomados de tres en tres), que serán suficientes para poder codificar todos los aminoácidos proteicos. Como hay más codones que aminoácidos, una mayoría va a estar codificada por más de un codón; además, pueden quedar codones que no codificarían ningún aminoácido e indicarían el final de la síntesis. Posteriormente, Crik, utilizando mutágenos, demostró que los codones del código genético están formados por tripletes de nucleótidos.
28.- ¿Qué es y cómo se forma el complejo de iniciación?
El complejo de iniciación es un complejo molecular que se forma en la primera etapa de la traducción o etapa de iniciación. Este complejo está formado por: el ARNm, la subunidad menor del ribosoma y el primer aminoacil-ARNt, que suele ser el ARNt-metionina. Una vez formado, se une a él la subunidad mayor, y se forma el ribosoma completo. Este complejo de iniciación se forma de la siguiente manera: El ARNm se une por su extremo 5' a la subunidad menor del ribosoma; en este proceso interviene un factor proteico de iniciación llamado FI1. A continuación, el primer aminoacil-ARNt se une, mediante puentes de hidrógeno y por su anticodón, al codón iniciador del ARNm, que suele ser el AUG. Por esta razón, el primer aminoacil-ARNt es el ARNt-metionina. En este proceso interviene otro factor de iniciación llamado FI2. En la formación del complejo de iniciación se requiere energía, que se obtiene de la hidrólisis del GTP.
El complejo de iniciación es un complejo molecular que se forma en la primera etapa de la traducción o etapa de iniciación. Este complejo está formado por: el ARNm, la subunidad menor del ribosoma y el primer aminoacil-ARNt, que suele ser el ARNt-metionina. Una vez formado, se une a él la subunidad mayor, y se forma el ribosoma completo. Este complejo de iniciación se forma de la siguiente manera: El ARNm se une por su extremo 5' a la subunidad menor del ribosoma; en este proceso interviene un factor proteico de iniciación llamado FI1. A continuación, el primer aminoacil-ARNt se une, mediante puentes de hidrógeno y por su anticodón, al codón iniciador del ARNm, que suele ser el AUG. Por esta razón, el primer aminoacil-ARNt es el ARNt-metionina. En este proceso interviene otro factor de iniciación llamado FI2. En la formación del complejo de iniciación se requiere energía, que se obtiene de la hidrólisis del GTP.
29.- ¿Qué es el operón?
El operón es un modelo de regulación de la expresión de los genes en las bacterias. Este modelo fue propuesto por F. Jacob y J. Monod entre los años cincuenta y sesenta. El operón esta formado por un conjunto de genes que están próximos en el cromosoma y codifican las proteínas que intervienen en un determinado proceso metabólico. A esto se añade un centro de control asociado, que permite o no la transcripción del conjunto de genes. En cada operón se diferencian las siguientes partes: Genes estructurales (E1, E2, etc). Son genes que codifican la síntesis de proteínas (enzimas) que intervienen en un proceso metabólico. Gen regulador (R). Es el gen que codifica la proteína represora, que se puede encontrar activa o inactiva. Esta proteína regula la actividad de los genes estructurales. Promotor (P). Es la secuencia de nucleótidos del ADN. Se encuentra por delante y cerca de los genes estructurales; a esta secuencia se unela ARN-polimerasa para iniciar la transcripción. Operador (O). Secuencia de nucleótidos del ADN que se sitúa entre el promotor y los genes estructurales; aquí se puede unir la proteína represora e impedir el avance de la ARN polimerasa y, por lo tanto, la transcripción de los genes estructurales.
El operón es un modelo de regulación de la expresión de los genes en las bacterias. Este modelo fue propuesto por F. Jacob y J. Monod entre los años cincuenta y sesenta. El operón esta formado por un conjunto de genes que están próximos en el cromosoma y codifican las proteínas que intervienen en un determinado proceso metabólico. A esto se añade un centro de control asociado, que permite o no la transcripción del conjunto de genes. En cada operón se diferencian las siguientes partes: Genes estructurales (E1, E2, etc). Son genes que codifican la síntesis de proteínas (enzimas) que intervienen en un proceso metabólico. Gen regulador (R). Es el gen que codifica la proteína represora, que se puede encontrar activa o inactiva. Esta proteína regula la actividad de los genes estructurales. Promotor (P). Es la secuencia de nucleótidos del ADN. Se encuentra por delante y cerca de los genes estructurales; a esta secuencia se une
30.- ¿Qué es y cómo se forma el complejo de iniciación?
El complejo de iniciación es un complejo molecular que se forma en la primera etapa de la traducción o etapa de iniciación. Este complejo está formado por: el ARNm, la subunidad menor del ribosoma y el primer aminoacil-ARNt, que suele ser el ARNt-metionina. Una vez formado, se une a él la subunidad mayor, y se forma el ribosoma completo. Este complejo de iniciación se forma de la siguiente manera: El ARNm se une por su extremo 5' a la subunidad menor del ribosoma; en este proceso interviene un factor proteico de iniciación llamado FI1. A continuación, el primer aminoacil-ARNt se une, mediante puentes de hidrógeno y por su anticodón, al codón iniciador del ARNm, que suele ser el AUG. Por esta razón, el primer aminoacil-ARNt es el ARNt-metionina. En este proceso interviene otro factor de iniciación llamado FI2. En la formación del complejo de iniciación se requiere energía, que se obtiene de la hidrólisis del GTP.
El complejo de iniciación es un complejo molecular que se forma en la primera etapa de la traducción o etapa de iniciación. Este complejo está formado por: el ARNm, la subunidad menor del ribosoma y el primer aminoacil-ARNt, que suele ser el ARNt-metionina. Una vez formado, se une a él la subunidad mayor, y se forma el ribosoma completo. Este complejo de iniciación se forma de la siguiente manera: El ARNm se une por su extremo 5' a la subunidad menor del ribosoma; en este proceso interviene un factor proteico de iniciación llamado FI1. A continuación, el primer aminoacil-ARNt se une, mediante puentes de hidrógeno y por su anticodón, al codón iniciador del ARNm, que suele ser el AUG. Por esta razón, el primer aminoacil-ARNt es el ARNt-metionina. En este proceso interviene otro factor de iniciación llamado FI2. En la formación del complejo de iniciación se requiere energía, que se obtiene de la hidrólisis del GTP.
31.- ¿Qué problema plantea durante la replicación el hecho de que las cadenas de ADN sean lineales?; ¿de qué mecanismos disponen las células eucariontes para resolver este problema?El problema que se plantea en las hebras de ADN lineal de las células eucariontes es que, tras la replicación, los extremos 5' no quedan completos al eliminarse el cebador, debido a que las polimerasas no sintetizan en sentido 3' 5'. La consecuencia de este hecho es que las sucesivas replicaciones conducen a un acortamiento del cromosoma, con la consiguiente pérdida de información genética. Los extremos del cromosoma son los telómeros, y su desaparición, por los acortamientos sucesivos de los extremos, provoca la inestabilidad y la unión de los cromosomas entre sí, produciendo la muerte celular. Para resolver el problema los eucariontes disponen de un enzima, telomerasa, constituido por una parte proteica y una secuencia de ribonucleótidos. Esta secuencia actúa como molde para alargar el extremo 3'. La prolongación, catalizada por la telomerasa, sirve como cebador para la síntesis, por parte de la polimerasa a, del extremo 5' que quedó incompleto. En algunos tejidos de los organismos pluricelulares se ha comprobado que no existe actividad telomerasa, enzima que está presente en los tejidos embrionarios. Esto supone un acortamiento progresivo de los telómeros, que puede ser un desencadenante del envejecimento celular. Asimismo, las células cancerosas, que presentan una capacidad de división indefinida, tienen actividad telomerasa.
32.- Define y pon un ejemplo de: Aneuploidía Poliploidía Trisomía Mutación puntual.
La poliploidía es un tipo de mutación cromosómica numérica en el que se ve afectado el número de juegos cromosómicos. Por ejemplo, en una especie dipliode (2n) aparece un individuo con tres juegos de cromosomas, triploide (3n). La aneuploidía es una mutación cromosómica numérica, que supone la modificación del número de cromosomas, sin afectar a juegos completos. Son casos en los que aparecen uno o varios cromosomas de más o de menos. Trisomía. Se produce cuando un individuo porta un cromosoma de más. En una especie diploide el individuo será 2n+1; es decir, que alguno de sus cromosomas portará tres copias en lugar de una pareja de homólogos. Mutación puntual. Es una mutación génica que afecta a un único par de nuleótidos. Por ejemplo, el cambio de un par A-T por el par G-C. Las mutaciones puntuales afectan a la secuencia del gen y pueden, por tanto, modificar la proteína que codifica. En algunos casos son la causa de enfermedades genéticas. Por ejemplo, la anemia falciforme es una enfermedad que se origina por una mutación en el gen que codifica las cadenas beta de la hemoglobina. La mutación provoca la sustitución de un ácido glutámico por una valina en la secuencia de aminoácidos.
La poliploidía es un tipo de mutación cromosómica numérica en el que se ve afectado el número de juegos cromosómicos. Por ejemplo, en una especie dipliode (2n) aparece un individuo con tres juegos de cromosomas, triploide (3n). La aneuploidía es una mutación cromosómica numérica, que supone la modificación del número de cromosomas, sin afectar a juegos completos. Son casos en los que aparecen uno o varios cromosomas de más o de menos. Trisomía. Se produce cuando un individuo porta un cromosoma de más. En una especie diploide el individuo será 2n+1; es decir, que alguno de sus cromosomas portará tres copias en lugar de una pareja de homólogos. Mutación puntual. Es una mutación génica que afecta a un único par de nuleótidos. Por ejemplo, el cambio de un par A-T por el par G-C. Las mutaciones puntuales afectan a la secuencia del gen y pueden, por tanto, modificar la proteína que codifica. En algunos casos son la causa de enfermedades genéticas. Por ejemplo, la anemia falciforme es una enfermedad que se origina por una mutación en el gen que codifica las cadenas beta de la hemoglobina. La mutación provoca la sustitución de un ácido glutámico por una valina en la secuencia de aminoácidos.
33.- Mutaciones génicas: Define mutación espontánea y mutación inducida. Tipos de agentes mutágenos. Explica los mecanismos de acción de los agentes mutágenos.
Las mutaciones espontáneas son lesiones o alteraciones en el ADN que se producen de forma fortuita. Surgen en cualquier tipo de célula y en cualquier momento. Pueden producirse por las siguientes causas: Errores en la replicación. Lesiones en el ADN (desaminaciones, despurinizaciones y oxidaciones). La acción de elementos transponibles. Las mutaciones inducidas son aquellas que se producen cuando un organismo está sometido a la acción de agentes (físicos o químicos), que producen alteraciones en el ADN. Estos agentes se llaman mutágenos. Los agentes mutágenos son aquellos que inducen mutaciones en el ADN cuando un organismo está sometido a su acción. Existen dos tipos de agentes mutágenos: Fisicos, como las radiaciones ionizantes y las UV. Químicos. Son sustancias que producen mutaciones por lesiones en el ADN. Entre ellos se encuentran los análogos de bases o los agentes alquilantes. Los agentes mutágenos actúan, preferentemente, en los puntos calientes, y producen un tipo de mutación específica. Los agentes mutágenos actúan provocando lesiones en el ADN de tres modos: Sustitución de bases. Los análogos de bases son moléculas tan parecidas a las bases nitrogenadas, que las sustituyen incorporándose al ADN. Así actúan el 5-bromouracilo y la 2-amonopurina. El 5-bromouracilo es un análogo de la timina que se aparea con la guanina cuando se encuentra en su forma enol. Esto origina transiciones A -T G -C. La 2-aminopurina es un análogo de la adenina, y se aparea con la citosina, originando una transición G -C A -T. Modificaciones de bases. Algunos mutágenos actúan produciendo modificaciones específicas en las bases. Entre ellos destacan los agentes alquilantes, como el etilsulfonato y la hidroxilamina, que provocan transiciones G - C A -T. Otros agentes que alteran las bases son los iones bisulfito y el ácido nitroso (HNO2), que producen desaminaciones en la citosina y forman uracilo, lo que provoca transiciones C T. Lesiones por daños en las bases. En este tipo de mutación, el daño producido en las bases impide el apareamiento específico, produciendo la interrupción de la replicación. El bloqueo de la replicación pone en funcionamiento el sistema de reparación SOS, que promueve la inserción de bases con muy poca fidelidad, pero permite que la replicación continúe. Así actúan la radiación UV, que provoca la formación de dímeros de pirimidinas (especialmente de timina), y la aflatoxina B1, que se une a la guanina y el benzopireno.
Las mutaciones espontáneas son lesiones o alteraciones en el ADN que se producen de forma fortuita. Surgen en cualquier tipo de célula y en cualquier momento. Pueden producirse por las siguientes causas: Errores en la replicación. Lesiones en el ADN (desaminaciones, despurinizaciones y oxidaciones). La acción de elementos transponibles. Las mutaciones inducidas son aquellas que se producen cuando un organismo está sometido a la acción de agentes (físicos o químicos), que producen alteraciones en el ADN. Estos agentes se llaman mutágenos. Los agentes mutágenos son aquellos que inducen mutaciones en el ADN cuando un organismo está sometido a su acción. Existen dos tipos de agentes mutágenos: Fisicos, como las radiaciones ionizantes y las UV. Químicos. Son sustancias que producen mutaciones por lesiones en el ADN. Entre ellos se encuentran los análogos de bases o los agentes alquilantes. Los agentes mutágenos actúan, preferentemente, en los puntos calientes, y producen un tipo de mutación específica. Los agentes mutágenos actúan provocando lesiones en el ADN de tres modos: Sustitución de bases. Los análogos de bases son moléculas tan parecidas a las bases nitrogenadas, que las sustituyen incorporándose al ADN. Así actúan el 5-bromouracilo y la 2-amonopurina. El 5-bromouracilo es un análogo de la timina que se aparea con la guanina cuando se encuentra en su forma enol. Esto origina transiciones A -T G -C. La 2-aminopurina es un análogo de la adenina, y se aparea con la citosina, originando una transición G -C A -T. Modificaciones de bases. Algunos mutágenos actúan produciendo modificaciones específicas en las bases. Entre ellos destacan los agentes alquilantes, como el etilsulfonato y la hidroxilamina, que provocan transiciones G - C A -T. Otros agentes que alteran las bases son los iones bisulfito y el ácido nitroso (HNO2), que producen desaminaciones en la citosina y forman uracilo, lo que provoca transiciones C T. Lesiones por daños en las bases. En este tipo de mutación, el daño producido en las bases impide el apareamiento específico, produciendo la interrupción de la replicación. El bloqueo de la replicación pone en funcionamiento el sistema de reparación SOS, que promueve la inserción de bases con muy poca fidelidad, pero permite que la replicación continúe. Así actúan la radiación UV, que provoca la formación de dímeros de pirimidinas (especialmente de timina), y la aflatoxina B1, que se une a la guanina y el benzopireno.
34.- Dos alteraciones frecuentes en el ADN son las despurinizaciones y la desaminación de la citosina. ¿De qué mecanismos dispone la célula para reparar estos errores?
Las despurinizaciones son mutaciones que son reparadas por un sistema que se inicia con la acción del nucleasa AP. Las desaminación de la citosina, que la convierte en uracilo, es reparada por glucosidasas (concretamente, el enzima uracilo-ADN-glucosidasa elimina el uracilo presente en el ADN). Estos enzimas rompen los enlaces N-glucosídicos, es decir, separan la base, pero no escinden la cadena.
Las despurinizaciones son mutaciones que son reparadas por un sistema que se inicia con la acción del nucleasa AP. Las desaminación de la citosina, que la convierte en uracilo, es reparada por glucosidasas (concretamente, el enzima uracilo-ADN-glucosidasa elimina el uracilo presente en el ADN). Estos enzimas rompen los enlaces N-glucosídicos, es decir, separan la base, pero no escinden la cadena.
35.- ¿Qué es la transposición?¿Cuáles son los tipos de elementos transponibles que aparecen en las bacterias?
La transposición es un mecanismo de cambio genético que se debe al desplazamiento de genes (fragmentos de ADN) dentro del mismo cromosoma o de un cromosoma a otro. Los fragmentos de ADN que se desplazan se denominan elementos genéticos transponibles o transposones, y han sido observados tanto en procariontes como en eucariontes. En las bacterias se han descrito dos tipos de elementos transponibles: Las secuencias de inserción: son pequeños fragmentos de ADN que cambian de posición en el cromosoma bacteriano. Estas secuencias contienen, únicamente, genes relacionados con la función de inserción. Los transposones o elementos transponibles: son secuencias de ADN formadas por varios genes que contienen, en cada uno de sus extremos, secuencias de inserción. Estas secuencias son las que otorgan al transposón la capacidad de intercalarse en sitios distintos del cromosoma o de un plásmido.
La transposición es un mecanismo de cambio genético que se debe al desplazamiento de genes (fragmentos de ADN) dentro del mismo cromosoma o de un cromosoma a otro. Los fragmentos de ADN que se desplazan se denominan elementos genéticos transponibles o transposones, y han sido observados tanto en procariontes como en eucariontes. En las bacterias se han descrito dos tipos de elementos transponibles: Las secuencias de inserción: son pequeños fragmentos de ADN que cambian de posición en el cromosoma bacteriano. Estas secuencias contienen, únicamente, genes relacionados con la función de inserción. Los transposones o elementos transponibles: son secuencias de ADN formadas por varios genes que contienen, en cada uno de sus extremos, secuencias de inserción. Estas secuencias son las que otorgan al transposón la capacidad de intercalarse en sitios distintos del cromosoma o de un plásmido.
36.- Explica la siguiente afirmación: El cáncer es una enfermedad genética; pero, salvo en algunas ocasiones, no es una enfermedad hereditaria.
La mayoría de los cánceres son producidos por agentes ambientales que provocan mutaciones en el ADN, por lo que el cáncer es una enfermedad genética. Estas mutaciones afectan a dos tipos de genes: Protooncogenes: son genes activadores de la división celular. La mutación los convierte en oncogenes, que producen gran cantidad de una proteína que estimula la división celular o formas muy activas de esa proteína. Genes supresores de tumores: son inhibidores de la división celular. Una mutación puede desactivarlos, dejando de producir la proteína supresora de la división; lo que desencadena la división celular. Tanto las mutaciones que afectan a los protooncogenes, como las que inciden en los genes supresores de los tumores, se producen mayoritariamente en las células somáticas. Este hecho afecta al desarrollo de las capacidades del individuo que sufre la mutación e influye en su supervivencia, pero no modifica la composición genética de su descendencia. Por tanto, el cáncer no es una enfermedad hereditaria, aunque sí parece que existe cierta predisposición genética a padecerlo.
La mayoría de los cánceres son producidos por agentes ambientales que provocan mutaciones en el ADN, por lo que el cáncer es una enfermedad genética. Estas mutaciones afectan a dos tipos de genes: Protooncogenes: son genes activadores de la división celular. La mutación los convierte en oncogenes, que producen gran cantidad de una proteína que estimula la división celular o formas muy activas de esa proteína. Genes supresores de tumores: son inhibidores de la división celular. Una mutación puede desactivarlos, dejando de producir la proteína supresora de la división; lo que desencadena la división celular. Tanto las mutaciones que afectan a los protooncogenes, como las que inciden en los genes supresores de los tumores, se producen mayoritariamente en las células somáticas. Este hecho afecta al desarrollo de las capacidades del individuo que sufre la mutación e influye en su supervivencia, pero no modifica la composición genética de su descendencia. Por tanto, el cáncer no es una enfermedad hereditaria, aunque sí parece que existe cierta predisposición genética a padecerlo.
37.- ¿Qué es el ADN recombinante? Explica algunas aplicaciones de esta tecnología.
El ADN recombinante es un fragmento de ADN construido artificialmente con segmentos no homólogos procedentes de organismos diferentes. Consta de un vector, que es un fragmento que contiene un punto de iniciación de la replicación (generalmente es un plásmido o un virus), y el fragmento o gen que es objeto de estudio. Algunas aplicaciones de la tecnología del ADN recombinante son: La síntesis bacteriana de proteínas útiles. Incorporando los genes adecuados a un vector e introduciéndole en una bacteria se pude conseguir que sinteticen las proteínas codificadas por esos genes. La insulina, la hormona del crecimiento, la somatostatina, factores de coagulación, etc. son algunas proteínas que hoy se producen por ingeniería genética. La detección precoz y diagnosis de enfermedades hereditarias. Se han desarrollado actualmente pruebas fiables que hacen posible un diagnóstico precoz de enfermedades como la anemia falciforme, algunas formas de hemofilia, la distrofia muscular infantil o la corea de Huntington. Las técnicas utilizadas son los enzimas de restricción y las sondas de ADN. Transferencia de genes a plantas de interés económico. Mediante la transferencia de genes útiles se han conseguido plantas modificadas genéticamente, como maíz resistente a algunas plagas, soja que produce ácidos grasos de interés industrial o plantas de tomate, que retrasan la maduración del fruto. Los vectores más utilizados para la introducción de los genes son las bombas génicas y una bacteria del suelo llamada Agrobacterium tumefaciens.
El ADN recombinante es un fragmento de ADN construido artificialmente con segmentos no homólogos procedentes de organismos diferentes. Consta de un vector, que es un fragmento que contiene un punto de iniciación de la replicación (generalmente es un plásmido o un virus), y el fragmento o gen que es objeto de estudio. Algunas aplicaciones de la tecnología del ADN recombinante son: La síntesis bacteriana de proteínas útiles. Incorporando los genes adecuados a un vector e introduciéndole en una bacteria se pude conseguir que sinteticen las proteínas codificadas por esos genes. La insulina, la hormona del crecimiento, la somatostatina, factores de coagulación, etc. son algunas proteínas que hoy se producen por ingeniería genética. La detección precoz y diagnosis de enfermedades hereditarias. Se han desarrollado actualmente pruebas fiables que hacen posible un diagnóstico precoz de enfermedades como la anemia falciforme, algunas formas de hemofilia, la distrofia muscular infantil o la corea de Huntington. Las técnicas utilizadas son los enzimas de restricción y las sondas de ADN. Transferencia de genes a plantas de interés económico. Mediante la transferencia de genes útiles se han conseguido plantas modificadas genéticamente, como maíz resistente a algunas plagas, soja que produce ácidos grasos de interés industrial o plantas de tomate, que retrasan la maduración del fruto. Los vectores más utilizados para la introducción de los genes son las bombas génicas y una bacteria del suelo llamada Agrobacterium tumefaciens.
38.- Define los conceptos de mutación, recombinación y transposición.
Mutación: Una mutación es un cambio heredable y medible del material genético. Las mutaciones pueden afectar a cualquier tipo de células, pero solamente se transmitirán a la descendencia aquellas mutaciones que se produzcan en los gametos o en células embrionarias que den lugar a gametos. Recombinación: La recombinación consiste en la aparición de nuevas combinaciones de genes diferentes de las que se encuentran en los cromosomas de una célula determinada. Estas nuevas combinaciones surgen por el intercambio de fragmentos de ADN entre los cromosomas, durante el proceso llamado sobrecruzamiento. Durante la recombinación no se pierde ni se gana ningún nucleótido, por lo que el mecanismo molecular de intercambio es muy preciso. Transposición: La transposición es un mecanismo de cambio genético que se debe al desplazamiento de genes (fragmentos de ADN) dentro del mismo cromosoma o de un cromosoma a otro. Los fragmentos de ADN que se desplazan se denominan elementos genéticos transponibles o transposones, y han sido observados tanto en procariontes como en eucariontes.
Mutación: Una mutación es un cambio heredable y medible del material genético. Las mutaciones pueden afectar a cualquier tipo de células, pero solamente se transmitirán a la descendencia aquellas mutaciones que se produzcan en los gametos o en células embrionarias que den lugar a gametos. Recombinación: La recombinación consiste en la aparición de nuevas combinaciones de genes diferentes de las que se encuentran en los cromosomas de una célula determinada. Estas nuevas combinaciones surgen por el intercambio de fragmentos de ADN entre los cromosomas, durante el proceso llamado sobrecruzamiento. Durante la recombinación no se pierde ni se gana ningún nucleótido, por lo que el mecanismo molecular de intercambio es muy preciso. Transposición: La transposición es un mecanismo de cambio genético que se debe al desplazamiento de genes (fragmentos de ADN) dentro del mismo cromosoma o de un cromosoma a otro. Los fragmentos de ADN que se desplazan se denominan elementos genéticos transponibles o transposones, y han sido observados tanto en procariontes como en eucariontes.
39.- Clasifica y explica el mecanismo de acción de los siguientes agentes mutágenos: 5-bromouracilo. Ácido nitroso. Radiación ultravioleta.
El 5-bromouracilo es un análogo de bases que actúa produciendo sustituciones de bases en el ADN. Concretamente, es un análogo de la timina, que se aparea con la guanina cuando se encuentra en su forma enol, originando transiciones A -T G - C. El ácido nitroso (HNO2), altera el ADN, provocando modificaciones en las bases. Su acción produce desaminaciones en la citosina, transformándola en uracilo, lo que provoca transiciones C T. La radiación ultravioleta es un mutágeno físico que induce la formación de dímeros de pirimidinas (especialmente, de timina). Este tipo de mutación impide el apareamiento específico de las bases, produciendo la interrupción de la replicación. El bloqueo de la replicación pone en funcionamiento el sistema de reparación SOS, que promueve la inserción de bases con muy poca fidelidad, pero que permite que la replicación continúe.
El 5-bromouracilo es un análogo de bases que actúa produciendo sustituciones de bases en el ADN. Concretamente, es un análogo de la timina, que se aparea con la guanina cuando se encuentra en su forma enol, originando transiciones A -T G - C. El ácido nitroso (HNO2), altera el ADN, provocando modificaciones en las bases. Su acción produce desaminaciones en la citosina, transformándola en uracilo, lo que provoca transiciones C T. La radiación ultravioleta es un mutágeno físico que induce la formación de dímeros de pirimidinas (especialmente, de timina). Este tipo de mutación impide el apareamiento específico de las bases, produciendo la interrupción de la replicación. El bloqueo de la replicación pone en funcionamiento el sistema de reparación SOS, que promueve la inserción de bases con muy poca fidelidad, pero que permite que la replicación continúe.
40.- Algunas enfermedades genéticas en la especie humana son debidas a mutaciones en los sistemas de reparación del ADN. Describe, al menos, dos ejemplos de estas alteraciones genéticas.Los sistemas de reparación están constituidos por enzimas y, por lo tanto, codificados por genes que pueden sufrir mutaciones. Estas mutaciones pueden dar origen a enfermedades genéticas como: Xeroderma pigmentosum. Es una enfermedad de la piel que origina una pigmentación anormal, con gran abundancia de pecas. Termina en focos de cáncer de piel. Es producida por una mutación en el gen que codifica la endonucleasa que repara los dímeros de timina. Se ha comprobado que las personas que sufren la enfermedad poseen niveles bajos del enzima fotorreactivo. La telangiectasia (dilatación de los vasos sanguíneos de la piel) y algunos tipos de envejecimiento prematuro son dos ejemplos de enfermedades producidas por mutaciones en los sistemas de reparación.
41.- Representa de forma esquemática el intercambio de cadenas homólogas de ADN que conduce a la recombinación genética.
El proceso de intercambio de cadenas homólogas se puede representar del siguiente modo: 1. Se produce la rotura de una hebra de cada cadena homóloga de ADN (a y b). 2. Cada hebra se une con la opuesta de la cadena homologa (c). 3. Las ligasas unen los fragmentos de las dos hebras y se forma ADN heterodúplex (híbrido) (d). 4. El intercambio avanza por la hebra a lo largo del cromosoma (e). 5. En un punto determinado las hebras se rompen de nuevo y se sueldan (f y g). 6. El resultado es el intercambio de hebras entre dos moléculas de ADN y la recombinación genética (h).
El proceso de intercambio de cadenas homólogas se puede representar del siguiente modo: 1. Se produce la rotura de una hebra de cada cadena homóloga de ADN (a y b). 2. Cada hebra se une con la opuesta de la cadena homologa (c). 3. Las ligasas unen los fragmentos de las dos hebras y se forma ADN heterodúplex (híbrido) (d). 4. El intercambio avanza por la hebra a lo largo del cromosoma (e). 5. En un punto determinado las hebras se rompen de nuevo y se sueldan (f y g). 6. El resultado es el intercambio de hebras entre dos moléculas de ADN y la recombinación genética (h).
42.- Explica el punto de vista de las diferentes teorías evolucionistas acerca del papel de la mutación.
Cada una de las diferentes teorías evolucionistas ofrece su punto de vista particular sobre el papel de las mutaciones en la evolución: Para el neodarvinismo, la mutación es una fuente de variación que proporciona beneficios o perjuicios. La selección natural elimina las mutaciones perjudiciales y favorece que las beneficiosas incrementen su presencia en la población. A lo largo del tiempo, la consolidación de las nuevas características origina cambios, que conducen a la evolución de las especies. Según la teoría neutralista, las mutaciones no suponen ni perjuicio ni beneficio. Las mutaciones determinan características neutras con respecto a la selección, y es el azar quien dirige, en gran medida, el proceso evolutivo. La teoría de los equilibrios interrumpidos considera que la acumulación de pequeñas mutaciones génicas proporciona la posibilidad de adaptaciones. Los grandes cambios (mutaciones cromosómicas, por ejemplo) explican la aparición de los grandes grupos taxonómicos (familias, clases, etc.).
Cada una de las diferentes teorías evolucionistas ofrece su punto de vista particular sobre el papel de las mutaciones en la evolución: Para el neodarvinismo, la mutación es una fuente de variación que proporciona beneficios o perjuicios. La selección natural elimina las mutaciones perjudiciales y favorece que las beneficiosas incrementen su presencia en la población. A lo largo del tiempo, la consolidación de las nuevas características origina cambios, que conducen a la evolución de las especies. Según la teoría neutralista, las mutaciones no suponen ni perjuicio ni beneficio. Las mutaciones determinan características neutras con respecto a la selección, y es el azar quien dirige, en gran medida, el proceso evolutivo. La teoría de los equilibrios interrumpidos considera que la acumulación de pequeñas mutaciones génicas proporciona la posibilidad de adaptaciones. Los grandes cambios (mutaciones cromosómicas, por ejemplo) explican la aparición de los grandes grupos taxonómicos (familias, clases, etc.).
43.- ¿Qué es un organismo transgénico? Cita algunas aplicaciones de estos organismos y comenta los posibles problemas que plantean.
Organismo transgénico. Es aquel desarrollado a partir de una célula cuyo genoma ha sido modificado mediante la introducción, de forma estable, de nuevos genes procedentes de una especie distinta. Las aplicaciones de los organismos transgénicos son muy variadas, destacaremos: Utilización de microorganismos trasgénicos para la síntesis de proteínas útiles. Incorporando los genes adecuados a un vector e introduciéndolo en una bacteria se puede conseguir que sinteticen las proteínas codificadas por esos genes. La insulina, la hormona del crecimiento, la somatostatina, factores de coagulación, etc. son algunas proteínas que hoy se producen por ingeniería genética. Introducción de genes a plantas de interés económico. Mediante la transferencia de genes útiles se han conseguido plantas modificadas genéticamente, como maíz resistente a algunas plagas, soja que produce ácidos grasos de interés industrial o plantas de tomate que retrasan la maduración del fruto. Los vectores más utilizados para la introducción de los genes son las bombas génicas y una bacteria del suelo llamada Agrobacterium tumefaciens. La utilización de organismos transgénicos ha planteado varios interrogantes, por ejemplo: El desconocimiento de las consecuencias que tiene la introducción de genes en la fisiología de los organismos vivos. Se desconocen las posibles consecuencias ecológicas y para la salud humana que se producirían si la bacteria modificada se escapara accidentalmente (o fuese liberada intencionadamente). La posible aparición de reacciones alérgicas, frente a los nuevos productos sintetizados por estos organismos. La potenciación del uso de herbicidas, ya que muchas de las plantas transgénicas comercializadas están diseñadas para ser resistentes a altas concentraciones de estos productos. La pérdida de diversidad biológica por introducción de nuevos genes en los ecosistemas, de los que se desconoce su efecto, y que pueden provocar la desaparición de las variedades naturales.
Organismo transgénico. Es aquel desarrollado a partir de una célula cuyo genoma ha sido modificado mediante la introducción, de forma estable, de nuevos genes procedentes de una especie distinta. Las aplicaciones de los organismos transgénicos son muy variadas, destacaremos: Utilización de microorganismos trasgénicos para la síntesis de proteínas útiles. Incorporando los genes adecuados a un vector e introduciéndolo en una bacteria se puede conseguir que sinteticen las proteínas codificadas por esos genes. La insulina, la hormona del crecimiento, la somatostatina, factores de coagulación, etc. son algunas proteínas que hoy se producen por ingeniería genética. Introducción de genes a plantas de interés económico. Mediante la transferencia de genes útiles se han conseguido plantas modificadas genéticamente, como maíz resistente a algunas plagas, soja que produce ácidos grasos de interés industrial o plantas de tomate que retrasan la maduración del fruto. Los vectores más utilizados para la introducción de los genes son las bombas génicas y una bacteria del suelo llamada Agrobacterium tumefaciens. La utilización de organismos transgénicos ha planteado varios interrogantes, por ejemplo: El desconocimiento de las consecuencias que tiene la introducción de genes en la fisiología de los organismos vivos. Se desconocen las posibles consecuencias ecológicas y para la salud humana que se producirían si la bacteria modificada se escapara accidentalmente (o fuese liberada intencionadamente). La posible aparición de reacciones alérgicas, frente a los nuevos productos sintetizados por estos organismos. La potenciación del uso de herbicidas, ya que muchas de las plantas transgénicas comercializadas están diseñadas para ser resistentes a altas concentraciones de estos productos. La pérdida de diversidad biológica por introducción de nuevos genes en los ecosistemas, de los que se desconoce su efecto, y que pueden provocar la desaparición de las variedades naturales.
44.- Describe las principales moléculas que intervienen en la replicación del ADN en procariontes y explica el mecanismo por el que tiene lugar el proceso.
Las principales moléculas implicadas en la replicación del ADN en los procariontes son: ADN polimerasas. Son los enzimas que se encargan de catalizar la formación de enlaces fosfodiéster entre dos nucleótidos consecutivos. Añaden, al extremo 3' de una cadena, los nucleótidos complementarios a los de la cadena, que actúa como molde. Para llevar a cabo la catálisis necesitan un extremo 3'-OH libre, por lo que requieren un cebador para iniciar la síntesis. Este cebador es un fragmento de ARN llamado primer o iniciador. En E. coli se conocen tres polimerasas: el ADN polimerasa I, que presenta también actividad exonucleasa y se encarga de rellenar espacios polimerizando ADN; el ADN polimerasa II, que interviene en la reparación del ADN, y el ADN polimerasa III, que sintetiza la mayor parte el ADN durante la replicación. Helicasas. Separan las dos hebras de la molécula de ADN mediante la rotura de los puentes de hidrógeno que las mantienen unidas; de este modo, cada hebra puede actuar de molde para la síntesis de una nueva cadena. Topoisomerasas. Son enzimas encargados de desenrollar la doble hélice de ADN a medida que se va replicando, para permitir la acción del ADN polimerasa. Primasa. Es un ARN polimerasa que sintetiza pequeños fragmentos de ARN llamados cebadores o primer. Proteínas SSB. Son proteínas estabilizadoras de la cadena sencilla. Una vez que actúa la helicasa se unen a las cadenas sencillas, estabilizándolas mientras se produce la replicación. ADN ligasas. Se encargan de unir fragmentos adyacentes de ADN, que se encuentran correctamente emparejados con la hebra complementaria. El mecanismo de la replicación podemos resumirlo en los siguientes pasos: 1. Desenrollamiento y apertura de la doble hélice. Por acción de los enzimas helicasas, la molécula de ADN se desenrolla, rompiéndose los puentes de hidrógeno que mantienen unidas las dos cadenas. Estas se separan y se forma una horquilla de replicación. Las dos moléculas de ADN, que se van formando a medida que se va produciendo la replicación, van girando por acción de los topoisomerasas, evitando así problemas de superenrollamiento. 2. Síntesis de las nuevas hebras. Simultáneamente a la separación de las dos hebras, se van sintetizando las nuevas hebras complementarias, por acción de los ADN polimerasas. El proceso es el siguiente: El ARN polimerasa, denominada primasa, sintetiza una pequeña molécula de ARN que actúa de cebador, ya que el ADN polimerasa es capaz de alargar la cadena, pero no de iniciar la síntesis. El ADN polimerasa III, utilizando como cebador ( primer ) el fragmento de ARN, va alargando la cadena. Este enzima solo es capaz de unir nucleótidos en sentido 5' 3'. Como las dos cadenas que forman el ADN son antiparalelas, la cadena de ADN que tiene dirección 3' 5' se replica de forma continua, mientras que la otra cadena que tiene dirección 5' 3' lo hace de forma discontinua. Esta cadena se replica de forma retardada mediante la síntesis de pequeños fragmentos (1 000 nucleótidos) que crecen en dirección 5' 3', llamados fragmentos de Okazaki. A continuación el ADN polimerasa I elimina los fragmentos de ARN que han actuado de cebadores y rellena los huecos. Por último, el ADN-ligasa une los extremos de los fragmentos, dando lugar a la molécula completa.
Las principales moléculas implicadas en la replicación del ADN en los procariontes son: ADN polimerasas. Son los enzimas que se encargan de catalizar la formación de enlaces fosfodiéster entre dos nucleótidos consecutivos. Añaden, al extremo 3' de una cadena, los nucleótidos complementarios a los de la cadena, que actúa como molde. Para llevar a cabo la catálisis necesitan un extremo 3'-OH libre, por lo que requieren un cebador para iniciar la síntesis. Este cebador es un fragmento de ARN llamado primer o iniciador. En E. coli se conocen tres polimerasas: el ADN polimerasa I, que presenta también actividad exonucleasa y se encarga de rellenar espacios polimerizando ADN; el ADN polimerasa II, que interviene en la reparación del ADN, y el ADN polimerasa III, que sintetiza la mayor parte el ADN durante la replicación. Helicasas. Separan las dos hebras de la molécula de ADN mediante la rotura de los puentes de hidrógeno que las mantienen unidas; de este modo, cada hebra puede actuar de molde para la síntesis de una nueva cadena. Topoisomerasas. Son enzimas encargados de desenrollar la doble hélice de ADN a medida que se va replicando, para permitir la acción del ADN polimerasa. Primasa. Es un ARN polimerasa que sintetiza pequeños fragmentos de ARN llamados cebadores o primer. Proteínas SSB. Son proteínas estabilizadoras de la cadena sencilla. Una vez que actúa la helicasa se unen a las cadenas sencillas, estabilizándolas mientras se produce la replicación. ADN ligasas. Se encargan de unir fragmentos adyacentes de ADN, que se encuentran correctamente emparejados con la hebra complementaria. El mecanismo de la replicación podemos resumirlo en los siguientes pasos: 1. Desenrollamiento y apertura de la doble hélice. Por acción de los enzimas helicasas, la molécula de ADN se desenrolla, rompiéndose los puentes de hidrógeno que mantienen unidas las dos cadenas. Estas se separan y se forma una horquilla de replicación. Las dos moléculas de ADN, que se van formando a medida que se va produciendo la replicación, van girando por acción de los topoisomerasas, evitando así problemas de superenrollamiento. 2. Síntesis de las nuevas hebras. Simultáneamente a la separación de las dos hebras, se van sintetizando las nuevas hebras complementarias, por acción de los ADN polimerasas. El proceso es el siguiente: El ARN polimerasa, denominada primasa, sintetiza una pequeña molécula de ARN que actúa de cebador, ya que el ADN polimerasa es capaz de alargar la cadena, pero no de iniciar la síntesis. El ADN polimerasa III, utilizando como cebador ( primer ) el fragmento de ARN, va alargando la cadena. Este enzima solo es capaz de unir nucleótidos en sentido 5' 3'. Como las dos cadenas que forman el ADN son antiparalelas, la cadena de ADN que tiene dirección 3' 5' se replica de forma continua, mientras que la otra cadena que tiene dirección 5' 3' lo hace de forma discontinua. Esta cadena se replica de forma retardada mediante la síntesis de pequeños fragmentos (1 000 nucleótidos) que crecen en dirección 5' 3', llamados fragmentos de Okazaki. A continuación el ADN polimerasa I elimina los fragmentos de ARN que han actuado de cebadores y rellena los huecos. Por último, el ADN-ligasa une los extremos de los fragmentos, dando lugar a la molécula completa.
45.- ¿Qué es una mutación génica? Indica sus tipos.
Las mutaciones génicas son aquellas que afectan a un solo gen o a un número pequeño de genes. Son mutaciones que provocan un cambio en la secuencia de nucleótidos del ADN. Estos cambios pueden ser la sustitución de un o unos nucleótidos por otros, la inversión, inserción o deleción (pérdida) de uno o varios nucleótidos. Las mutaciones génicas se producen de forma espontánea (mutaciones espontáneas), o bien por efecto de las condiciones ambientales (mutaciones inducidas). Las mutaciones espontáneas surgen en cualquier tipo de célula y en cualquier momento. Pueden producirse por las siguientes causas: Errores en la replicación. Lesiones en el ADN (desaminaciones, despurinizaciones y oxidaciones). La acción de elementos transponibles. Las mutaciones inducidas se producen cuando un organismo está sometido a la acción de agentes mutágenos específicos. Pueden ser: agentes físicos, como la radiación UV o las radiaciones ionizantes; o agentes químicos, como los análogos de bases o los agentes alquilantes.
Las mutaciones génicas son aquellas que afectan a un solo gen o a un número pequeño de genes. Son mutaciones que provocan un cambio en la secuencia de nucleótidos del ADN. Estos cambios pueden ser la sustitución de un o unos nucleótidos por otros, la inversión, inserción o deleción (pérdida) de uno o varios nucleótidos. Las mutaciones génicas se producen de forma espontánea (mutaciones espontáneas), o bien por efecto de las condiciones ambientales (mutaciones inducidas). Las mutaciones espontáneas surgen en cualquier tipo de célula y en cualquier momento. Pueden producirse por las siguientes causas: Errores en la replicación. Lesiones en el ADN (desaminaciones, despurinizaciones y oxidaciones). La acción de elementos transponibles. Las mutaciones inducidas se producen cuando un organismo está sometido a la acción de agentes mutágenos específicos. Pueden ser: agentes físicos, como la radiación UV o las radiaciones ionizantes; o agentes químicos, como los análogos de bases o los agentes alquilantes.
46.- Describe los mecanismos que producen la aparición de mutaciones espontáneas originadas por lesiones en el ADN.
Las mutaciones espontáneas más frecuentes originadas por lesiones en el ADN son el resultado de: Despurinizaciones. Consisten en la pérdida de bases púricas (adenina y guanina) por ruptura del enlace N-glucosídico, que se establece entre la desoxirribosa y la base. Durante la replicación posterior este punto no especifica ninguna base, produciéndose una deleción (pérdida de un par de bases). Desaminaciones. La desaminación provoca la conversión de la citosina en uracilo, que se empareja con la adenina. Este fenómeno conduce a la aparición de una transición GC AT durante la replicación. También por desaminación pueden sustituirse citosinas por timinas. Oxidaciones. Se deben a la acción de los radicales libres oxigenados (superóxido O-2, peróxido H2O2, hidroxilo -OH), producidos por la célula durante el metabolismo aerobio. Estas sustancias forman derivados de la guanina que dan lugar a transversiones G T.
Las mutaciones espontáneas más frecuentes originadas por lesiones en el ADN son el resultado de: Despurinizaciones. Consisten en la pérdida de bases púricas (adenina y guanina) por ruptura del enlace N-glucosídico, que se establece entre la desoxirribosa y la base. Durante la replicación posterior este punto no especifica ninguna base, produciéndose una deleción (pérdida de un par de bases). Desaminaciones. La desaminación provoca la conversión de la citosina en uracilo, que se empareja con la adenina. Este fenómeno conduce a la aparición de una transición GC AT durante la replicación. También por desaminación pueden sustituirse citosinas por timinas. Oxidaciones. Se deben a la acción de los radicales libres oxigenados (superóxido O-2, peróxido H2O2, hidroxilo -OH), producidos por la célula durante el metabolismo aerobio. Estas sustancias forman derivados de la guanina que dan lugar a transversiones G T.
47.- La aflatoxina B1 es un potente carcinógeno que se une a la guanina e impide la replicación del ADN. Explica el mecanismo de reparación que actuará para corregir los efectos de este mutágeno.
La aflatoxina B1 es un agente mutágeno que provoca el bloqueo de la replicación. Esta interrupción puede conducir a la muerte de la célula. El mecanismo de reparación que se pondrá en marcha para desbloquear la replicación es el sistema SOS o de emergencia. Este sistema desbloquea la replicación, pero promueve inserciones de bases reduciendo la fidelidad, lo que supone la aparición de mutaciones.
La aflatoxina B1 es un agente mutágeno que provoca el bloqueo de la replicación. Esta interrupción puede conducir a la muerte de la célula. El mecanismo de reparación que se pondrá en marcha para desbloquear la replicación es el sistema SOS o de emergencia. Este sistema desbloquea la replicación, pero promueve inserciones de bases reduciendo la fidelidad, lo que supone la aparición de mutaciones.
48.- Define recombinación y clasifica sus tipos.
La recombinación consiste en la aparición de nuevas combinaciones de genes, que serán diferentes de las que se encuentran en los cromosomas de una célula determinada. Estas nuevas combinaciones surgen por el intercambio de fragmentos de ADN entre los cromosomas, durante el proceso llamado sobrecruzamiento. Durante la recombinación no se pierde ni se gana ningún nucleótido, por lo que el mecanismo molecular de intercambio es muy preciso. Se distinguen dos tipos de recombinación: Recombinación específica. El intercambio se produce entre secuencias específicas de ADN, homólogas o no. A este caso pertenece la recombinación de algunos fagos con el cromosoma bacteriano o la inserción de elementos transponibles en distintos puntos de un cromosoma. Recombinación general u homóloga. Es la más habitual y se produce como resultado del intercambio de información entre los cromosomas homólogos.
La recombinación consiste en la aparición de nuevas combinaciones de genes, que serán diferentes de las que se encuentran en los cromosomas de una célula determinada. Estas nuevas combinaciones surgen por el intercambio de fragmentos de ADN entre los cromosomas, durante el proceso llamado sobrecruzamiento. Durante la recombinación no se pierde ni se gana ningún nucleótido, por lo que el mecanismo molecular de intercambio es muy preciso. Se distinguen dos tipos de recombinación: Recombinación específica. El intercambio se produce entre secuencias específicas de ADN, homólogas o no. A este caso pertenece la recombinación de algunos fagos con el cromosoma bacteriano o la inserción de elementos transponibles en distintos puntos de un cromosoma. Recombinación general u homóloga. Es la más habitual y se produce como resultado del intercambio de información entre los cromosomas homólogos.
49.- ¿Son heredables todas las mutaciones que sufre un individuo pluricelular?
En los organismos pluricelulares, las mutaciones tienen consecuencias distintas si se producen en las células germinales o si afectan a las células somáticas. En el primer caso, los efectos de la mutación son heredables, ya que estas son las células que participan en la reproducción; pero en el segundo, que son las llamadas mutaciones somáticas, los cambios se producen en células que mueren con el organismo y, por lo tanto, no afectan a la descendencia.
En los organismos pluricelulares, las mutaciones tienen consecuencias distintas si se producen en las células germinales o si afectan a las células somáticas. En el primer caso, los efectos de la mutación son heredables, ya que estas son las células que participan en la reproducción; pero en el segundo, que son las llamadas mutaciones somáticas, los cambios se producen en células que mueren con el organismo y, por lo tanto, no afectan a la descendencia.
50.- ¿Qué es la terapia génica? Explica las diferentes estrategias para su aplicación y los problemas que plantea esta técnica.
La terapia génica es el tratamiento de una enfermedad que se basa en la introducción de genes en el organismo como forma de atacar enfermedades con base genética. La técnica consiste en la introducción de genes correctos, para corregir el efecto producido por genes defectuosos. Las diferentes estrategias de terapia génica son: Ex vivo: Consiste en extraer las células del enfermo y cultivarlas. Posteriormente, se les inserta el gen normal y se reintroducen en el organismo. Hoy en día, es la técnica más utilizada. In situ: Mediante este procedimiento se introducen los genes directamente en los tejidos. In vivo: Los genes se introducen por vía sanguínea, unidos a vectores que contienen moléculas en su superficie, que son reconocidas por receptores específicos de determinadas células, las células diana. Allí transfieren la información genética deseada. Algunos de los problemas que plantea la aplicación de la terapia génica son: En las técnicas in situ y ex vivo, los genes implantados no producen la suficiente cantidad de proteína y, además, las células portadoras terminan por morir y, con ellas, el efecto deseado. La integración del gen se produce al azar dentro del genoma. Este hecho puede dar lugar a la fragmentación de genes importantes; por ejemplo, un gen supresor de tumores, con lo que se está induciendo un defecto genético al intentar arreglar otro. De todos modos, aunque quedan muchos problemas por resolver, la terapia génica ha abierto grandes posibilidades para el futuro.
La terapia génica es el tratamiento de una enfermedad que se basa en la introducción de genes en el organismo como forma de atacar enfermedades con base genética. La técnica consiste en la introducción de genes correctos, para corregir el efecto producido por genes defectuosos. Las diferentes estrategias de terapia génica son: Ex vivo: Consiste en extraer las células del enfermo y cultivarlas. Posteriormente, se les inserta el gen normal y se reintroducen en el organismo. Hoy en día, es la técnica más utilizada. In situ: Mediante este procedimiento se introducen los genes directamente en los tejidos. In vivo: Los genes se introducen por vía sanguínea, unidos a vectores que contienen moléculas en su superficie, que son reconocidas por receptores específicos de determinadas células, las células diana. Allí transfieren la información genética deseada. Algunos de los problemas que plantea la aplicación de la terapia génica son: En las técnicas in situ y ex vivo, los genes implantados no producen la suficiente cantidad de proteína y, además, las células portadoras terminan por morir y, con ellas, el efecto deseado. La integración del gen se produce al azar dentro del genoma. Este hecho puede dar lugar a la fragmentación de genes importantes; por ejemplo, un gen supresor de tumores, con lo que se está induciendo un defecto genético al intentar arreglar otro. De todos modos, aunque quedan muchos problemas por resolver, la terapia génica ha abierto grandes posibilidades para el futuro.
51.- Durante la replicación, los ADN polimerasas actúan sintetizando la hebra nueva en sentido 5' 3'. Si las dos hebras de la molécula de ADN son antiparalelas, ¿cómo es posible que se repliquen a la vez?
Durante la replicación del ADN las dos cadenas se sintetizan a la vez, pero no de la misma forma: La hebra que crece en sentido 5' 3' no plantea problemas, ya que los ADN polimerasas leen en sentido 3' 5' y sintetizan en sentido 5' 3'. Esta hebra se fabrica de forma continua y se denomina hebra líder. La otra cadena, llamada retardada, es antiparalela y, por tanto, no puede replicarse de forma continua. La síntesis se realiza en dirección 5' 3' en trozos de unos 1 000 nucleótidos, llamados fragmentos de Okazaki. Estos fragmentos necesitan un ARN cebador que, posteriormente, será degradado y los fragmentos unidos por los ADN ligasas.
Durante la replicación del ADN las dos cadenas se sintetizan a la vez, pero no de la misma forma: La hebra que crece en sentido 5' 3' no plantea problemas, ya que los ADN polimerasas leen en sentido 3' 5' y sintetizan en sentido 5' 3'. Esta hebra se fabrica de forma continua y se denomina hebra líder. La otra cadena, llamada retardada, es antiparalela y, por tanto, no puede replicarse de forma continua. La síntesis se realiza en dirección 5' 3' en trozos de unos 1 000 nucleótidos, llamados fragmentos de Okazaki. Estos fragmentos necesitan un ARN cebador que, posteriormente, será degradado y los fragmentos unidos por los ADN ligasas.
52.- Las mutaciones génicas son aquellas que afectan a un único gen. ¿Qué causas provocan las mutaciones génicas? ¿Qué es una mutación puntual? ¿Puede este tipo de mutaciones explicar la aparición de nuevos alelos?
Las mutaciones génicas son lesiones o alteraciones en el ADN que se producen de forma espontánea (mutaciones espontáneas), o bien por efecto de las condiciones ambientales (mutaciones inducidas). Las mutaciones espontáneas surgen en cualquier tipo de célula y en cualquier momento. Pueden producirse por las siguientes causas: Errores en la replicación. Lesiones en el ADN (desaminaciones, despurinizaciones y oxidaciones). La acción de elementos transponibles. Las mutaciones inducidas se producen cuando un organismo está sometido a la acción de agentes mutágenos específicos. Estos pueden ser: agentes físicos, como la radiación UV o las radiaciones ionizantes, o agentes químicos, como los análogos de bases o los agentes alquilantes. Una mutación puntual es una mutación génica que afecta a un único par de nuleótidos. Por ejemplo: el cambio de un par A -T por el par G - C. Las mutaciones puntuales afectan a la secuencia del gen y pueden, por tanto, modificar la proteína que codifica. En algunos casos son la causa de enfermedades genéticas. Por ejemplo, la anemia falciforme es una enfermedad que se origina por una mutación en el gen que codifica las cadenas beta de la hemoglobina. La mutación provoca la sustitución de un ácido glutámico por una valina en la secuencia de aminoácidos. Los alelos son las distintas formas en las que puede encontrarse un gen dentro de una población. La alteración de la secuencia de bases de un gen, por efecto de una mutación, conduce a la aparición de nuevas variantes que originan las series alélicas. Por tanto, las mutaciones génicas son la causa de la aparición de nuevos alelos.
Las mutaciones génicas son lesiones o alteraciones en el ADN que se producen de forma espontánea (mutaciones espontáneas), o bien por efecto de las condiciones ambientales (mutaciones inducidas). Las mutaciones espontáneas surgen en cualquier tipo de célula y en cualquier momento. Pueden producirse por las siguientes causas: Errores en la replicación. Lesiones en el ADN (desaminaciones, despurinizaciones y oxidaciones). La acción de elementos transponibles. Las mutaciones inducidas se producen cuando un organismo está sometido a la acción de agentes mutágenos específicos. Estos pueden ser: agentes físicos, como la radiación UV o las radiaciones ionizantes, o agentes químicos, como los análogos de bases o los agentes alquilantes. Una mutación puntual es una mutación génica que afecta a un único par de nuleótidos. Por ejemplo: el cambio de un par A -T por el par G - C. Las mutaciones puntuales afectan a la secuencia del gen y pueden, por tanto, modificar la proteína que codifica. En algunos casos son la causa de enfermedades genéticas. Por ejemplo, la anemia falciforme es una enfermedad que se origina por una mutación en el gen que codifica las cadenas beta de la hemoglobina. La mutación provoca la sustitución de un ácido glutámico por una valina en la secuencia de aminoácidos. Los alelos son las distintas formas en las que puede encontrarse un gen dentro de una población. La alteración de la secuencia de bases de un gen, por efecto de una mutación, conduce a la aparición de nuevas variantes que originan las series alélicas. Por tanto, las mutaciones génicas son la causa de la aparición de nuevos alelos.
53.- Los errores en la replicación son una de las causas que producen alteraciones en el ADN de forma espontánea. Describe y representa gráficamente cómo se originan estos cambios.
Los errores en la replicación se generan como consecuencia de apareamientos incorrectos, que conducen a la aparición de varios tipos de mutaciones: Sustitución de una base por otra; dicha sustitución puede ser de dos tipos: Transición: es el cambio de una base por otra del mismo tipo, púrica por púrica o pirimidínica por pirimidínica. Transversión: supone el cambio de una base púrica por una pirimidínica, o viceversa. Inserciones. Consisten en que la secuencia lineal de bases se modifica porque se introducen uno o más pares de bases en algún lugar de la molécula. Delecciones. Suponen la pérdida de un fragmento del gen constituido por uno o más nucleótidos. Duplicaciones. Son repeticiones de una secuencia del gen. Inversiones. Se producen cuando una secuencia de nucleótidos sufre un giro de 180. Las mutaciones génicas pueden suceder en cualquier zona de la molécula de ADN, pero son mucho más frecuentes en los llamados puntos calientes.
Los errores en la replicación se generan como consecuencia de apareamientos incorrectos, que conducen a la aparición de varios tipos de mutaciones: Sustitución de una base por otra; dicha sustitución puede ser de dos tipos: Transición: es el cambio de una base por otra del mismo tipo, púrica por púrica o pirimidínica por pirimidínica. Transversión: supone el cambio de una base púrica por una pirimidínica, o viceversa. Inserciones. Consisten en que la secuencia lineal de bases se modifica porque se introducen uno o más pares de bases en algún lugar de la molécula. Delecciones. Suponen la pérdida de un fragmento del gen constituido por uno o más nucleótidos. Duplicaciones. Son repeticiones de una secuencia del gen. Inversiones. Se producen cuando una secuencia de nucleótidos sufre un giro de 180. Las mutaciones génicas pueden suceder en cualquier zona de la molécula de ADN, pero son mucho más frecuentes en los llamados puntos calientes.
54.- ¿Cómo actúa el sistema de reparación SOS?; ¿cuáles son las consecuencias de su acción?
Algunos agentes mutágenos, como la radiación UV, la aflatoxina B1 o el benzopireno, producen lesiones en el ADN que interrumpen la replicación. El bloqueo puede llegar a producir la muerte de la célula si no se pone en marcha el sistema de reparación de emergencia: el SOS. El sistema SOS desbloquea la replicación, eliminando la lesión producida en el ADN, pero su actuación implica la relajación en la especificidad del apareamiento, al rellenar el hueco creado. De todos modos, consigue que la replicación continúe. El sistema SOS se emplea como último recurso y puede considerarse como un factor de mutación, puesto que convierte un agente bloqueante en un mutágeno.
Algunos agentes mutágenos, como la radiación UV, la aflatoxina B1 o el benzopireno, producen lesiones en el ADN que interrumpen la replicación. El bloqueo puede llegar a producir la muerte de la célula si no se pone en marcha el sistema de reparación de emergencia: el SOS. El sistema SOS desbloquea la replicación, eliminando la lesión producida en el ADN, pero su actuación implica la relajación en la especificidad del apareamiento, al rellenar el hueco creado. De todos modos, consigue que la replicación continúe. El sistema SOS se emplea como último recurso y puede considerarse como un factor de mutación, puesto que convierte un agente bloqueante en un mutágeno.
55.- Explica la relación entre los transposones y la conjugación bacteriana.
La conjugación bacteriana es un proceso en el que una parte de una hebra del cromosoma de una bacteria dadora, denominada célula F+ o (+), ya que es protadora de un factor sexual F, se transfiere al interior de una célula receptora, denominada F- o (-), que carece del factor F, a través de tubos de conexión llamados pili. El factor F puede encontrarse recombinado en el cromosoma de la bacteria o situado en pequeñas moléculas de ADN, denominadas plásmidos. Estos plásmidos son capaces de insertarse en el cromosoma principal, ya que actúan como elementos transponibles que presentan secuencias de inserción junto con otros genes. La presencia del factor F permite que, al producirse la conjugación, el fragmento de ADN donado se inserte en el cromosoma de la célula receptora. Esta inserción es posible gracias a la presencia de secuencias de inserción específicas, características de los elementos transponibles.
La conjugación bacteriana es un proceso en el que una parte de una hebra del cromosoma de una bacteria dadora, denominada célula F+ o (+), ya que es protadora de un factor sexual F, se transfiere al interior de una célula receptora, denominada F- o (-), que carece del factor F, a través de tubos de conexión llamados pili. El factor F puede encontrarse recombinado en el cromosoma de la bacteria o situado en pequeñas moléculas de ADN, denominadas plásmidos. Estos plásmidos son capaces de insertarse en el cromosoma principal, ya que actúan como elementos transponibles que presentan secuencias de inserción junto con otros genes. La presencia del factor F permite que, al producirse la conjugación, el fragmento de ADN donado se inserte en el cromosoma de la célula receptora. Esta inserción es posible gracias a la presencia de secuencias de inserción específicas, características de los elementos transponibles.
56.- ¿Cuáles son las fuentes de variabilidad sobre las que actúa la selección natural?
Las fuentes de variación sobre las que actúa la evolución son: la mutación, la recombinación y la transposición. La mutación es la fuente primaria de variación, produce modificaciones en las secuencias de bases del ADN que originan la aparición de nuevos genes (alelos). La recombinación y la transposición incrementan la velocidad de la evolución y, aunque no provocan la aparición de nuevos genes, aumentan el número de combinaciones distintas de estos. La recombinación supone la aparición de nuevas combinaciones en las células germinales formadas durante la meiosis. La transposición origina nuevos ordenamientos, tanto en los cromosomas de eucariontes como en los de procariontes. Recombinación y transposición son la fuente de variación secundaria sobre la que actúa la evolución.
Las fuentes de variación sobre las que actúa la evolución son: la mutación, la recombinación y la transposición. La mutación es la fuente primaria de variación, produce modificaciones en las secuencias de bases del ADN que originan la aparición de nuevos genes (alelos). La recombinación y la transposición incrementan la velocidad de la evolución y, aunque no provocan la aparición de nuevos genes, aumentan el número de combinaciones distintas de estos. La recombinación supone la aparición de nuevas combinaciones en las células germinales formadas durante la meiosis. La transposición origina nuevos ordenamientos, tanto en los cromosomas de eucariontes como en los de procariontes. Recombinación y transposición son la fuente de variación secundaria sobre la que actúa la evolución.
57.- Enzimas de restricción: a) Concepto y mecanismo de acción. b) Comenta un ejemplo. c) Explica sus aplicaciones en la tecnología del ADN recombinante.
a) Los enzimas de restricción son aquellos que cortan el ADN por unas secuencias específicas, generalmente, constituidas por 4 u 8 pares de bases. Estos puntos de corte se llaman secuencias de reconocimiento. Algunos de estos enzimas cortan cada cadena en lugares separados por algunos nucleótidos y, como resultado, aparecen secuencias de ADN de una sola hebra en los extremos de corte. Estos extremos se denominan pegajosos, puesto que pueden unirse de nuevo, restableciéndose espontáneamente los puentes de hidrógeno entre las bases complementarias.
a) Los enzimas de restricción son aquellos que cortan el ADN por unas secuencias específicas, generalmente, constituidas por 4 u 8 pares de bases. Estos puntos de corte se llaman secuencias de reconocimiento. Algunos de estos enzimas cortan cada cadena en lugares separados por algunos nucleótidos y, como resultado, aparecen secuencias de ADN de una sola hebra en los extremos de corte. Estos extremos se denominan pegajosos, puesto que pueden unirse de nuevo, restableciéndose espontáneamente los puentes de hidrógeno entre las bases complementarias.
b) Se conocen centenares de enzimas de restricción. Uno de los más utlizados es el EcoRI, que corta el AND.
c) Los enzimas de restricción permiten unir extremos pegajosos, procedentes de cualquier molécula de ADN (incluso de especies distintas), que hayan sido cortados por el mismo enzima. De esta forma, se pueden sintetizar moléculas de ADN recombinante, como pueden ser plásmidos, que contengan genes humanos.
58.- Contesta a las siguientes cuestiones relacionadas con la replicación: a) Concepto de replicación. b) Tras el descubrimiento de la estructura del ADN, ¿qué modelos se plantearon para explicar la replicación?; ¿cuál de ellos es el correcto? c) En la replicación de una molécula de ADN de doble hebra y después de tres ciclos de replicación, ¿cuántas hebras de nueva síntesis habrán aparecido?
a) La replicación consiste en la síntesis de una copia de una molécula de ADN; es decir, a partir de una molécula de ADN se obtendrán dos moléculas idénticas. Este proceso está relacionado con la reproducción y ocurre en la fase S del ciclo celular. De esta forma, después de que ha tenido lugar la división celular, cada célula hija posee la misma información genética.
a) La replicación consiste en la síntesis de una copia de una molécula de ADN; es decir, a partir de una molécula de ADN se obtendrán dos moléculas idénticas. Este proceso está relacionado con la reproducción y ocurre en la fase S del ciclo celular. De esta forma, después de que ha tenido lugar la división celular, cada célula hija posee la misma información genética.
b) Una vez descubierta la estructura del ADN, se plantearon tres hipótesis para tratar de explicar el mecanismo de la replicación: Conservativa. Según esta hipótesis, las dos cadenas de la doble hélice hija se sintetizan de nuevo a partir del molde de la parental, que permanece. Dispersiva. Según esta hipótesis, las dos cadenas tendrían fragmentos de la cadena antigua y fragmentos recién sintetizados. Semiconservativa. La molécula de ADN se separa en sus dos hebras y cada una de ellas sirve de molde para la síntesis de su complementaria. De esta forma, las dobles hélices resultantes contienen una hebra antigua o parental y una de nueva síntesis. La hipótesis semiconservativa es el modelo de replicación confirmado, tanto en eucariontes como en procariontes.
c) Al ser la replicación un proceso semiconservativo, después de tres ciclos de replicación se formarán catorce hebras de nueva síntesis, tal como se muestra en el esquema.
59.- Define el concepto de mutación y clasifica los distintos tipos de mutaciones.
Una mutación es un cambio heredable y medible del material genético. Las mutaciones pueden afectar a cualquier tipo de células, pero solamente se transmitirán a la descendencia aquellas mutaciones que se produzcan en los gametos o en células embrionarias que den lugar a gametos. Podemos distinguir dos grandes tipos de mutaciones: Génicas: Afectan solo a un gen o a un número pequeño de genes. Son mutaciones que provocan un cambio en la secuencia de nucleótidos del ADN. Estos cambios pueden ser la sustitución de un o unos nucleótidos por otros, la inversión, inserción o deleción (pérdida) de uno o varios nucleótidos. Cromosómicas. Suponen un cambio en la estructura o en el número de los cromosomas. Pueden ser: Estructurales: Cuando afectan a la ordenación de los genes de uno o varios cromosomas. Modifican los grupos de ligamiento. Numéricas: Suponen una alteración del número de cromosomas o de juegos cromosómicos.
Una mutación es un cambio heredable y medible del material genético. Las mutaciones pueden afectar a cualquier tipo de células, pero solamente se transmitirán a la descendencia aquellas mutaciones que se produzcan en los gametos o en células embrionarias que den lugar a gametos. Podemos distinguir dos grandes tipos de mutaciones: Génicas: Afectan solo a un gen o a un número pequeño de genes. Son mutaciones que provocan un cambio en la secuencia de nucleótidos del ADN. Estos cambios pueden ser la sustitución de un o unos nucleótidos por otros, la inversión, inserción o deleción (pérdida) de uno o varios nucleótidos. Cromosómicas. Suponen un cambio en la estructura o en el número de los cromosomas. Pueden ser: Estructurales: Cuando afectan a la ordenación de los genes de uno o varios cromosomas. Modifican los grupos de ligamiento. Numéricas: Suponen una alteración del número de cromosomas o de juegos cromosómicos.
60.- Explica la forma de actuación de un mutágeno físico y otro químico y represéntalo esquemáticamente.
La radiación ultravioleta es un mutágeno físico que induce la formación de dímeros de pirimidinas (especialmente, de timina). Este tipo de mutación impide el apareamiento específico de las bases, produciendo la interrupción de la replicación. El bloqueo de la replicación pone en funcionamiento el sistema de repación SOS, que promueve la inserción de bases con muy poca fidelidad, pero que permite que la replicación continúe. La 2-aminopurina es un análogo de la adenina. Esta molécula se aparea con la citosina, originando una transición G -C A -T.
Supongamos que en una molécula de ADN se produce un dímero de timina por acción de la radiación UV. ¿De qué mecanismos dispone la célula para su reparación? Los dímeros de timina formados por la luz UV pueden ser subsanados por dos mecanismos de reparación, dependiendo de la situación en la que se encuentre la célula: En presencia de luz, la reparación la realiza el enzima endonucleasa ultravioleta, que se activa por la luz (enzima fotorreactivo). Este enzima debe absorber un fotón para poder deshacer el dímero en dos monómeros. En ausencia de luz, existe una vía alternativa, que es la reparación por escisión. En este caso, una endonucleasa escinde un segmento de10 a 100 nucleótidos a ambos lados del dímero. Posteriormente, la ADN polimerasa I y la ligasa rellenan el hueco. Durante la replicación la aparición de dímeros de timina bloquea el proceso. Esta circunstancia pone en marcha el mecanismo SOS o de emergencia. Este sistema de reparación desbloquea la replicación, pero promueve inserciones de bases reduciendo la fidelidad, lo que supone la aparición de mutaciones.
La radiación ultravioleta es un mutágeno físico que induce la formación de dímeros de pirimidinas (especialmente, de timina). Este tipo de mutación impide el apareamiento específico de las bases, produciendo la interrupción de la replicación. El bloqueo de la replicación pone en funcionamiento el sistema de repación SOS, que promueve la inserción de bases con muy poca fidelidad, pero que permite que la replicación continúe. La 2-aminopurina es un análogo de la adenina. Esta molécula se aparea con la citosina, originando una transición G -C A -T.
Supongamos que en una molécula de ADN se produce un dímero de timina por acción de la radiación UV. ¿De qué mecanismos dispone la célula para su reparación? Los dímeros de timina formados por la luz UV pueden ser subsanados por dos mecanismos de reparación, dependiendo de la situación en la que se encuentre la célula: En presencia de luz, la reparación la realiza el enzima endonucleasa ultravioleta, que se activa por la luz (enzima fotorreactivo). Este enzima debe absorber un fotón para poder deshacer el dímero en dos monómeros. En ausencia de luz, existe una vía alternativa, que es la reparación por escisión. En este caso, una endonucleasa escinde un segmento de
61.- Define recombinación y transposición. ¿Qué diferencias existen entre estos procesos y la mutación, en cuanto a sus consecuencias genéticas?
La recombinación consiste en la aparición de nuevas combinaciones de genes, que van a ser diferentes de las que se encuentran en los cromosomas de una célula determinada. Las nuevas combinaciones surgen por el intercambio de fragmentos de ADN entre los cromosomas, durante el proceso llamado sobrecruzamiento. Durante la recombinación no se pierde ni se gana ningún nucleótido, por lo que el mecanismo molecular de intercambio es muy preciso. La transposición es un mecanismo de cambio genético que se debe al desplazamiento de genes (fragmentos de ADN) dentro del mismo cromosoma o de un cromosoma a otro. Los fragmentos de ADN que se desplazan se denominan elementos genéticos transponibles o transposones, y han sido observados tanto en procariontes como en eucariontes. Tanto la recombinación como la transposición provocan la aparición de nuevas combinaciones de genes en los cromosomas de una especie determinada. Sin embargo, la mutación origina la aparición de nuevos genes en una población por la modificación de la secuencia de bases del ADN.
La recombinación consiste en la aparición de nuevas combinaciones de genes, que van a ser diferentes de las que se encuentran en los cromosomas de una célula determinada. Las nuevas combinaciones surgen por el intercambio de fragmentos de ADN entre los cromosomas, durante el proceso llamado sobrecruzamiento. Durante la recombinación no se pierde ni se gana ningún nucleótido, por lo que el mecanismo molecular de intercambio es muy preciso. La transposición es un mecanismo de cambio genético que se debe al desplazamiento de genes (fragmentos de ADN) dentro del mismo cromosoma o de un cromosoma a otro. Los fragmentos de ADN que se desplazan se denominan elementos genéticos transponibles o transposones, y han sido observados tanto en procariontes como en eucariontes. Tanto la recombinación como la transposición provocan la aparición de nuevas combinaciones de genes en los cromosomas de una especie determinada. Sin embargo, la mutación origina la aparición de nuevos genes en una población por la modificación de la secuencia de bases del ADN.
62.- Justifica la siguiente frase: Sin mutación no se hubiera producido el hecho evolutivo, pero sin recombinación, sí.
La mutación es la fuente primaria de variación, produce modificaciones en las secuencias de bases del ADN que originan la aparición de nuevos genes (alelos). En los organismos resulta beneficiosa para su evolución la ocurrencia de mutaciones, ya que aumenta la variabilidad genética en las poblaciones y le permite responder con mayor plasticidad ante condiciones ambientales cambiantes. Sin embargo, el mecanismo de la recombinación genética no conduce a la aparición de nuevos genes, pero crea nuevas combinaciones de estos, que permiten potenciar al máximo la variabilidad genética debida al fenómeno de la mutación. Esto no quiere decir que las nuevas combinaciones genéticas no se pudieran producir por mutación; lo que sucede es que la recombinación aumenta la velocidad con la que el nuevo espectro genético se extenderá por la población. En resumen, sin mutación no existiría el fenómeno evolutivo, pero sin recombinación, sí, aunque hubiera sido mucho más lenta.
La mutación es la fuente primaria de variación, produce modificaciones en las secuencias de bases del ADN que originan la aparición de nuevos genes (alelos). En los organismos resulta beneficiosa para su evolución la ocurrencia de mutaciones, ya que aumenta la variabilidad genética en las poblaciones y le permite responder con mayor plasticidad ante condiciones ambientales cambiantes. Sin embargo, el mecanismo de la recombinación genética no conduce a la aparición de nuevos genes, pero crea nuevas combinaciones de estos, que permiten potenciar al máximo la variabilidad genética debida al fenómeno de la mutación. Esto no quiere decir que las nuevas combinaciones genéticas no se pudieran producir por mutación; lo que sucede es que la recombinación aumenta la velocidad con la que el nuevo espectro genético se extenderá por la población. En resumen, sin mutación no existiría el fenómeno evolutivo, pero sin recombinación, sí, aunque hubiera sido mucho más lenta.
63.- ¿Cómo construirías una molécula de ADN recombinante?
Una molécula de ADN recombinante es aquella que contiene fragmentos no homólogos que pueden proceder incluso de organismos distintos. Las moléculas de ADN recombinante suelen contener un vector y el gen o los genes de interés. Supongamos que se quiere construir una molécula que utilice un plásmido como vector y un gen objeto de estudio. El proceso sería el siguiente: 1.- El plásmido se corta con un enzima de restricción, quedando abierto y con los extremos pegajosos expuestos en sus extremos. 2.- A continuación, se ponen en contacto el plásmido abierto con el gen objeto de estudio que, también, ha sido cortado por el mismo enzima de restricción. 3.- Las dos moléculas se funden por sus extremos pegajosos, obteniéndose plásmidos recombinantes que contienen el gen de interés y la información genética del plásmido. 4.- Posteriormente, la molécula de ADN recombinante puede clonarse para amplificar las copias del gen. Para ello, los plásmidos recombinantes se colocan en un medio de cultivo con bacterias, incorporándose a algunas células bacterianas. Cuando estas células se dividen, los plásmidos recombinantes se replican, incrementándose rápidamente el número de células que contienen el gen objeto de estudio. 5.- Por último, los plásmidos pueden aislarse y ser tratados con el mismo enzima de restricción, para recuperar las copias del gen clonado.
Una molécula de ADN recombinante es aquella que contiene fragmentos no homólogos que pueden proceder incluso de organismos distintos. Las moléculas de ADN recombinante suelen contener un vector y el gen o los genes de interés. Supongamos que se quiere construir una molécula que utilice un plásmido como vector y un gen objeto de estudio. El proceso sería el siguiente: 1.- El plásmido se corta con un enzima de restricción, quedando abierto y con los extremos pegajosos expuestos en sus extremos. 2.- A continuación, se ponen en contacto el plásmido abierto con el gen objeto de estudio que, también, ha sido cortado por el mismo enzima de restricción. 3.- Las dos moléculas se funden por sus extremos pegajosos, obteniéndose plásmidos recombinantes que contienen el gen de interés y la información genética del plásmido. 4.- Posteriormente, la molécula de ADN recombinante puede clonarse para amplificar las copias del gen. Para ello, los plásmidos recombinantes se colocan en un medio de cultivo con bacterias, incorporándose a algunas células bacterianas. Cuando estas células se dividen, los plásmidos recombinantes se replican, incrementándose rápidamente el número de células que contienen el gen objeto de estudio. 5.- Por último, los plásmidos pueden aislarse y ser tratados con el mismo enzima de restricción, para recuperar las copias del gen clonado.
No hay comentarios:
Publicar un comentario