ÍNDICE
|
23. Relación estructura - función 24. Desnaturalización de las proteínas 25. Esquemas ácidos nucleicos 26. Presentaciones ácidos nucleicos 27. Introducción 28. Constituyentes químicos de los ácidos nucleicos 29. Nucleósidos 30. Nucleótidos 31. Funciones de los nucleótidos 32. Tipos de ácidos nucleicos 33. ADN. La doble hélice 34. Otras estructuras del ADN 35. Desnaturalización e hibridación del ADN 36. ARN. Estructura y tipos 37. Replicación del ADN 38. Resumen esquemático de las biomoléculas 39. Prácticas 40. Repaso 41. Cuestiones 42. Otras presentaciones 43. Vídeos |
1. Conocimientos previos
2. ESQUEMA LÍPIDOS


3. PRESENTACIONES LÍPIDOS


4. CONTENIDOS ANIMADOS

5. INTRODUCCIÓN
Las propiedades físicas de los ácidos grasos vienen determinadas en gran medida por la longitud y grado de insaturación de su cadena hidrocarbonada. Entre estas propiedades cabe destacar, por su importancia biológica, dos de ellas:
Los acilglicéridos son ésteres de la glicerina, un polialcohol de tres átomos de carbono, con los ácidos grasos.


Cuando la glicerina reacciona con tres ácidos grasos para dar lugar a un triacilglicérido se liberan tres moléculas de agua. Esta reacción de esterificación es reversible en determinadas condiciones, es decir, los triacilglicéridos pueden sufrir hidrólisis cuando reaccionan con el agua para rendir de nuevo la glicerina y los ácidos grasos libres, tal y como sucede durante la digestión de las grasas en el intestino delgado por acción de la lipasa pancreática.
Por otra parte, los triacilglicéridos pueden sufrir saponificación cuando reaccionan con álcalis como el hidróxido sódico para dar lugar a la glicerina libre y a las correspondientes sales sódicas de los ácidos grasos que se conocen con el nombre de jabones. Esta reacción no es exclusiva de los triacilglicéridos, sino que la sufren en general todos los lípidos que contienen ácidos grasos unidos, mediante enlace éster o similar, a otro componente; por ello, el carácter saponificable o no de los distintos tipos de lípidos se utiliza como criterio para clasificarlos. La reacción de saponificación se utiliza industrialmente en la fabricación de jabones.

Los triacilglicéridos pueden ser simples, si contienen un sólo tipo de ácido graso, o mixtos, si contienen más de un tipo. Los triacilglicéridos naturales suelen ser mezclas complejas de triacilglicéridos simples y mixtos. Por otra parte, los triacilglicéridos ricos en ácidos grasos saturados se encuentran en estado sólido a temperatura ambiente y se denominan sebos, mientras que los ricos en ácidos grasos insaturados permanecen líquidos a temperatura ambiente y se denominan aceites.

La polaridad típica de los grupos hidroxilo de la glicerina y carboxilo de los ácidos grasos desaparece por completo cuando éstos reaccionan para formar un enlace éster. Por ello, aunque la glicerina es una sustancia polar y los ácidos grasos son sustancias anfipáticas, los triacilglicéridos son totalmente apolares y por lo tanto insolubles en agua. Esta insolubilidad se pone claramente de manifiesto en las mezclas agua-aceite, que presentan dos fases completamente separadas.


Al igual que los triacilglicéridos, los céridos son sustancias netamente hidrofóbicas y por lo tanto insolubles en agua. Esta insolubilidad en agua junto con su elevada consistencia constituyen la base físico-química de su principal función biológica que consiste en actuar como sustancias impermeabilizantes. Así, ciertas glándulas de la piel de los vertebrados secretan ceras para proteger el pelo y la piel manteniéndolos flexibles, lubricados e impermeables; los pájaros, especialmente las aves acuáticas, secretan ceras gracias a las cuales sus plumas pueden repeler el agua; en muchas plantas, sobre todo las que viven en ambientes secos, las hojas y los frutos están protegidas contra la excesiva evaporación de agua por películas céreas que les dan además un aspecto brillante característico.
Los fosfoglicéridos son sustancias anfipáticas: tienen en su molécula una parte no polar, representada por las cadenas hidrocarbonadas de los dos ácidos grasos y el esqueleto de la glicerina, y una parte polar formada por el ácido fosfórico y el compuesto polar. Es habitual representar a los fosfoglicéridos mediante una "cabeza" polar y dos "colas" no polares.
El carácter anfipático de los fosfoglicéridos constituye la base físico-química de su principal función biológica, que es la de ser componentes esenciales de las membranas celulares. Otras sustancias anfipáticas más simples, como los ácidos grasos, son de forma aproximadamente cónica, por lo que tienden a formar micelas en medio acuoso; sin embargo, los fosfoglicéridos, por tener dos "colas" hidrocarbonadas, son de forma aproximadamente cilíndrica, y por ello tienden a formar en medio acuoso estructuras más complejas como las bicapas, las cuales a su vez pueden doblarse sobre sí mismas dando lugar a estructuras cerradas, con un compartimiento acuoso interior, que se denominan liposomas.
La estructura de las membranas celulares está basada en una bicapa formada por lípidos con carácter anfipático. Es probable que las primeras células que existieron en el océano primitivo se parecieran mucho a los liposomas, estando aisladas de su entorno por una simple bicapa lipídica que posteriormente evolucionó dando lugar a las actuales membranas.


10. ESFINGOLÍPIDOS
Los esfingolípidos son un grupo de lípidos que contienen formando parte de su molécula al aminoalcohol graso llamado esfingosina. El grupo amino de la esfingosina puede reaccionar con el grupo carboxilo de un ácido graso para formar entre ellos un enlace tipo amida dando lugar a un compuesto denominado ceramida, que es la base estructural común de todos los esfingolípidos de manera análoga a como el ácido fosfatídico lo es de los fosfoglicéridos.
Los distintos tipos de esfingolípidos se obtienen mediante la unión de la ceramida con distintos tipos de compuestos de naturaleza polar. Hay dos tipos principales de esfingolípidos: los esfingofosfátidos y los glucoesfingolípidos.







Los steroles actúa como precursor de un amplio grupo de sustancias con actividades biológicas importantes entre las que cabe citar:



3. PRESENTACIONES LÍPIDOS
4. CONTENIDOS ANIMADOS
5. INTRODUCCIÓN
Así como para otras biomoléculas resulta fácil establecer una definición desde el punto de vista químico, en el caso de los lípidos esta tarea entraña una mayor dificultad, ya que constituyen un grupo de sustancias químicamente muy heterogéneo que no se caracteriza, como otras biomoléculas, por la posesión de un determinado conjunto de grupos funcionales.
Por ello, resulta mucho más conveniente identificarlos sobre la base de una de sus propiedades físicas: su mayor o menor solubilidad en distintos tipos de disolventes.
Así, se considera que los lípidos son un grupo de biomoléculas que se caracterizan por ser poco o nada solubles en agua y, por el contrario, muy solubles en disolventes orgánicos no polares. Aunque químicamente heterogéneos, todos presenten un denominador común estructural: la totalidad, o al menos una parte significativa, de su molécula es de naturaleza hidrocarbonada, y por lo tanto apolar. Este rasgo estructural común es el responsable de su insolubilidad en agua y de su solubilidad en disolventes no polares. Los lípidos desempeñan en las células vivas una gran variedad de funciones, entre las que destacan las de carácter energético y estructural.
La clasificación de los lípidos también resulta problemática, dadas las características químicas tan diversas que poseen. Adoptaremos una de las más comunes, que divide a los lípidos en dos grandes categorías: lípidos saponificables, que contienen ácidos grasos unidos a algún otro componente, generalmente mediante un enlace tipo éster, y lípidos no saponificables, que no contienen ácidos grasos, aunque también incluyen algunos derivados importantes de éstos.
Por ello, resulta mucho más conveniente identificarlos sobre la base de una de sus propiedades físicas: su mayor o menor solubilidad en distintos tipos de disolventes.
Así, se considera que los lípidos son un grupo de biomoléculas que se caracterizan por ser poco o nada solubles en agua y, por el contrario, muy solubles en disolventes orgánicos no polares. Aunque químicamente heterogéneos, todos presenten un denominador común estructural: la totalidad, o al menos una parte significativa, de su molécula es de naturaleza hidrocarbonada, y por lo tanto apolar. Este rasgo estructural común es el responsable de su insolubilidad en agua y de su solubilidad en disolventes no polares. Los lípidos desempeñan en las células vivas una gran variedad de funciones, entre las que destacan las de carácter energético y estructural.
La clasificación de los lípidos también resulta problemática, dadas las características químicas tan diversas que poseen. Adoptaremos una de las más comunes, que divide a los lípidos en dos grandes categorías: lípidos saponificables, que contienen ácidos grasos unidos a algún otro componente, generalmente mediante un enlace tipo éster, y lípidos no saponificables, que no contienen ácidos grasos, aunque también incluyen algunos derivados importantes de éstos.
Aunque la mayoría de los lípidos tienen pesos moleculares relativamente bajos, se suelen incluir, de una manera un tanto arbitraria, entre las macromoléculas. Debemos recordar que las macromoléculas están formadas por unidades monoméricas relativamente simples llamadas sillares estructurales. Las unidades monoméricas o sillares estructurales que con más frecuencia aparecen formando parte de los lípidos, aunque no están presentes en todos ellos, son los ácidos grasos. En la anterior clasificación no se han incluido los ácidos grasos, ya que éstos apenas se encuentran en la naturaleza en estado libre, sino formando parte de distintos tipos de lípidos.

6. LOS ÁCIDOS GRASOS
Los ácidos grasos son compuestos orgánicos que poseen un grupo funcional carboxilo y una cadena hidrocarbonada larga que puede tener entre 4 y 36 átomos de carbono. La mayoría de los ácidos grasos naturales tiene un número par de átomos de carbono que oscila entre 12 y 24, siendo especialmente abundantes los de 16 y 18. El predominio de los ácidos grasos con número par de átomos de carbono se debe a que estos compuestos se sintetizan en las células a partir de unidades de dos carbonos. En la Tabla aparecen los ácidos grasos naturales más importantes.
| Nombre trivial | Nº de átomosde carbono | Estructura | Puntode fusión |
| Ácidos grasos saturados | |||
| Ácido láurico | 12 | CH3-(CH2)10-COOH | 44,2 |
| Ácido mirístico | 14 | CH3-(CH2)12-COOH | 54,0 |
| Ácido palmítico | 16 | CH3-(CH2)14-COOH | 63,0 |
| Ácido esteárico | 18 | CH3-(CH2)16-COOH | 69,6 |
| Ácido araquídico | 20 | CH3-(CH2)18-COOH | 76,5 |
| Ácido lignocérico | 24 | CH3-(CH2)22-COOH | 86,0 |
| Ácidos grasos insaturados | |||
| Ácido palmitoleico | 16 | CH3-(CH2)5-CH=CH-(CH2)7-COOH | -0,5 |
| Ácido oleico | 18 | CH3-(CH2)7-CH=CH-(CH2)7-COOH | 13,4 |
| Ácido linoleico | 18 | CH3-(CH2)4-CH=CH-CH2-CH=CH-(CH2)7-COOH | -3,0 |
| Ácido linolénico | 18 | CH3-CH2-CH=CH-CH2-CH=CH-CH2-CH=CH-(CH2)7-COOH | -11,0 |
| Ácido araquidónico | 20 | CH3-(CH2)4-CH=CH-CH2-CH=CH-CH2-CH=CH-CH2-CH=CH-(CH2)3-COOH | -49,5 |
Existen dos tipos principales de ácidos grasos: los saturados, que no poseen dobles enlaces, y los insaturados, que poseen uno o más dobles enlaces a lo largo de su cadena hidrocarbonada . Entre los insaturados los más abundantes son monoinsaturados, con un solo doble enlace entre los carbonos 9 y 10. Los ácidos grasos poliinsaturados suelen tener un doble enlace entre los carbonos 9 y 10 y los dobles enlaces adicionales situados entre éste y el extremo metilo terminal de la cadena hidrocarbonada. La existencia de dobles enlaces implica la existencia de isómeros geométricos (cis-trans) según sea la disposición de los sustituyentes a ambos lados del doble enlace. La mayoría de los ácidos grasos insaturados que existen en la naturaleza presentan configuración cis.


La geometría tetraédrica de los orbitales del carbono determina que las cadenas hidrocarbonadas de los ácidos grasos adopten una característica disposición en zig-zag. Sin embargo, los ácidos grasos saturados e insaturados difieren significativamente en cuanto a la disposición espacial de sus cadenas hidrocarbonadas.
En los saturados, aunque la libre rotación de los sustituyentes alrededor de los enlaces sencillos proporciona una gran flexibilidad a la cadena, la conformación más estable es aquella en la que dicha cadena se encuentra lo más extendida posible, minimizando así las interacciones repulsivas entre átomos vecinos.
En los insaturados, por otra parte, la tendencia de la cadena hidrocarbonada a adoptar la conformación más extendida se ve limitada por la rigidez de los dobles enlaces, que impide que los distintos sustituyentes de los carbonos implicados en ellos puedan rotar a su alrededor. Esto determina la aparición de cambios de orientación en la dirección de la cadena hidrocarbonada de los ácidos grasos insaturados, no pudiendo adoptar ésta una conformación totalmente extendida.


En concreto, en los ácidos grasos cis-monoinsaturados, que son los más abundantes, la cadena presenta dos tramos rectilíneos, separados por un doble enlace, que forman entre sí un ángulo de unos 120º.
Los poliinsaturados presentan estructuras complejas con varios tramos rectilíneos separados por dobles enlaces. Los dobles enlaces trans (muy raros en la naturaleza) apenas determinan una ligera sinuosidad en la cadena sin que ello suponga un cambio significativo en la orientación de la misma: los ácidos grasos trans-insaturados presentan conformaciones espaciales muy similares a las de los saturados. Estas diferencias en cuanto a la conformación espacial de los distintos tipos de ácidos grasos influyen considerablemente en sus propiedades físicas y tienen notables implicaciones biológicas.



En los saturados, aunque la libre rotación de los sustituyentes alrededor de los enlaces sencillos proporciona una gran flexibilidad a la cadena, la conformación más estable es aquella en la que dicha cadena se encuentra lo más extendida posible, minimizando así las interacciones repulsivas entre átomos vecinos.
En los insaturados, por otra parte, la tendencia de la cadena hidrocarbonada a adoptar la conformación más extendida se ve limitada por la rigidez de los dobles enlaces, que impide que los distintos sustituyentes de los carbonos implicados en ellos puedan rotar a su alrededor. Esto determina la aparición de cambios de orientación en la dirección de la cadena hidrocarbonada de los ácidos grasos insaturados, no pudiendo adoptar ésta una conformación totalmente extendida.
En concreto, en los ácidos grasos cis-monoinsaturados, que son los más abundantes, la cadena presenta dos tramos rectilíneos, separados por un doble enlace, que forman entre sí un ángulo de unos 120º.
Los poliinsaturados presentan estructuras complejas con varios tramos rectilíneos separados por dobles enlaces. Los dobles enlaces trans (muy raros en la naturaleza) apenas determinan una ligera sinuosidad en la cadena sin que ello suponga un cambio significativo en la orientación de la misma: los ácidos grasos trans-insaturados presentan conformaciones espaciales muy similares a las de los saturados. Estas diferencias en cuanto a la conformación espacial de los distintos tipos de ácidos grasos influyen considerablemente en sus propiedades físicas y tienen notables implicaciones biológicas.
Las propiedades físicas de los ácidos grasos vienen determinadas en gran medida por la longitud y grado de insaturación de su cadena hidrocarbonada. Entre estas propiedades cabe destacar, por su importancia biológica, dos de ellas:
1) Punto de fusión. El punto de fusión de los ácidos grasos aumenta gradualmente con la longitud de su cadena hidrocarbonada. Cuando los ácidos grasos se solidifican sus moléculas se empaquetan formando un retículo regular en el que cada una de ellas se encuentra unida a sus vecinas mediante interacciones de Van der Waals entre las respectivas cadenas hidrocarbonadas. Cuanto más largas sean dichas cadenas mayor será el número de interacciones que se podrán establecer entre ellas y, por lo tanto, más cantidad de energía térmica habrá que emplear paran romperlas y pasar así del estado sólido al estado líquido, es decir, mayor será el punto de fusión.
Los ácidos grasos saturados tienen puntos de fusión significativamente mayores que los insaturados de igual número de átomos de carbono. Esto se debe a que la conformación extendida de los ácidos grasos saturados permite que sus moléculas se empaqueten muy estrechamente estableciéndose interacciones de Van der Waals todo a lo largo de sus cadenas hidrocarbonadas; por el contrario, los cambios de orientación existentes en las cadenas hidrocarbonadas de los ácidos grasos insaturados impiden que sus moléculas se empaqueten tan estrechamente dificultando la formación de interacciones de Van der Waals.
Así, al existir entre las cadenas hidrocarbonadas de los ácidos grasos saturados un mayor número de interacciones de Van der Waals , la energía térmica necesaria para romper estas interacciones es mayor, lo que se traduce en un mayor punto de fusión.
Así, al existir entre las cadenas hidrocarbonadas de los ácidos grasos saturados un mayor número de interacciones de Van der Waals , la energía térmica necesaria para romper estas interacciones es mayor, lo que se traduce en un mayor punto de fusión.
El punto de fusión de los ácidos grasos determina el de los lípidos que los contienen. Es muy importante que determinadas estructuras lipídicas, como las membranas celulares, permanezcan fluidas, y por ello los distintos tipos de organismos deben regular la composición en ácidos grasos de sus lípidos constituyentes. Así, en los vegetales y los animales poiquilotermos, que no mantienen una temperatura corporal constante, abundan los ácidos grasos insaturados, que tienen un punto de fusión bajo, mientras que los animales homeotermos, que mantienen una temperatura corporal constante y elevada, pueden recurrir en mayor medida a los ácidos grasos saturados sin correr el riesgo de que sus membranas "cristalicen" cuando la temperatura exterior es muy baja.
2) Comportamiento en disolución. Los ácidos grasos son sustancias anfipáticas: el grupo carboxilo, que a pH 7 se encuentra ionizado, es netamente polar, mientras que la cadena hidrocarbonada es totalmente no polar. Por lo tanto, en medio acuoso los ácidos grasos tenderán a formar micelas y otras estructuras afines.




7. ACILGLICÉRIDOS
Los acilglicéridos son ésteres de la glicerina, un polialcohol de tres átomos de carbono, con los ácidos grasos.
La glicerina (o glicerol) puede considerarse como un azúcar-alcohol que deriva biológicamente de la dihidroxiacetona (una cetotriosa); sus tres grupos hidroxilo pueden reaccionar con uno, con dos o con tres ácidos grasos para dar lugar respectivamente a los monoacilglicéridos, diacilglicéridos y triacilglicéridos.
Los mono~ y diacilglicéridos sólo aparecen en la naturaleza en pequeñas cantidades, generalmente como productos intermedios de la síntesis o degradación de los triacilglicéridos, que son mucho más abundantes y de mayor importancia biológica por lo que en lo sucesivo nos referiremos exclusivamente a ellos. En la siguiente animación se representa la reacción de esterificación, mediante la cual se obtiene una molécula de triacilglicérido a partir de una molécula de glicerina y tres de ácidos grasos.
Cuando la glicerina reacciona con tres ácidos grasos para dar lugar a un triacilglicérido se liberan tres moléculas de agua. Esta reacción de esterificación es reversible en determinadas condiciones, es decir, los triacilglicéridos pueden sufrir hidrólisis cuando reaccionan con el agua para rendir de nuevo la glicerina y los ácidos grasos libres, tal y como sucede durante la digestión de las grasas en el intestino delgado por acción de la lipasa pancreática.
Por otra parte, los triacilglicéridos pueden sufrir saponificación cuando reaccionan con álcalis como el hidróxido sódico para dar lugar a la glicerina libre y a las correspondientes sales sódicas de los ácidos grasos que se conocen con el nombre de jabones. Esta reacción no es exclusiva de los triacilglicéridos, sino que la sufren en general todos los lípidos que contienen ácidos grasos unidos, mediante enlace éster o similar, a otro componente; por ello, el carácter saponificable o no de los distintos tipos de lípidos se utiliza como criterio para clasificarlos. La reacción de saponificación se utiliza industrialmente en la fabricación de jabones.
Los triacilglicéridos pueden ser simples, si contienen un sólo tipo de ácido graso, o mixtos, si contienen más de un tipo. Los triacilglicéridos naturales suelen ser mezclas complejas de triacilglicéridos simples y mixtos. Por otra parte, los triacilglicéridos ricos en ácidos grasos saturados se encuentran en estado sólido a temperatura ambiente y se denominan sebos, mientras que los ricos en ácidos grasos insaturados permanecen líquidos a temperatura ambiente y se denominan aceites.
La polaridad típica de los grupos hidroxilo de la glicerina y carboxilo de los ácidos grasos desaparece por completo cuando éstos reaccionan para formar un enlace éster. Por ello, aunque la glicerina es una sustancia polar y los ácidos grasos son sustancias anfipáticas, los triacilglicéridos son totalmente apolares y por lo tanto insolubles en agua. Esta insolubilidad se pone claramente de manifiesto en las mezclas agua-aceite, que presentan dos fases completamente separadas.
La función de los triacilglicéridos en las células vivas es de naturaleza energética, constituyen depósitos de combustible metabólico rico en energía al que la célula puede recurrir en períodos en los que escasean los nutrientes procedentes de su entorno. Se almacenan en forma de gotículas microscópicas que forman un fase separada del citosol acuoso circundante.
Como sustancias de reserva los triacilglicéridos presentan dos ventajas significativas con respecto a los polisacáridos como el almidón o el glucógeno, que comparten con ellos esta función. En primer lugar, por ser sustancias altamente reducidas (o hidrogenadas), su oxidación libera más del doble de energía que una cantidad equivalente de glúcidos, que presentan un grado de oxidación mayor y por lo tanto no son tan ricos en energía. En segundo lugar, por ser sustancias hidrofóbicas, pueden almacenarse en forma anhidra, sin que el organismo tenga que soportar el peso adicional del agua de hidratación de los polisacáridos, mucho más hidrofílicos.
Por esta razón, los animales, que dependen en gran medida de la locomoción para desarrollar sus funciones vitales, recurren preferentemente a los lípidos como material de reserva, ya que la misma cantidad de energía en forma de polisacáridos hidratados dificultaría sus movimientos debido al exceso de peso; los vegetales, por ser estáticos, no tienen este problema, por lo que pueden recurrir en mayor medida a los polisacáridos para almacenar su combustible metabólico.
Como sustancias de reserva los triacilglicéridos presentan dos ventajas significativas con respecto a los polisacáridos como el almidón o el glucógeno, que comparten con ellos esta función. En primer lugar, por ser sustancias altamente reducidas (o hidrogenadas), su oxidación libera más del doble de energía que una cantidad equivalente de glúcidos, que presentan un grado de oxidación mayor y por lo tanto no son tan ricos en energía. En segundo lugar, por ser sustancias hidrofóbicas, pueden almacenarse en forma anhidra, sin que el organismo tenga que soportar el peso adicional del agua de hidratación de los polisacáridos, mucho más hidrofílicos.
Por esta razón, los animales, que dependen en gran medida de la locomoción para desarrollar sus funciones vitales, recurren preferentemente a los lípidos como material de reserva, ya que la misma cantidad de energía en forma de polisacáridos hidratados dificultaría sus movimientos debido al exceso de peso; los vegetales, por ser estáticos, no tienen este problema, por lo que pueden recurrir en mayor medida a los polisacáridos para almacenar su combustible metabólico.
En algunos animales los triacilglicéridos no actúan sólo como sustancias de reserva energética, sino que, por encontrarse almacenados preferentemente en el panículo adiposo existente bajo la piel, desempeñan también la función de aislante térmico para proteger al organismo de las bajas temperaturas.

8. CERAS
Los ceras son ésteres de los ácidos grasos con alcoholes monohidroxílicos de cadena larga (16 a 30 átomos de carbono), que también se denominan alcoholes grasos. El éster formado por el ácido palmítico (16 C) y el triacontanol (alcohol graso de 30 C) es el componente principal de la cera que fabrican las abejas. En la Figura se representa la reacción de esterificación mediante la cual se obtiene un cérido a partir de un ácido graso y un alcohol graso.
Al igual que los triacilglicéridos, los céridos son sustancias netamente hidrofóbicas y por lo tanto insolubles en agua. Esta insolubilidad en agua junto con su elevada consistencia constituyen la base físico-química de su principal función biológica que consiste en actuar como sustancias impermeabilizantes. Así, ciertas glándulas de la piel de los vertebrados secretan ceras para proteger el pelo y la piel manteniéndolos flexibles, lubricados e impermeables; los pájaros, especialmente las aves acuáticas, secretan ceras gracias a las cuales sus plumas pueden repeler el agua; en muchas plantas, sobre todo las que viven en ambientes secos, las hojas y los frutos están protegidas contra la excesiva evaporación de agua por películas céreas que les dan además un aspecto brillante característico.
Las ceras naturales tienen diversas aplicaciones en las industrias farmacéutica y cosmética.
9. FOSFOGLICÉRIDOS
Los fosfoglicéridos, son un grupo de lípidos con un denominador estructural común que es la molécula de ácido fosfatídico. El ácido fosfatídico está formado por una molécula de glicerina, dos ácidos grasos y una molécula de ácido fosfórico.
Los grupos hidroxilo de los átomos de carbono 1 y 2 de la glicerina están unidos mediante enlace éster a los dos ácidos grasos, el hidroxilo del carbono 3 está unido, también mediante enlace éster, al ácido fosfórico. El ácido fosfatídico apenas se encuentra como tal en la naturaleza, sino unido a través de su molécula de ácido fosfórico a diferentes compuestos de naturaleza polar, dando así lugar a los diferentes fosfoglicéridos. La unión entre el ácido fosfatídico y el compuesto polar también es de tipo éster.
Los fosfoglicéridos presentan una cierta similitud con los triacilglicéridos: se podría concebir un fosfoglicérido como un triacilglicérido en el que uno de los ácidos grasos ha sido sustituido por una molécula de ácido fosfórico y un compuesto polar unido a él. Los compuestos polares que forman parte de los fosfoglicéridos son de naturaleza variada; entre ellos cabe citar algunas bases nitrogenadas como la colina y la etanolamina, algún aminoácido como la serina, o el azúcar-alcohol cíclicoinositol. Todos ellos tienen en común su carácter acusadamente polar.


Los grupos hidroxilo de los átomos de carbono 1 y 2 de la glicerina están unidos mediante enlace éster a los dos ácidos grasos, el hidroxilo del carbono 3 está unido, también mediante enlace éster, al ácido fosfórico. El ácido fosfatídico apenas se encuentra como tal en la naturaleza, sino unido a través de su molécula de ácido fosfórico a diferentes compuestos de naturaleza polar, dando así lugar a los diferentes fosfoglicéridos. La unión entre el ácido fosfatídico y el compuesto polar también es de tipo éster.
Los fosfoglicéridos presentan una cierta similitud con los triacilglicéridos: se podría concebir un fosfoglicérido como un triacilglicérido en el que uno de los ácidos grasos ha sido sustituido por una molécula de ácido fosfórico y un compuesto polar unido a él. Los compuestos polares que forman parte de los fosfoglicéridos son de naturaleza variada; entre ellos cabe citar algunas bases nitrogenadas como la colina y la etanolamina, algún aminoácido como la serina, o el azúcar-alcohol cíclicoinositol. Todos ellos tienen en común su carácter acusadamente polar.
Los fosfoglicéridos son sustancias anfipáticas: tienen en su molécula una parte no polar, representada por las cadenas hidrocarbonadas de los dos ácidos grasos y el esqueleto de la glicerina, y una parte polar formada por el ácido fosfórico y el compuesto polar. Es habitual representar a los fosfoglicéridos mediante una "cabeza" polar y dos "colas" no polares.
El carácter anfipático de los fosfoglicéridos constituye la base físico-química de su principal función biológica, que es la de ser componentes esenciales de las membranas celulares. Otras sustancias anfipáticas más simples, como los ácidos grasos, son de forma aproximadamente cónica, por lo que tienden a formar micelas en medio acuoso; sin embargo, los fosfoglicéridos, por tener dos "colas" hidrocarbonadas, son de forma aproximadamente cilíndrica, y por ello tienden a formar en medio acuoso estructuras más complejas como las bicapas, las cuales a su vez pueden doblarse sobre sí mismas dando lugar a estructuras cerradas, con un compartimiento acuoso interior, que se denominan liposomas.
La estructura de las membranas celulares está basada en una bicapa formada por lípidos con carácter anfipático. Es probable que las primeras células que existieron en el océano primitivo se parecieran mucho a los liposomas, estando aisladas de su entorno por una simple bicapa lipídica que posteriormente evolucionó dando lugar a las actuales membranas.
10. ESFINGOLÍPIDOS
Los distintos tipos de esfingolípidos se obtienen mediante la unión de la ceramida con distintos tipos de compuestos de naturaleza polar. Hay dos tipos principales de esfingolípidos: los esfingofosfátidos y los glucoesfingolípidos.
1) Esfingofosfátidos. También llamados esfingomielinas. Se obtienen al unirse la ceramida mediante enlace éster a una molécula de ácido fosfórico y ésta a su vez, también mediante enlace éster, a una base nitrogenada de carácter polar como la colina o la etanolamina, también presentes en los fosfoglicéridos.
2) Glucoesfingolípidos. Se obtienen al unirse la ceramida a un azúcar mediante enlace glucosídico. Así pues, la unión de la ceramida al compuesto polar se realiza directamente y no a través de una molécula de ácido fosfórico como en los esfingofosfátidos; los glucoesfingolípidos no contienen fósforo. Se distinguen dos tipos de glucoesfingolípidos según la naturaleza del azúcar componente: los cerebrósidos, que incorporan un azúcar sencillo tal como la glucosa o la galactosa, y los gangliósidos, que incorporan azúcares complejos formados por varios monosacáridos y derivados de éstos unidos entre sí.


Los esfingolípidos presentan claras similitudes estructurales con los fosfoglicéridos: el papel del esqueleto de glicerina que éstos poseen es sustituido aquí por los tres primeros carbonos de la esfingosina; también presentan una "cabeza" polar (fosfato-base nitrogenada o azúcar) y dos "colas" no polares, que aquí corresponden a la cadena hidrocarbonada de la esfingosina y a la del ácido graso unido a ella.
Estas similitudes afectan también a sus propiedades: los esfingolípidos también presentan carácter anfipático y, por las mismas razones que los fosfoglicéridos, también son componentes esenciales de las membranas celulares. Abundan especialmente en las membranas de las células del tejido nervioso. Sin embargo, en los últimos años se ha descubierto que los esfingolípidos no son meros componentes estructurales de las membranas sino que tienen un importante papel en diversos procesos de reconocimiento de la superficie celular, por ejemplo, los determinantes de los grupos sanguíneos humanos (ABO) son glucoesfingolípidos. Por otra parte, diversas enfermedades graves que afectan al sistema nervioso están relacionadas con anomalías en el metabolismo de los esfingolípidos.
ANIMACIONES








11. TERPENOS
Los terpenos son un grupo de lípidos que no contienen ácidos grasos y son por lo tanto no saponificables. Están formados por la polimerización de un hidrocarburo de 5 átomos de carbono llamado isopreno (2-metil-1,3-butadieno). Los terpenos existentes en la naturaleza contienen un número variable de unidades de isopreno polimerizadas. Generalmente la "cabeza" de cada unidad de isopreno está unida con la "cola" de la siguiente. Debido a su naturaleza hidrocarbonada son sustancias netamente hidrofóbicas y por lo tanto insolubles en agua.
Son especialmente abundantes en el mundo vegetal. Gracias a que presentan un sistema de dobles enlaces conjugados tienen la propiedad de absorber luz de diferentes longitudes de onda, por lo que pueden actuar:
- Como pigmentos; así, algunos terpenos como los carotenos y xantofilas son los responsables de la coloración característica de muchos frutos
- El fitol, un alcohol terpenoide, forma parte de la clorofila, el pigmento vegetal por excelencia.
- Muchos aromas de origen vegetal, como el alcanfor, el mentol y el geraniol son de naturaleza terpenoide,
- Productos vegetales de interés económico como el caucho. La vitamina A, que deriva biológicamente de los carotenos, también es un terpeno.
12. ESTEROIDES
Los esteroides son un grupo de lípidos de estructura compleja que tampoco contienen ácidos grasos y por lo tanto también son no saponificables. Están relacionados estructuralmente con el hidrocarburo tetracíclico denominado ciclopentanoperhidrofenantreno. Biológicamente están relacionados con los terpenos, de los cuales derivan. Los diferentes esteroides se diferencian en la naturaleza y posición de diversos grupos funcionales, dobles enlaces y cadenas alifáticas lineales o ramificadas añadidas al anillo del ciclopentanoperhidrofenantreno.
Entre los esteroides se encuentran los esteroles, que poseen un grupo hidroxilo en el carbono 3; son los más abundantes e incluyen muchas moléculas de interés biológico entre las que destaca el colesterol .
El colesterol desempeña importantes funciones biológicas en las células animales. En primer lugar, gracias a su moderado carácter anfipático, es un componente esencial de las membranas celulares, a las que proporciona fluidez intercalándose entre los demás lípidos de membrana para impedir que se agreguen y "solidifiquen".
El colesterol es el principal esterol de los tejidos animales. En otros organismos existen esteroles semejantes, como el estigmasterol en las plantas y el ergosterol en los hongos. Con pocas excepciones las bacterias carecen de esteroles.
- a) Hormonas sexuales como la testosterona (hormona sexual masculina), el estradiol (hormona sexual femenina), y la progesterona(hormona progestágena).
- b) Hormonas adrenocorticales como la aldosterona y el cortisol, que regulan diferentes aspectos del metabolismo. c
- ) Ácidos biliares, principales componentes de la bilis, cuya función es emulsionar las grasas en el intestino delgado para facilitar la acción de las lipasas.
- d) Vitamina D, que regula el metabolismo del fósforo y del calcio(Figura 6.15).
13. PROSTAGLANDINAS
Son un grupo de lípidos que derivan de la ciclación de un ácido graso poliinsaturado de 20 átomos de carbono, el ácido araquidónico. Entre ellos los más importantes son las prostaglandinas. Hasta hace relativamente poco tiempo se desconocía su función biológica de estas biomoléculas, sin embargo hoy se sabe de desarrollan una serie de actividades muy potentes de naturaleza hormonal y reguladora:
- Algunas prostaglandinas estimulan la contracción del músculo liso del útero durante el parto o la menstruación.
- Otras afectan al flujo sanguíneo
- Al ciclo sueño-vigilia
- Otras son las responsables de la fiebre y el dolor asociados a los procesos inflamatorios.
El conocido fármaco ácido acetilsalicílico (aspirina) actúa inhibiendo la síntesis de prostaglandinas, de ahí su acción analgésica y antipirética.
14. FUNCIONES DE LOS LÍPIDOS
Los lípidos en los seres vivos desempeñan tres tipos de funciones: energéticas, estructurales y dinámicas.
a) Función energética. Aunque debido a su insolubilidad en agua, con la consiguiente dificultad para ser transportados en medio acuoso, los lípidos no pueden ser utilizados como combustible metabólico para un uso inmediato, constituyen (sobre todo los triacilglicéridos) un excelente almacén de combustible metabólico a largo plazo.
b) Funciones estructurales. Algunos tipos de lípidos (fosfoglicéridos, esfingolípidos y colesterol) son componentes esenciales de las membranas celulares. Otros como las ceras desempeñan funciones de protección y revestimiento de determinadas superficies, o de aislamiento térmico del organismo, como los triacilglicéridos almacenados en el tejido adiposo.
c) Funciones dinámicas. Los lípidos más abundantes desempeñan en las células papeles relativamente "pasivos" como servir de combustible o formar parte de las membranas. Sin embargo, otros lípidos más escasos realizan importantes funciones de control y regulación del metabolismo celular. Así, algunas vitaminas y coenzimas son de naturaleza lipídica, como lo son también algunas hormonas, pigmentos fotosintéticos y otras biomoléculas de especial relevancia para la vida de las células.
15. ESQUEMAS PROTEÍNAS




17. INTRODUCCIÓN
El término proteína deriva del griego "proteos" (lo primero, lo principal) y habla de su gran importancia para los seres vivos. La importancia de las proteínas es, en un primer análisis, cuantitativa: constituyen el 50% del peso seco de la célula (15% del peso total) por lo que representan la categoría de biomoléculas más abundante después del agua.
Sin embargo su gran importancia biológica reside, más que en su abundancia en la materia viva, en el elevado número de funciones biológicas que desempeñan, en su gran versatilidad funcional y sobre todo en la particular relación que las une con los ácidos nucleicos, ya que constituyen el vehículo habitual de expresión de la información genética contenida en éstos últimos.
18. COMPOSICIÓN DE LAS PROTEÍNAS.
Desde el punto de vista de su composición elemental todas las proteínas contienen carbono, hidrógeno, oxígeno ynitrógeno, mientras que casi todas contienen además azufre. Hay otros elementos que aparecen solamente en algunas proteínas (fósforo, cobre, zinc, hierro, etc.).
Las proteínas son biomoléculas de elevado peso molecular (macromoléculas) y presentan una estructura química compleja. Sin embargo, cuando se someten a hidrólisis ácida, se descomponen en una serie de compuestos orgánicos sencillos de bajo peso molecular: los α-aminoácidos. Son macromoléculas, es decir, son polímeros complejos formados por la unión de unos pocos monómeros o sillares estructurales de bajo peso molecular. Existen 20 α-aminoácidos diferentes que forman parte de las proteínas.
En las moléculas proteicas los sucesivos restos aminoácidos se hallan unidos covalentemente entre sí formando largos polímeros no ramificados. El tipo de enlace que los une recibe el nombre de enlace peptídico. Las cadenas de aminoácidos de las proteínas no son polímeros al azar, de longitud indefinida, cada una de ellas posee una determinada composición química, un peso molecular y una secuencia ordenada de aminoácidos.
19. CLASIFICACIÓN DE LAS PROTEÍNAS.
Las proteínas se clasifican en dos clases principales atendiendo a su composición.
Sin embargo su gran importancia biológica reside, más que en su abundancia en la materia viva, en el elevado número de funciones biológicas que desempeñan, en su gran versatilidad funcional y sobre todo en la particular relación que las une con los ácidos nucleicos, ya que constituyen el vehículo habitual de expresión de la información genética contenida en éstos últimos.
18. COMPOSICIÓN DE LAS PROTEÍNAS.
Desde el punto de vista de su composición elemental todas las proteínas contienen carbono, hidrógeno, oxígeno ynitrógeno, mientras que casi todas contienen además azufre. Hay otros elementos que aparecen solamente en algunas proteínas (fósforo, cobre, zinc, hierro, etc.).
Las proteínas son biomoléculas de elevado peso molecular (macromoléculas) y presentan una estructura química compleja. Sin embargo, cuando se someten a hidrólisis ácida, se descomponen en una serie de compuestos orgánicos sencillos de bajo peso molecular: los α-aminoácidos. Son macromoléculas, es decir, son polímeros complejos formados por la unión de unos pocos monómeros o sillares estructurales de bajo peso molecular. Existen 20 α-aminoácidos diferentes que forman parte de las proteínas.
En las moléculas proteicas los sucesivos restos aminoácidos se hallan unidos covalentemente entre sí formando largos polímeros no ramificados. El tipo de enlace que los une recibe el nombre de enlace peptídico. Las cadenas de aminoácidos de las proteínas no son polímeros al azar, de longitud indefinida, cada una de ellas posee una determinada composición química, un peso molecular y una secuencia ordenada de aminoácidos.
19. CLASIFICACIÓN DE LAS PROTEÍNAS.
Las proteínas se clasifican en dos clases principales atendiendo a su composición.
- Las proteínas simples u holoproteínas son las que están compuestas exclusivamente por aminoácidos.
- Las proteínas conjugadas o heteroproteínas son las que están compuestas por aminoácidos y otra sustancia de naturaleza no proteica que recibe el nombre de grupo prostético. Las proteínas conjugadas pueden a su vez clasificarse en función de la naturaleza de su grupo prostético. Así, se habla de glucoproteínas, cuando el grupo prostético es un glúcido, lipoproteínas cuando es un lípido, metaloproteínas cuando es un ion metálico, fosfoproteínas cuando es un grupo fosfato, etc.
Otro criterio de clasificación de las proteínas es la forma tridimensional de su molécula.
- Las proteínas fibrosas son de forma alargada, generalmente son insolubles en agua y suelen tener una función estructural
- Las proteínas globulares forman arrollamientos compactos de forma globular y suelen tener funciones de naturaleza dinámica (catalíticas, de transporte, etc).
Desde un punto de vista funcional se distinguen:

Las proteínas presentan tamaños moleculares muy variables. Algunas proteínas están formadas por una sola cadena de aminoácidos, mientras que otras, llamadas proteínas oligoméricas, están formadas por varias cadenas individuales denominadas protómeros o subunidades. Se ha podido comprobar que en la mayor parte de los casos las cadenas individuales de aminoácidos presentan pesos moleculares que oscilan entre los 12.000 y los 36.000 daltons, lo que se corresponde con una longitud de entre 100 y 300 restos aminoácidos. Sin embargo existen moléculas proteicas más pequeñas como la insulina (51 aminoácidos) y mucho más grandes como la apolipoproteína B, una proteína transportadora de colesterol, con 4.536 aminoácidos, que representa la cadena individual de aminoácidos más grande conocida hasta la fecha. Las proteínas de mayor tamaño están formadas invariablemente por varias cadenas de aminoácidos.
20. AMINOÁCIDOS: LOS SILLARES ESTRUCTURALES
Los aminoácidos son compuestos orgánicos que poseen un grupo carboxilo y un grupo amino. Pueden ser α, β, γ, δ....aminoácidos, según el grupo amino esté unido respectivamente al primero, segundo, tercero, cuarto... átomo de carbono contando a partir del átomo de carbono del grupo carboxilo. En la naturaleza existen distintos tipos de aminoácidos que desempeñan diferentes funciones, sin embargo, los aminoácidos que forman parte de las proteínas son todos ellos α-aminoácidos.

Existen 20 α-aminoácidos diferentes que forman parte de las proteínas. Todos ellos tienen una parte de su molécula en común (formada por el átomo de carbono α unido a los grupos amino y carboxilo) y difieren entre sí en la naturaleza de la cadena lateral (habitualmente llamada grupo R). En la fórmula estructural de un α-aminoácido; el grupo "R" representa la cadena lateral que difiere entre los distintos aminoácidos.
Se distinguen los siguientes grupos:
- Proteínas monoméricas: constan de una sola cadena polipeptídica, como la mioglobina.
- Proteínas oligoméricas: constan de varias cadenas polipeptídicas. Las distintas cadenas polipeptídicas que componen una proteína oligomérica se llaman subunidades, y pueden ser iguales o distintas entre sí. Un ejemplo es la hemoglobina, formada por 4 subunidades, cada una representada de distinto color en la figura inferior.
20. AMINOÁCIDOS: LOS SILLARES ESTRUCTURALES
Los aminoácidos son compuestos orgánicos que poseen un grupo carboxilo y un grupo amino. Pueden ser α, β, γ, δ....aminoácidos, según el grupo amino esté unido respectivamente al primero, segundo, tercero, cuarto... átomo de carbono contando a partir del átomo de carbono del grupo carboxilo. En la naturaleza existen distintos tipos de aminoácidos que desempeñan diferentes funciones, sin embargo, los aminoácidos que forman parte de las proteínas son todos ellos α-aminoácidos.
Existen 20 α-aminoácidos diferentes que forman parte de las proteínas. Todos ellos tienen una parte de su molécula en común (formada por el átomo de carbono α unido a los grupos amino y carboxilo) y difieren entre sí en la naturaleza de la cadena lateral (habitualmente llamada grupo R). En la fórmula estructural de un α-aminoácido; el grupo "R" representa la cadena lateral que difiere entre los distintos aminoácidos.
Se distinguen los siguientes grupos:
a) Aminoácidos con grupo R no polar (alifáticos y aromáticos).
b) Aminoácidos con grupo R polar sin carga .
c) Aminoácidos con grupo R con carga positiva.
d) Aminoácidos con grupo R con carga negativa.
b) Aminoácidos con grupo R polar sin carga .
c) Aminoácidos con grupo R con carga positiva.
d) Aminoácidos con grupo R con carga negativa.




Se representan las fórmulas estructurales de los 20 α-aminoácidos presentes en las proteínas en las formas iónicas en las que aparecen a pH fisiológico. Todos los α-aminoácidos tienen, además de sus nombres sistemáticos, nombres simplificados apropiados para su uso común, que, en algunos casos, provienen de la fuente biológica de la cual fueron aislados inicialmente; así, la asparagina se encontró por primera vez en el espárrago, el ácido glutámico se aisló del gluten de trigo, la tirosina fue identificada en el queso (del griego tyros = queso), y la glicocoladebe su nombre a su sabor dulce (del griego glycos = dulce).
Por otra parte, se han encontrado en las células vivas alrededor de otros 300 aminoácidos que desempeñan diferentes funciones pero que no forman parte de las proteínas. Algunos de ellos presentan configuración D y no todos son α-aminoácidos.
20.1. Estereoisomería de los aminoácidos
Los α-aminoácidos son compuestos quirales. En todos ellos, con la única excepción de la glicocola, el átomo de carbono α (el contiguo al grupo carboxilo) es un carbono asimétrico, es decir, un átomo de carbono unido a cuatro sustituyentes distintos. Debido a esta circunstancia, cada α-aminoácido puede existir en dos formas estereoisómeras cada una de ellas con una diferente ordenación espacial de los cuatro sustituyentes que rodean, en disposición tetraédrica, al carbono α.
Los α-aminoácidos son compuestos quirales. En todos ellos, con la única excepción de la glicocola, el átomo de carbono α (el contiguo al grupo carboxilo) es un carbono asimétrico, es decir, un átomo de carbono unido a cuatro sustituyentes distintos. Debido a esta circunstancia, cada α-aminoácido puede existir en dos formas estereoisómeras cada una de ellas con una diferente ordenación espacial de los cuatro sustituyentes que rodean, en disposición tetraédrica, al carbono α.
Estas dos formas estereoisómeras son además enantiómeros (imágenes especulares no superponibles una de la otra). La nomenclatura de las formas estereoisómeras de los α-aminoácidos se establece por convenio relacionando sus fórmulas en proyección de Fisher con la de un compuesto de referencia que es el gliceraldehido. Así, la forma D de un α-aminoácido es la que, en la fórmula en proyección de Fisher, tiene el grupo amino hacia la derecha, mientras que la forma L es la que lo tiene hacia la izquierda . Aunque existen en la naturaleza aminoácidos con configuración D que desempeñan diferentes funciones en las células, todos los aminoácidos presentes en las proteínas presentan configuración L.


Los α-aminoácidos, presentan actividad óptica, es decir, hacen girar en uno u otro sentido el plano de vibración de la luz polarizada. Así, algunos α-aminoácidos en disolución hacen girar dicho plano de vibración hacia la derecha, y se dice que son dextrógiros (+), mientras que otros lo hacen hacia la izquierda, y se dice que son levógiros (-). El carácter dextrógiro o levógiro de un α-aminoácido es independiente de la configuración D o L que presente.
20.2. Comportamiento ácido-baseLos aminoácidos son compuestos sólidos, cristalinos, que presentan un punto de fusión y una solubilidad en agua muy superiores a lo que cabría esperar dado su peso molecular. Ello se debe a que los aminoácidos existen en disolución, y cristalizan a partir de las disoluciones, en forma de iones dipolares
Los α-aminoácidos, presentan actividad óptica, es decir, hacen girar en uno u otro sentido el plano de vibración de la luz polarizada. Así, algunos α-aminoácidos en disolución hacen girar dicho plano de vibración hacia la derecha, y se dice que son dextrógiros (+), mientras que otros lo hacen hacia la izquierda, y se dice que son levógiros (-). El carácter dextrógiro o levógiro de un α-aminoácido es independiente de la configuración D o L que presente.
20.2. Comportamiento ácido-baseLos aminoácidos son compuestos sólidos, cristalinos, que presentan un punto de fusión y una solubilidad en agua muy superiores a lo que cabría esperar dado su peso molecular. Ello se debe a que los aminoácidos existen en disolución, y cristalizan a partir de las disoluciones, en forma de iones dipolares
A pH neutro el grupo carboxilo cede un protón y queda cargado negativamente y el grupo amino capta un protón y queda cargado positivamente. Así, los aminoácidos pueden comportarse como ácidos o como bases según el pH del medio; se dice que son sustancias anfóteras. Existe un valor de pH llamado punto isoeléctrico (pI) para el cual el aminoácido está compensado eléctricamente (carga neta = 0).


Las curvas de titulación de los aminoácidos son más complejas que las de los pares conjugados ácido-base corrientes. Esto se debe a que cada aminoácido posee dos grupos funcionales capaces de aceptar o ceder protones (amino y carboxilo), cada uno de los cuales tiene su propio pK y comportamiento ácido-base característico. Por otra parte, algunos aminoácidos presentan cadenas laterales (R) con grupos funcionales que son potenciales dadores o aceptores de protones, y que por lo tanto también influyen de manera determinante en sus propiedades ácido-base.
El comportamiento ácido-base de los aminoácidos reviste una gran importancia biológica, ya que influye a su vez en las propiedades de las proteínas de las que forman parte. Además, las técnicas para separar y analizar los aminoácidos componentes de una proteína se basan en gran medida en su comportamiento ácido-base.
ANIMACIONES




21. EL ENLACE PEPTÍDICO
Los aminoácidos se enlazan para formar proteínas mediante enlace peptídico. Los péptidos son compuestos formados por la unión de aminoácidos mediante enlace peptídico. El enlace peptídico es una unión covalente tipo amida sustituida que se da al reaccionar el grupo amino de un aminoácido con el grupo carboxilo de otro aminoácido con desprendimiento de una molécula de agua En la siguiente animación se puede apreciar como es el proceso de formación de un enlace peptídico.
El comportamiento ácido-base de los aminoácidos reviste una gran importancia biológica, ya que influye a su vez en las propiedades de las proteínas de las que forman parte. Además, las técnicas para separar y analizar los aminoácidos componentes de una proteína se basan en gran medida en su comportamiento ácido-base.
ANIMACIONES
21. EL ENLACE PEPTÍDICO
Los aminoácidos se enlazan para formar proteínas mediante enlace peptídico. Los péptidos son compuestos formados por la unión de aminoácidos mediante enlace peptídico. El enlace peptídico es una unión covalente tipo amida sustituida que se da al reaccionar el grupo amino de un aminoácido con el grupo carboxilo de otro aminoácido con desprendimiento de una molécula de agua En la siguiente animación se puede apreciar como es el proceso de formación de un enlace peptídico.



Cuando dos aminoácidos reaccionan para formar un enlace peptídico el compuesto resultante recibe el nombre de dipéptido. Por ser el enlace peptídico una unión "cabeza-cola" (grupo amino con grupo carboxilo) un dipéptido conserva siempre un grupo amino libre, que puede reaccionar con el grupo carboxilo de otro aminoácido, y un grupo carboxilo libre, que puede reaccionar con el grupo amino de otro aminoácido.
Esta circunstancia permite que mediante enlaces peptídicos se puedan enlazar un número elevado de aminoácidos formando largas cadenas que siempre tendrán en un extremo un grupo amino libre (extremo amino terminal) y en el otro un grupo carboxilo libre (extremo carboxi-terminal).

Los péptidos se clasifican según el número de restos de aminoácidos que los forman. Así los péptidos formados por 2, 3, 4,.... aminoácidos se denominan respectivamente dipéptidos, tripéptidos, tetrapéptidos... En general cuando el número de aminoácidos implicados es menor o igual a 10 decimos que se trata de un oligopéptido, cuando es mayor que 10 decimos que se trata de un polipéptido. Es también frecuente el uso del la expresión cadena polipeptídica en lugar de polipéptido.
Los péptidos se clasifican según el número de restos de aminoácidos que los forman. Así los péptidos formados por 2, 3, 4,.... aminoácidos se denominan respectivamente dipéptidos, tripéptidos, tetrapéptidos... En general cuando el número de aminoácidos implicados es menor o igual a 10 decimos que se trata de un oligopéptido, cuando es mayor que 10 decimos que se trata de un polipéptido. Es también frecuente el uso del la expresión cadena polipeptídica en lugar de polipéptido.
Cuando una cadena polipeptídica tiene más de 100 restos de aminoácidos decimos que se trata de una proteína. Sin embargo hay que tener en cuenta que existen proteínas, llamadas oligoméricas, que están formadas por varias cadenas polipeptídicas, por lo que los términos cadena polipeptídica y proteína no pueden considerarse sinónimos en todos los casos.
Aunque en los sucesivo nos ocuparemos fundamentalmente de proteínas formadas por centenares de residuos de aminoácidos, es conveniente resaltar que algunos péptidos cortos presentan actividades biológicas importantes. Entre ellos cabe citar algunas hormonas como la oxitocina (nueve residuos aminoácidos), que estimula las contracciones del útero durante el parto. También son dignas de mención las encefalinas, péptidos cortos sintetizados en el sistema nervioso central que actúan sobre el cerebro produciendo analgesia (eliminación del dolor). Los venenos extremadamente tóxicos producidos por algunas setas comoAmanita phaloides también son péptidos, al igual que muchos antibióticos.
ANIMACIONES





Enlace peptídico
22. PROTEÍNAS: CONFORMACIÓN TRIDIMENSIONAL.
Las proteínas, como ya se dijo anteriormente, no son polímeros al azar de longitud indefinida, sino que cada una de ellas tiene una determinada composición en aminoácidos y estos están ordenados en una determinada secuencia. Hay que añadir a ello que en las células vivas las cadenas polipeptídicas de las proteínas no se encuentran extendidas ni plegadas al azar adoptando estructuras caprichosas o variables, sino que cada una de ellas se encuentra plegada de un modo característico, que es igual para todas las moléculas de una misma proteína, y que recibe el nombre de estructura o conformación tridimensional nativa de la proteína. Una clara evidencia en favor de esta idea la constituye el hecho de que las proteínas puedan cristalizar. Desde que en 1926 James Sumner consiguió obtener cristales del enzima ureasa, centenares de proteínas han sido obtenidas en estado cristalino.
El plegamiento de una cadena polipeptídica se realiza mediante rotaciones de los enlaces simples del esqueleto. Dado que el esqueleto de una cadena polipeptídica consta de centenares de enlaces simples, cabría esperar que dicha cadena pudiera adoptar un número elevadísimo de conformaciones diferentes. Sin embargo, existen una serie de restricciones a la libertad de giro de estos enlaces (la mayoría de ellas derivadas de la interacción de la cadena polipeptídica con las moléculas de agua que la rodean) las cuales determinan que sólo sea posible una conformación tridimensional estable.
La conformación tridimensional de una proteína es un hecho biológico de una gran complejidad: existen distintos niveles de plegamiento que se superponen unos a otros. Debido a ello, para sistematizar el conocimiento acerca de este fenómeno, se establecen una serie de niveles dentro de la estructura de la proteína que se conocen como estructuras primaria, secundaria, terciaria y cuaternaria.
Aunque en los sucesivo nos ocuparemos fundamentalmente de proteínas formadas por centenares de residuos de aminoácidos, es conveniente resaltar que algunos péptidos cortos presentan actividades biológicas importantes. Entre ellos cabe citar algunas hormonas como la oxitocina (nueve residuos aminoácidos), que estimula las contracciones del útero durante el parto. También son dignas de mención las encefalinas, péptidos cortos sintetizados en el sistema nervioso central que actúan sobre el cerebro produciendo analgesia (eliminación del dolor). Los venenos extremadamente tóxicos producidos por algunas setas comoAmanita phaloides también son péptidos, al igual que muchos antibióticos.
ANIMACIONES
Enlace peptídico
22. PROTEÍNAS: CONFORMACIÓN TRIDIMENSIONAL.
Las proteínas, como ya se dijo anteriormente, no son polímeros al azar de longitud indefinida, sino que cada una de ellas tiene una determinada composición en aminoácidos y estos están ordenados en una determinada secuencia. Hay que añadir a ello que en las células vivas las cadenas polipeptídicas de las proteínas no se encuentran extendidas ni plegadas al azar adoptando estructuras caprichosas o variables, sino que cada una de ellas se encuentra plegada de un modo característico, que es igual para todas las moléculas de una misma proteína, y que recibe el nombre de estructura o conformación tridimensional nativa de la proteína. Una clara evidencia en favor de esta idea la constituye el hecho de que las proteínas puedan cristalizar. Desde que en 1926 James Sumner consiguió obtener cristales del enzima ureasa, centenares de proteínas han sido obtenidas en estado cristalino.
El plegamiento de una cadena polipeptídica se realiza mediante rotaciones de los enlaces simples del esqueleto. Dado que el esqueleto de una cadena polipeptídica consta de centenares de enlaces simples, cabría esperar que dicha cadena pudiera adoptar un número elevadísimo de conformaciones diferentes. Sin embargo, existen una serie de restricciones a la libertad de giro de estos enlaces (la mayoría de ellas derivadas de la interacción de la cadena polipeptídica con las moléculas de agua que la rodean) las cuales determinan que sólo sea posible una conformación tridimensional estable.
La conformación tridimensional de una proteína es un hecho biológico de una gran complejidad: existen distintos niveles de plegamiento que se superponen unos a otros. Debido a ello, para sistematizar el conocimiento acerca de este fenómeno, se establecen una serie de niveles dentro de la estructura de la proteína que se conocen como estructuras primaria, secundaria, terciaria y cuaternaria.

La estructura primaria de una proteína es su secuencia de aminoácidos, es decir, vendría especificada por los aminoácidos que la forman y el orden de colocación de los mismos a lo largo de la cadena polipeptídica. La secuencia de aminoácidos de una proteína se escribe empezando por el extremo amino terminal y finalizando por el carboxi-terminal.

Si analizamos en detalle la estructura primaria de una proteína observaremos, dado que el enlace peptídico implica a los grupos amino y carboxilo de cada aminoácido, y que éstos están unidos a su vez al mismo átomo de carbono (Cα), el esqueleto de la cadena polipeptídica es una sucesión monótona de estos tres tipos de enlace:
C α ------- C carboxílico
C carbox --- N amino(enlace peptídico)
N amino ---- C α
También observamos que las cadenas laterales o grupos R de los distintos restos aminoácidos, que no están implicadas en el enlace peptídico, surgen lateralmente hacia afuera de este esqueleto monótono.
Los estudios realizados acerca de la estructura primaria de proteínas procedentes de diferentes especies de seres vivos revelan que aquellas proteínas que desempeñan funciones similares en diferentes especies tienen secuencias de aminoácidos parecidas entre sí. Por otra parte, se ha comprobado que cuanto más emparentadas evolutivamente estén dos especies mayor es el grado de similitud entre las secuencias de aminoácidos de sus proteínas homólogas. Estos datos sugieren que debe existir algún tipo de relación entre la secuencia de aminoácidos y la función de las proteínas.
El número de secuencias distintas se calcula con la fórmula 20 elevado a n, siendo n el número de aminoácidos.
22.2.-Estructura secundaria
La estructura secundaria de una proteína es el modo característico de plegarse la misma a lo largo de un eje. Es el primer nivel de plegamiento, en el que los distintos restos de aminoácidos se disponen de un modo ordenado y repetitivo siguiendo una determinada dirección.
En las proteínas fibrosas (aquéllas cuyas cadenas polipeptídicas están ordenadas formando largos filamentos u hojas planas) las estructuras primaria y secundaria especifican completamente la conformación tridimensional; estas proteínas no presentan por lo tanto niveles superiores de complejidad
Fue precisamente en las proteínas fibrosas, dada su mayor simplicidad estructural, donde fue estudiada inicialmente la estructura secundaria; particularmente en dos tipos de proteínas de origen animal muy abundantes: las queratinas y los colágenos. Ambas son proteínas insolubles que desempeñan importantes funciones de tipo estructural en los animales superiores. Existen dos tipos de queratinas de diferente dureza y consistencia, las α-queratinas (por ejemplo las que abundan en el pelo o en las uñas) y las β-queratinas (telas de araña, seda, etc.).
El análisis de la estructura secundaria de las proteínas fibrosas fue abordado inicialmente mediante la técnica de difracción de rayos X (basada en la capacidad de los átomos de difractar los rayos X en función de su tamaño). Esta técnica es aplicable al análisis de estructuras cristalinas, sin embargo, la microscopía electrónica reveló que las proteínas fibrosas presentaban estructuras repetitivas que eran susceptibles de análisis mediante esta técnica.
Los primeros análisis de difracción de rayos X de las queratinas, realizados por Willian Atsbury en la década de los años 30, proporcionaron datos acerca de estructuras que se repetían con una periodicidad fija a lo largo de sus cadenas polipeptídicas, siendo estas periodicidades diferentes según se tratase de α o de β-queratinas. Dado que las cadenas polipeptídicas extendidas no presentan estructuras repetitivas que puedan dar lugar a estas periodicidades, se concluyó que dichas cadenas debían encontrarse plegadas de un modo regular que era diferente en cada tipo de queratinas.
Por otra parte, aplicando la técnica DRX a pequeños péptidos (dos o tres residuos aminoácidos) en estado cristalino Pauling y Corey pudieron conocer la estructura íntima del enlace peptídico. Observaron que este enlace era ligeramente más corto de lo que sería un enlace simple C-N, lo que les permitió deducir que poseía un carácter parcial de doble enlace. Ello es debido a que el nitrógeno del grupo peptídico posee un orbital vacante que le
permite compartir en resonancia un par de electrones del doble enlace C-O. El carácter parcial de doble enlace impide que el enlace peptídico pueda girar sobre sí mismo; los cuatro átomos del grupo peptídico son coplanares, estando el oxígeno y el hidrógeno en posición trans. Esta falta de libertad de giro supone una primera restricción en el número de conformaciones posibles de la cadena polipeptídica, que estaría entonces constituida por una serie de planos rígidos formados por los diferentes grupos peptídicos, los cuales podrían adoptar diferentes posiciones unos con respecto a otros mediante giros de los enlaces sencillos que flanquean cada uno de estos planos.

Pauling y Corey construyeron modelos moleculares de gran precisión (con bolas y varillas) hasta que encontraron unos que encajaban con los datos experimentales, es decir, hasta que encontraron modelos que, respetando las restricciones de giro del enlace peptídico, explicaban las periodicidades obtenidas. A la vista de estos modelos pudieron observar que no sólo eran posibles, sino que, de ser reales, presentarían una gran estabilidad, ya que todos los grupos peptídicos del esqueleto quedaban colocados en la relación geométrica adecuada para poder establecer puentes de hidrógeno entre ellos, circunstancia esta que proporcionaría una gran estabilidad a la estructura.
Los modelos encontrados fueron denominados respectivamente hélice α (que es la estructura secundaria de las α-queratinas) y conformación β (que es la estructura secundaria de las β-queratinas). Con posterioridad se descubrió la estructura secundaria del colágeno, la cual se denominó hélice del colágeno.


En la hélice-α el esqueleto de la cadena polipeptídica se encuentra arrollado de manera compacta alrededor del eje longitudinal de la molécula, y los grupos R de los distintos restos aminoácidos sobresalen de esta estructura helicoidal, que tiene forma de escalera de caracol.
Cada giro de la hélice abarca 3,6 residuos aminoácidos, ocupando unos 0,56 nm del eje longitudinal, lo que se corresponde con la periodicidad observada por DRX. El rasgo más sobresaliente de esta estructura es que todos los grupos peptídicos de los diferentes restos aminoácidos quedan enfrentados en la relación geométrica adecuada para formar puentes de hidrógeno entre sí; estos puentes se establecen entre el oxígeno del grupo carboxilo de cada residuo aminoácido y el hidrógeno del grupo amino que se encuentra cuatro residuos más allá en dirección carboxi-terminal (algo más de una vuelta completa de hélice). Así, cada vuelta sucesiva de la hélice α se mantiene unida a las vueltas adyacentes mediante varios puentes de hidrógeno intracatenarios que, actuando cooperativamente, proporcionan a la estructura una considerable estabilidad.
En la conformación β, también llamada hoja plegada, el esqueleto de la cadena polipeptídica se dispone en zig-zag con los grupos R de los distintos aminoácidos proyectándose alternativamente a uno y otro lado de dicho esqueleto. Muchas de estas cadenas colocadas paralelamente unas a otras forman una estructura que recuerda a una hoja de papel plegada, en la que los grupos R de los aminoácidos se encuentran sobresaliendo por ambas caras de dicha hoja. En este caso, los grupos peptídicos de los diferentes restos aminoácidos establecen puentes de hidrógeno con los de las cadenas vecinas (puentes de hidrógeno intercatenarios).
En la conformación β, también llamada hoja plegada, el esqueleto de la cadena polipeptídica se dispone en zig-zag con los grupos R de los distintos aminoácidos proyectándose alternativamente a uno y otro lado de dicho esqueleto. Muchas de estas cadenas colocadas paralelamente unas a otras forman una estructura que recuerda a una hoja de papel plegada, en la que los grupos R de los aminoácidos se encuentran sobresaliendo por ambas caras de dicha hoja. En este caso, los grupos peptídicos de los diferentes restos aminoácidos establecen puentes de hidrógeno con los de las cadenas vecinas (puentes de hidrógeno intercatenarios).

La hélice del colágeno es un tipo de estructura secundaria que sólo aparece en esta proteína. Se trata de un arrollamiento helicoidal con tres residuos aminoácidos por vuelta en el que la cadena polipeptídica se encuentra más extendida que en la hélice α. Tres de estas hélices se encuentran a su vez arrolladas en una estructura superhelicoidal que da lugar a la molécula de tropocolágeno, que es la unidad que se repite a lo largo de las fibras de colágeno.



En las proteínas globulares se han descubierto estructuras secundarias características de los puntos en que la cadena polipeptídica cambia abruptamente de dirección. Se les ha denominado giros o codos. El más extendido es el codo β, que consta de cuatro residuos aminoácidos formando un bucle cerrado con diferentes grupos peptídicos unidos por puente de hidrógeno
Ahora bien, ¿qué es lo que determina que una cadena polipeptídica adopte una u otra de estas posibles estructuras secundarias conocidas? Los estudios realizados acerca de la estructura de cadenas polipeptídicas formadas por un solo tipo aminoácido (poliaminoácidos), así como diversas consideraciones teóricas (basadas en el tamaño o carga eléctrica de los grupos R de los distintos aminoácidos de una cadena), llevaron a la conclusión de que es la secuencia de aminoácidos, es decir, la estructura primaria, lo que determina el modo en que una cadena polipeptídica ha de plegarse a lo largo de un eje, es decir, su estructura secundaria. Es la naturaleza y posición de los grupos R a lo largo de la cadena, es decir, su secuencia, lo que propicia o impide el plegamiento según uno u otro modelo.
22.3.-Estructura terciaria
Existen proteínas cuya conformación tridimensional no puede especificarse totalmente considerando sólo sus estructuras primaria y secundaria. Son las llamadas proteínas globulares cuyas cadenas polipeptídicas se hallan plegadas de un modo complejo formando arrollamientos globulares compactos que tienden a adoptar una forma aproximadamente esférica. La proteínas globulares son generalmente solubles en agua y desempeñan un gran número de funciones biológicas (por ejemplo los enzimas son proteínas globulares). Se conoce como estructura terciaria el modo característico de plegarse una cadena polipeptídica para formar un arrollamiento globular compacto.
El estudio de la estructura terciaria de las proteínas globulares se abordó también mediante la aplicación de la técnica de difracción de rayos X. Un paso previo necesario fue la obtención de proteínas globulares en estado cristalino muy puro a partir de disoluciones, ya que la técnica DRX sólo se puede aplicar a estructuras cristalinas. Una vez solventado este problema pudo conocerse la estructura terciaria de algunas proteínas globulares. La primera proteína cuya estructura terciaria fue conocida fue la mioglobina (una proteína que transporta oxígeno en el músculo). En ella se pueden apreciar ocho segmentos rectilíneos con estructura secundaria en hélice α separados por curvaturas sin estructura secundaria aparente. Alrededor del 70% de la cadena polipeptídica se encuentra en las regiones plegadas en hélice α. La molécula es muy compacta, sin apenas espacio para moléculas de agua en su interior. Los grupos R de residuos aminoácidos con carácter polar o iónico se proyectan hacia la periferia de la molécula, mientras que los de carácter no polar se encuentran enterrados en el interior de la misma, aislados del contacto con el agua. La estructura se encuentra estabilizada por diferentes tipos de interacciones débiles entre los grupos R de diferentes aminoácidos; estas interacciones son de largo alcance, afectando a grupos R de residuos aminoácidos que pueden ocupar posiciones muy alejadas en la cadena polipeptídica.


En los últimos años se ha podido descifrar la estructura terciaria de miles de proteínas globulares. De estos estudios se deduce que el caso de la mioglobina representa sólo una de las múltiples posibilidades de plegamiento de una proteína globular. La variedad de estructuras terciarias posibles es inmensa. Sin embargo se pueden hacer algunas generalizaciones interesantes. En todas ellas..
a) La cadena polipeptídica está plegada de un modo muy compacto, sin apenas espacio para moléculas de agua en el interior del plegamiento.
b) Existen tramos rectilíneos que presentan estructura secundaria en hélice-α o en conformación β; en la mayoría de las proteínas estudiadas coexisten zonas con uno y otro tipo de estructura (Figura 8.18). Estos tramos están separados por curvaturas sin estructura secundaria aparente en unos casos o por codos β en otros. Las cantidades relativas que representan los diferentes tipos de estructura secundaria varían considerablemente de unas proteínas a otras.
c) Se han detectado agrupamientos estables de estructuras secundarias que dan lugar a motivos estructurales que se repiten en multitud de proteínas diferentes. Entre estos agrupamientos, denominados estructuras supersecundarias, cabe citar, la "silla β", el "haz de cuatro hélices", el"lazo βαβ" o el "sandwich ββ".
d) En algunas proteínas se han detectado dos o más regiones globulares densamente empaquetadas que se hallan conectadas entre sí por un corto tramo de cadena polipeptídica extendida o plegada en hélice α. Estas regiones globulares, denominadas dominios, presentan una gran estabilidad, y aparecen repetidas en muchas proteínas diferentes.
e) Los restos de aminoácidos con grupos R polares o con carga se proyectan hacia el exterior de la estructura, expuestos al contacto con las moléculas de agua.
f) Los restos de aminoácidos con grupos R no polares (hidrófobos) se encuentran en el interior de la estructura, aislados del contacto con el agua y ejerciendo interacciones hidrofóbicas entre sí.
Por otra parte se observó que en todas las proteínas estudiadas existe una serie de fuerzas intramoleculares que tienden a estabilizar la estructura terciaria. Estas fuerzas son de dos tipos:
- Enlaces covalentes (puentes disulfuro entre los grupos -SH de los restos de cisteína)
- Interacciones débiles entre los grupos R de distintos aminoácidos que ocupan posiciones muy distantes a lo largo de la cadena polipeptídica (puentes de hidrógeno, interacciones iónicas, fuerzas de Van der Waals).


A la vista de estos datos se llegó a la conclusión de que es la naturaleza (polar o no polar) de los distintos grupos R, las posibilidades de formación de interacciones débiles o covalentes entre los mismos, y su posición en la cadena polipeptídica, es decir, la secuencia de aminoácidos lo que determina el hecho de que ésta adopte una u otra disposición en el espacio, o lo que es lo mismo, una determinada estructura terciaria. Hay que tener en cuenta que en su estado nativo las moléculas proteicas se encuentran en el seno del agua y que, por lo tanto, el plegamiento de la cadena polipeptídica será una respuesta a la interacción de los distintos grupos R (polares o no polares) con las moléculas de agua; además, la posibilidad de que se establezcan interacciones que estabilicen la estructura entre los distintos grupos R a lo largo de la cadena polipeptídica también dependerá de la naturaleza y posición de los mismos en la cadena. En la actualidad todo parece indicar que las interacciones hidrofóbicas entre los grupos R no polares enterrados en el interior de la estructura constituyen la verdadera fuerza directriz del plegamiento de una cadena polipeptídica, contribuyendo los demás tipos de interacciones débiles y covalentes a su mayor estabilidad.
Vemos, pues, que, al igual que sucede con la estructura secundaria, la estructura primaria determina la estructura terciaria de las proteínas globulares.
22.4. Estructura cuaternaria
Existen proteínas que están formadas por varias cadenas polipeptídicas: son las llamadas proteínas oligoméricas. En ellas, la proteína completa (oligómero) está formada por un número variable de subunidades o protómeros. Los oligómeros pueden ser dímeros, trímeros, tetrámeros, pentámeros, hexámeros...., según estén formados por 2, 3, 4, 5, 6.... protómeros. Los oligómeros más frecuentes están formados por un número par de cadenas polipeptídicas.
En estas proteínas las distintas subunidades están asociadas de un modo característico al que llamamos estructura cuaternaria.
En estas proteínas las distintas subunidades están asociadas de un modo característico al que llamamos estructura cuaternaria.


El estudio de la estructura cuaternaria de las proteínas oligoméricas también fue abordado mediante la aplicación de la técnica DRX tras la obtención de las mismas en estado cristalino puro. En este caso la interpretación de los difractogramas de RX resultó tan compleja que algunos cristalógrafos de proteínas emplearon en este esfuerzo hasta 25 años de trabajo antes de poder publicar resultados.
La primera proteína cuya estructura cuaternaria se conoció fue la hemoglobina humana (la proteína encargada de transportar el oxígeno en la sangre).
También se pueden hacer algunas generalizaciones acerca de la estructura cuaternaria de algunas proteínas oligoméricas conocidas. En todas ellas.....
a) Cada una de las subunidades o protómeros presenta una estructura terciaria determinada con rasgos similares a los de las proteínas globulares formadas por una sola cadena polipeptídica.
b) La estructura terciaria de las diferentes subunidades de una proteína oligomérica es muy semejante a la de proteínas globulares que desempeñan la misma o parecida función (la estructura terciaria de cada una de las subunidades de la hemoglobina es casi idéntica a la estructura terciaria de la mioglobina. Ambas proteínas desempeñan la función de transportar oxígeno, una en la sangre, la otra en el músculo. Se percibe pues una clara relación entre estructura y función.
c) Las distintas subunidades se encuentran asociadas de un modo característico, estableciéndose entre ellas puntos de contacto que son los mismos para todas las moléculas de una misma proteína. Estos puntos de contacto se ven estabilizados por interacciones débiles (puentes de hidrógeno, fuerzas de Van der Waals, interacciones iónicas) entre los grupos R de determinados aminoácidos.
A la vista de estos resultados se dedujo que también en este caso es la naturaleza y posición de los grupos R de los distintos aminoácidos en las diferentes subunidades la que determina cuáles han de ser los puntos de contacto entre las mismas, y, por lo tanto, el modo característico de asociarse unas con otras, es decir, la estructura cuaternaria; los puntos de contacto vendrán dados por las posibilidades de formación de interacciones débiles del tipo de las citadas y éstas a su vez de la naturaleza y posición de los distintos grupos R.
Deducimos, pues, que es la estructura primaria de las distintas subunidades la que determina la estructura cuaternaria de una proteína oligomérica.
Como conclusión podemos afirmar que la secuencia de aminoácidos (estructura primaria) contiene la información necesaria y suficiente para determinar la conformación tridimensional de una proteína a sus diferentes niveles de complejidad (estructuras secundaria, terciaria y cuaternaria).
ANIMACIONES


VISOR 3D
Aminoácidos. Aspectos estructurales generales
Aminoácidos de las proteínas
Péptidos y enlace peptídico
Principios generales de plegamiento
La hélice alfa
La hoja plegada
La hélice del colágeno
Dominios y estructuras supersecundarias
Estructura terciaria y plegamiento tridimensional.
23. PROTEÍNAS. RELACIÓN ESTRUCTURA-FUNCIÓN.
Las proteínas son las macromoléculas más versátiles de cuantas existen en la materia viva: desempeñan un elevado número de funciones biológicas diferentes. Cada proteína está especializada en llevar a cabo una determinada función.
Entre las funciones de las proteínas cabe destacar las siguientes: catalíticas, estructurales, de transporte, nutrientes y de reserva, contráctiles o mótiles, de defensa, reguladoras del metabolismo, etc.
La función de una proteína depende de la interacción de la misma con una molécula a la que llamamos ligando (en el caso particular de los enzimas el ligando recibe el nombre de sustrato). El ligando es específico de cada proteína. A su vez, la interacción entre proteína y ligando reside en un principio de complementariedad estructural: el ligando debe encajar en un hueco existente en la superficie de la proteína (el centro activo) tal y como lo haría una
llave en una cerradura. Sólo aquel o aquellos ligandos capaces de acoplarse en el centro activo de la proteína serán susceptibles de interactuar con ella.
Hay que tener en cuenta que este acoplamiento no es meramente espacial, sino que la proteína "ve" en su ligando, además de la forma, la distribución de cargas eléctricas, sus distintos grupos funcionales, y, en general, las posibilidades de establecer interacciones débiles con él a través de los grupos R de los aminoácidos que rodean el centro activo (el ligando "atraca" en el centro activo como lo haría un barco en un muelle, se establecen entre ambos "amarras" en forma de interacciones débiles que hacen más estable la asociación).
De lo anteriormente expuesto es fácil deducir que para que una proteína desempeñe su función biológica debe permanecer intacta su conformación tridimensional nativa. Si se pierde dicha conformación, y por lo tanto se altera la estructura del centro activo, ya no habrá acoplamiento entre proteína y ligando (no se "reconocerán") y la interacción entre ambos, de la que depende la función, ya no tendrá lugar. Como corolario de este razonamiento podemos afirmar que la función biológica de una proteína depende de su conformación tridimensional.
En resumen, la secuencia de aminoácidos de una proteína determina su conformación tridimensional, y ésta, a su vez, su función biológica.
1. Enzimas. La gran mayoría de las reacciones metabólicas tienen lugar gracias a la presencia de un catalizador de naturaleza proteica específico para cada reacción. Estos biocatalizadores reciben el nombre de enzimas. La gran mayoría de las proteínas son enzimas.


2. Las hormonas son sustancias producidas por una célula y que una vez secretadas ejercen su acción sobre otras células dotadas de un receptor adecuado. Algunas hormonas son de naturaleza proteica, como lainsulina y el glucagón (que regulan los niveles de glucosa en sangre) o las hormonas segregadas por la hipófisis como la hormona del crecimiento, o la calcitonina (que regula el metabolismo del calcio).
3. Reconocimiento celular. La superficie celular alberga un gran número de proteínas encargadas delreconocimiento de señales químicas de muy diverso tipo (figura de la izquierda). Existen receptoreshormonales, de neurotransmisores, de anticuerpos, de virus, de bacterias, etc. En muchos casos, los ligandos que reconoce el receptor ( hormonas y neurotransmisores) son, a su vez, de naturaleza proteica.
4. Transporte. En los seres vivos son esenciales los fenómenos de transporte, bien para llevar una molécula hidrofóbica a través de un medio acuoso (transporte de oxígeno o lípidos a través de la sangre) o bien para transportar moléculas polares a través de barreras hidrofóbicas (transporte a través de la membrana plasmática). Los transportadores biológicos son siempre proteínas.
5. Estructural. Las células poseen un citoesqueleto de naturaleza proteica que constituye un armazón alrededor del cual se organizan todos sus componentes, y que dirige fenómenos tan importantes como el transporte intracelular o la división celular. En los tejidos de sostén (conjuntivo, óseo, cartilaginoso) de los vertebrados, las fibras de colágeno forman parte importante de la matriz extracelular (de color claro en la Figura) y son las encargadas de conferir resistencia mecánica tanto a la tracción como a la compresión.
6. Defensiva. En los vertebrados superiores, las inmunoglobulinas sse encargan de reconocer moléculas u organismos extraños y se unen a ellos para facilitar su destrucción por las células del sistema inmunitario
7. Movimiento. Todas las funciones de motilidad de los seres vivos están relacionadas con las proteínas. Así, la contracción del músculo resulta de la interacción entre dos proteínas, laactina y la miosina.
8. Reserva. La ovoalbúmina de la clara de huevo, la lactoalbúmina de la leche, la gliadina del grano de trigo y lahordeína de la cebada, constituyen una reserva de aminoácidos para el futuro desarrollo del embrión.
9. Reguladora. Muchas proteínas se unen al DNA y de esta formacontrolan la transcripción génica. Las distintas fases del ciclo celular son el resultado de un complejo mecanismo de regulación desempeñado por proteínas como la ciclina.
De lo anteriormente expuesto es fácil deducir que para que una proteína desempeñe su función biológica debe permanecer intacta su conformación tridimensional nativa. Si se pierde dicha conformación, y por lo tanto se altera la estructura del centro activo, ya no habrá acoplamiento entre proteína y ligando (no se "reconocerán") y la interacción entre ambos, de la que depende la función, ya no tendrá lugar. Como corolario de este razonamiento podemos afirmar que la función biológica de una proteína depende de su conformación tridimensional.
En resumen, la secuencia de aminoácidos de una proteína determina su conformación tridimensional, y ésta, a su vez, su función biológica.
1. Enzimas. La gran mayoría de las reacciones metabólicas tienen lugar gracias a la presencia de un catalizador de naturaleza proteica específico para cada reacción. Estos biocatalizadores reciben el nombre de enzimas. La gran mayoría de las proteínas son enzimas.
2. Las hormonas son sustancias producidas por una célula y que una vez secretadas ejercen su acción sobre otras células dotadas de un receptor adecuado. Algunas hormonas son de naturaleza proteica, como lainsulina y el glucagón (que regulan los niveles de glucosa en sangre) o las hormonas segregadas por la hipófisis como la hormona del crecimiento, o la calcitonina (que regula el metabolismo del calcio).
3. Reconocimiento celular. La superficie celular alberga un gran número de proteínas encargadas delreconocimiento de señales químicas de muy diverso tipo (figura de la izquierda). Existen receptoreshormonales, de neurotransmisores, de anticuerpos, de virus, de bacterias, etc. En muchos casos, los ligandos que reconoce el receptor ( hormonas y neurotransmisores) son, a su vez, de naturaleza proteica.
4. Transporte. En los seres vivos son esenciales los fenómenos de transporte, bien para llevar una molécula hidrofóbica a través de un medio acuoso (transporte de oxígeno o lípidos a través de la sangre) o bien para transportar moléculas polares a través de barreras hidrofóbicas (transporte a través de la membrana plasmática). Los transportadores biológicos son siempre proteínas.
5. Estructural. Las células poseen un citoesqueleto de naturaleza proteica que constituye un armazón alrededor del cual se organizan todos sus componentes, y que dirige fenómenos tan importantes como el transporte intracelular o la división celular. En los tejidos de sostén (conjuntivo, óseo, cartilaginoso) de los vertebrados, las fibras de colágeno forman parte importante de la matriz extracelular (de color claro en la Figura) y son las encargadas de conferir resistencia mecánica tanto a la tracción como a la compresión.
6. Defensiva. En los vertebrados superiores, las inmunoglobulinas sse encargan de reconocer moléculas u organismos extraños y se unen a ellos para facilitar su destrucción por las células del sistema inmunitario
7. Movimiento. Todas las funciones de motilidad de los seres vivos están relacionadas con las proteínas. Así, la contracción del músculo resulta de la interacción entre dos proteínas, laactina y la miosina.
8. Reserva. La ovoalbúmina de la clara de huevo, la lactoalbúmina de la leche, la gliadina del grano de trigo y lahordeína de la cebada, constituyen una reserva de aminoácidos para el futuro desarrollo del embrión.
9. Reguladora. Muchas proteínas se unen al DNA y de esta formacontrolan la transcripción génica. Las distintas fases del ciclo celular son el resultado de un complejo mecanismo de regulación desempeñado por proteínas como la ciclina.
HOLOPROTEÍNAS | |
Globulares |
|
Fibrosas |
|
HETEROPROTEÍNAS | |
Glucoproteínas |
|
Lipoproteínas
|
|
Nucleoproteínas
|
|
Cromoproteínas
|
|
FUNCIONES
Estructural |
|
Enzimatica
|
|
Contráctil
|
|
Hormonal
|
|
Defensiva
|
|
Homeostática
|
|
Transporte
|
|
Reserva energética
|
|
24. DESNATURALIZACIÓN DE LAS PROTEÍNAS.
La desnaturalización puede ser provocada por diferentes causas o agentes desnaturalizantes de tipo físico o químico. Destacaremos dos de ellos: uno físico (aumento de temperatura) y otro químico (alteración del pH).
a) Aumento de temperatura. Los aumentos de temperatura provocan una mayor agitación molecular que hace que las interacciones débiles que mantienen estable la conformación de la proteína terminen por ceder con la consiguiente desnaturalización.
b) Alteración del pH. Estas alteraciones causan variación en el grado de ionización de distintos grupos funcionales (carboxilo, amino, hidroxilo, etc.) implicados en interacciones débiles que estabilizan la conformación. Estas variaciones provocan la rotura de dichas interacciones (sobre todo enlaces iónicos y también puentes de hidrógeno) y por lo tanto la desnaturalización (debido a ello son tan importantes los tampones que mantienen estable el pH de los fluidos biológicos).



El proceso de desnaturalización, si se lleva a cabo en condiciones suaves (variaciones moderadas y graduales de temperatura o pH), es reversible: la proteína puede recuperar su conformación tridimensional nativa si se restituyen las condiciones iniciales. Este proceso recibe el nombre de renaturalización. Se ha comprobado en multitud de experimentos que el proceso de renaturalización conlleva una recuperación de la función biológica de la proteína (que se había perdido durante la desnaturalización), lo cual constituye una prueba irrefutable de la singular relación existente entre la secuencia de aminoácidos, la conformación tridimensional, y la función biológica de una proteína: la secuencia de aminoácidos, que es lo único que permanece al final del proceso de desnaturalización, contiene la información suficiente para que se recupere la conformación tridimensional, y con ella la función biológica, en el proceso de renaturalización.
ANIMACIONES


CUESTIONES SOBRE PROTEÍNAS: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
ÁCIDOS NUCLEICOS
25. ESQUEMAS DE ÁCIDOS NUCLEICOS


26. PRESENTACIONES DE ÁCIDOS NUCLEICOS


27. INTRODUCCIÓN
Entre las biomoléculas más importantes, por su papel en el almacenamiento y transmisión de la información genética, se encuentran los ácidos nucleicos. Los ácidos nucleicos son macromoléculas formadas por la unión de unidades básicas denominadas nucleótidos. Dicha unión se realiza mediante un tipo de enlace conocido como puente fosfodiéster. Se puede considerar que los nucleótidos son los sillares estructurales de los ácidos nucleicos, del mismo modo que los aminoácidos lo son de las proteínas o los monosacáridos de los polisacáridos. Además de desempeñar este importante papel, los nucleótidos como tales tienen otras funciones biológicas de naturaleza energética o coenzimática.
28. CONSTITUYENTES QUÍMICOS DE LOS NUCLEÓTIDOS
Cuando se somete a los ácidos nucleicos a hidrólisis en condiciones suaves liberan sus unidades monoméricas constitutivas: los nucleótidos. Los sillares estructurales de otras macromoléculas, como los aminoácidos o los monosacáridos, no son susceptibles de descomponerse a su vez en unidades más simples; sin embargo los nucleótidos sí pueden sufrir hidrólisis dando lugar a una mezcla de pentosas, ácido fosfórico y bases nitrogenadas. Cada nucleótido está compuesto por una pentosa, una molécula de ácido fosfórico y una base nitrogenada enlazados de un modo característico.
Las pentosas que aparecen formando parte de los nucleótidos son la β-D-ribosa y su derivado, el desoxiazúcar 2'-β-D-desoxirribosa, en el que el grupo hidroxilo unido al carbono 2' fue sustituido por un átomo de hidrógeno. Ambas se encuentran en forma de anillos de furanosa. Las posiciones del anillo de furanosa se numeran convencionalmente añadiendo el signo (') al número de cada átomo de carbono para distinguirlas de las de los anillos de las bases nitrogenadas.

El tipo de ácido fosfórico que se encuentra en los nucleótidos es concretamente el ácido ortofosfórico.
Las bases nitrogenadas son compuestos heterocíclicos que, gracias al sistema de dobles enlaces conjugados que poseen en sus anillos, poseen un acusado carácter aromático, siendo su conformación espacial planar o casi planar. Sus átomos de nitrógeno poseen pares electrónicos no compartidos que tienen tendencia a captar protones, lo que explica su carácter débilmente básico. Los compuestos originarios de los que derivan estas bases nitrogenadas son la purina y la pirimidina.

Existen formando parte de los nucleótidos dos derivados de la purina (bases púricas), que son la adenina y la guanina, y tres derivados de la pirimidina (bases pirimídicas), que son la citosina, la timina y el uracilo. Todas ellas se obtienen por adición de diferentes grupos funcionales en distintas posiciones de los anillos de la purina o de la pirimidina. Las características químicas de estos grupos funcionales les permiten participar en la formación de puentes de hidrógeno, lo que resulta crucial para la función biológica de los ácidos nucleicos.
CUESTIONES: 1
29. NUCLEÓSIDOS
Las pentosas se unen a las bases nitrogenadas dando lugar a unos compuestos denominados nucleósidos. La unión se realiza mediante un enlace N-glucosídico entre el átomo de carbono carbonílico de la pentosa (carbono 1') y uno de los átomos de nitrógeno de la base nitrogenada, el de la posición 1 si ésta es pirimídica o el de la posición 9 si ésta es púrica. El enlace N-glucosídico es una variante del tipo más habitual de enlace glucosídico (O-glucosídico), que se forma cuando un hemiacetal intramolecular reacciona con una amina, en lugar de hacerlo con un alcohol, liberándose una molécula de agua.
Los nucleósidos en estado libre sólo se encuentran en cantidades mínimas en las células, generalmente como productos intermediarios en el metabolismo de los nucleótidos. Existen dos tipos de nucleósidos: los ribonucleósidos, que contienen β-D-ribosa como componente glucídico, y los desoxirribonucleósidos, que contienen β-D-desoxirribosa. En la naturaleza se encuentran ribonucleósidos de adenina, guanina, citosina y uracilo, y desoxirribonucleósidos de adenina, guanina, citosina y timina. Los nucleósidos se nombran añadiendo la terminación -osina al nombre de la base nitrogenada si ésta es púrica o bien la terminación -idina si ésta es pirimídica, y anteponiendo el prefijo desoxi- en el caso de los desoxirribonucleósidos.



30. NUCLEÓTIDOS
Los nucleótidos resultan de la unión mediante enlace éster de la pentosa de un nucleósido con una molécula de ácido fosfórico. Esta unión, en la que se libera una molécula de agua, puede producirse en cualquiera de los grupos hidroxilo libres de la pentosa, pero como regla general tiene lugar en el que ocupa la posición 5'; es decir, los nucleótidos son los 5' fosfatos de los correspondientes nucleósidos. La posesión de un grupo fosfato, que a pH 7 se encuentra ionizado, confiere a los nucleótidos un carácter marcadamente ácido.
Además de los nucleótidos monofosfato que acabamos de describir, que son los sillares estructurales de los ácidos nucleicos, existen en la naturaleza nucleótidos di~ y trifosfato, que resultan de la unión mediante enlace anhidro de 1 ó 2 moléculas de ácido fosfórico adicionales a la que se encuentra unida al carbono 5' de la pentosa (Figura 9.4).



Al igual que los nucleósidos, los nucleótidos pueden clasificarse en ribonucleótidos y desoxirribonucleótidos según contengan ribosa o desoxirribosa respectivamente. Existen diversas maneras de nombrar los nucleótidos; cada nucleótido se identifica mediante tres letras mayúsculas, la primera de ellas es la inicial de la base nitrogenada, la segunda indica si el nucleótido es Mono~, Di~, o Trifosfato, y la tercera es la inicial del grupo fosfato; en el caso de los desoxirribonucleótidos se antepone una "d" minúscula a estas tres siglas.
Otra forma de nombrarlos consiste en anteponer la palabra ácido y añadir la terminación -ílico al nombre de la base nitrogenada correspondiente; así, por ejemplo, el AMP se puede denominar también como ácido adenílico; este sistema de nomenclatura resulta un tanto ambiguo ya que no especifica el número de grupos fosfato. También es habitual nombrar a los nucleótidos como fosfatos de los correspondientes nucleósidos; por ejemplo, el ATP es el trifosfato de adenosina o adenosín-trifosfato.

31. FUNCIONES DE LOS NUCLEÓTIDOS
Además de ser los sillares estructurales de los ácidos nucleicos, los nucleótidos desempeñan en las células otras funciones no menos importantes. Los enlaces anhidro que unen los grupos fosfato adicionales de los nucleótidos di~ y trifosfato son enlaces ricos en energía: necesitan un aporte energético importante para formarse y liberan esta energía cuando se hidrolizan. Esto les permite actuar como transportadores de energía. En concreto, el trifosfato de adenosina (ATP) actúa universalmente en todas las células transportando energía, en forma de energía de enlace de su grupo fosfato terminal, desde los procesos metabólicos que la liberan hasta aquellos que la requieren. En algunas reacciones del metabolismo, otros nucleótidos trifosfato como el GTP, CTP y UTP, pueden sustituir al ATP en este papel.

Por otra parte, algunos nucleótidos o sus derivados pueden actuar como coenzimas (sustancias orgánicas no proteicas que resultan imprescindibles para la acción de muchos enzimas). Tal es el caso del NAD, NADP, FAD o FMN, nucleótidos complejos en los que aparecen bases nitrogenadas diferentes a las típicas de los ácidos nucleicos, que actúan como transportadores de electrones en reacciones metabólicas de oxidación-reducción.

| Algunos nucleótidos que no forman ácidos nucléicos | |
 |  |
FMN : Flavín Mononucleótido
|
NAD : Nicatamín Adenosín Dinucleótido
|
 |  |
FAD : Flavín adenosín Dinucleótido
|
Coenzima A
|
Otros nucleótidos como el cAMP, un fosfato cíclico de adenosina en el que el grupo fosfato está unido mediante enlace éster al hidroxilo de la posición 3' y al de la posición 5', actúan como mediadores en determinados procesos hormonales, transmitiendo al citoplasma celular señales químicas procedentes del exterior.





Enlace fosfodiéster
ATP
32. ÁCIDOS NUCLEICOS
Los ácidos nucleicos son polímeros de nucleótidos. En ellos la unión entre las sucesivas unidades nucleotídicas se realiza mediante enlaces tipo éster-fosfato que resultan de la reacción entre el ácido fosfórico unido al carbono 5' de la pentosa de un nucleótido y el hidroxilo del carbono 3' de la pentosa de otro nucleótido. Este tipo de unión, en la que un grupo fosfato queda unido por dos enlaces éster a dos nucleótidos sucesivos, se conoce también como puente fosfodiéster.
Cuando dos nucleótidos se unen mediante un puente fosfodiéster el dinucleótido que resulta conserva un grupo 5' fosfato libre en un extremo que puede reaccionar con el grupo hidroxilo 3' de otro nucleótido, y un grupo hidroxilo 3' libre que puede reaccionar con el grupo 5' fosfato de otro nucleótido. Esta circunstancia permite que mediante enlacesfosfodiéster se puedan enlazar un número elevado de nucleótidos para formar largas cadenas lineales que siempre tendrán en un extremo un grupo 5' fosfato libre y en el otro un grupo hidroxilo 3' libre.
De manera análoga a lo establecido para otros tipos de biomoléculas, el compuesto formado por una cadena de hasta 10 nucleótidos se denomina oligonucleótido, mientras que si el número de unidades nucleotídicas es superior a 10 se dice que es un polinucleótido. En la mayor parte de los casos, las cadenas polinucleotídicas de los ácido nucleicos contienen varios miles de estas unidades monoméricas unidas por puentes fosfodiéster.



Del mismo modo que se definió la estructura primaria de las proteínas como su secuencia de aminoácidos, se puede definir laestructura primaria de los ácidos nucleicos como su secuencia de nucleótidos. Los ácidos nucleicos poseen un esqueleto de las mismas características, formado por una sucesión alterna de pentosas y grupos fosfato, a partir del cual se proyectan lateralmente las distintas bases nitrogenadas.
28.1. Tipos de ácidos nucleicos
Existen dos tipos principales de ácidos nucleicos: el ácido ribonucleico (RNA), que es un polímero de ribonucleótidos, y el ácido desoxirribonucleico (DNA), que es un polímero de desoxirribonucleótidos. Las diferencias en cuanto a composición entre estos dos tipos de ácido nucleico vienen dadas por las que existen entre sus nucleótidos constituyentes y residen en el tipo de pentosa y bases nitrogenadas características de uno y otro.

Los ácidos nucleicos son moléculas portadoras de información. La secuencia ordenada de sus nucleótidos junto con las estructuras características de las cadenas polinucleotídicas proporcionan las bases físico-químicas para que estas macromoléculas puedan almacenar y transmitir la información genética en el proceso de reproducción de los seres vivos, lo que constituye su función biológica primordial.
ANIMACIONES


33. LA DOBLE HÉLICE
A comienzos de los años 50 tres centros de investigación rivalizaban en el análisis de la estructura tridimensional de las biomoléculas mediante cristalografía de rayos X. Uno de ellos era el Instituto de Tecnología de California, cuya división de química, dirigida por Linus Pauling, se había apuntado varios éxitos notables en el descubrimiento de la estructura secundaria de las proteínas. Otro era el Laboratorio Cavendish de la Universidad de Cambridge (Inglaterra). Fue en el Laboratorio Cavendish donde coincidieron a comienzos de 1951 dos jóvenes investigadores, James D. Watson y Francis H.C. Crick, que estaban llamados a ser quienes desvelaran finalmente la estructura de la molécula de ADN. Un tercer grupo se había formado en el King’s College de Londres bajo la jefatura de John Randall, que contaba con la colaboración de Maurice Wilkins y de la experta cristalógrafa Rosalind Franklin.
Entre 1951 y 1953 se desató entre estos grupos una especie de carrera por identificar la estructura tridimensional del DNA, carrera que se aceleró cuando la publicación del experimento de Hershey y Chase a finales de 1952 puso a todos los grupos sobre la pista correcta de cual era en realidad la molécula de la herencia. En el King’s College, Rosalind Franklin había desarrollado una técnica que le permitía obtener fibras de DNA altamente orientadas y obtener así difractogramas de rayos X de una calidad y lujo de detalles muy superiores a los conocidos hasta entonces. Mientras tanto Watson y Crick trataban de construir su propio modelo tridimensional basándose en difractogramas de una calidad muy inferior. No obstante, su trabajo se encontraba muy avanzado; habían analizado cuidadosamente la estructura de los nucleótidos individuales y se habían percatado de que los datos obtenidos por Chargaff tres años antes, sobre las proporciones de las bases nitrogenadas, debían tener algún significado relevante, lo que probablemente fue una de las claves de su éxito posterior. Fue entonces cuando Jim Watson, durante una conversación con Maurice Wilkins, pudo ver algunos de los difractogramas obtenidos por Rosalind Franklin; la simple inspección visual de aquellos difractogramas proporcionó a Watson las claves que le faltaban para resolver finalmente la estructura del DNA. En pocas semanas Watson y Crick terminaron de encajar sus propios datos con lo que se apreciaba en los difractogramas de Franklin y elaboraron un modelo definitivo que fue publicado en el número de abril de la revista Nature. La carrera había terminado.


El modelo propuesto por Watson y Crick, mundialmente conocido como la doble hélice, presentaba las siguientes características:
- La molécula de DNA está formada por dos cadenas polinucleotídicas antiparalelas, es decir, si una cadena se recorre en dirección 5’—›3’, su vecina discurriría en dirección 3’—›5’.
- Ambas cadenas se encuentran formando un arrollamiento helicoidal de tipo plectonémico, es decir, para separarlas habría que desenrollarlas girando una sobre la otra. El arrollamiento es además dextrógiro.
- El conjunto forma una estructura cilíndrica con un diámetro constante de 2 nm.
- Los esqueletos azúcar-fosfato de las cadenas polinucleotídicas se encuentran en el exterior de la estructura, formando lo que serían las guías de una especie de escalera de caracol.
- Las bases nitrogenadas se proyectan desde los esqueletos azúcar-fosfato hacia el interior de la estructura y se disponen apiladas por pares formando lo que equivaldría a los peldaños de la escalera.
- Los pares de bases nitrogenadas están formados invariablemente por una purina y una pirimidina. Además, siempre se encuentran enfrentadas adenina con timina por una parte y guanina con citosina por otra.
- Las dos cadenas polinucleotídicas se encuentran unidas por puentes de hidrógeno entre grupos funcionales de las bases nitrogenadas que forman cada par. Cada adenina forma dos puentes de hidrógeno con la correspondiente timina y cada guanina tres con la citosina. Pares de bases diferentes a los establecidos no podrían formar puentes de hidrógeno.
- La distancia entre cada par de bases sucesivo es de 0,34 nm. Cada vuelta completa de la hélice (paso de rosca) alberga exactamente 10 pares de nucleótidos, lo que se corresponde con una longitud de 3,4 nm. Ambas periodicidades aparecían reflejadas en los difractogramas.






Uno de los aspectos más interesantes del modelo de Watson y Crick residía en que no sólo encajaba con los datos de difracción de RX sino que además proporcionaba una explicación para la hasta entonces desconcertante regla de Chargaff. En efecto, si todos los pares de bases eran necesariamente A-T o G-C, en cualquier muestra de DNA el número de restos de adenina debía ser igual al de timina y el de guanina al de citosina, de lo que se deduce que el número total de bases púricas debería ser igual al de bases pirimídicas.
Además, este emparejamiento específico de las bases nitrogenadas podría encerrar un profundo significado biológico, pues, como Watson y Crick sugerían en su artículo en Nature, tal emparejamiento podría ser la base del mecanismo por el que el material genético creaba copias de si mismo en cada ciclo de reproducción celular. La complementariedad interna de la doble hélice, regida por la regla de Chargaff, hacía que cada una de las dos cadenas polinucleotídicas que la formaban pudiera ser utilizada como molde para sintetizar otra con una secuencia de bases complementaria.
La publicación del modelo de Watson y Crick en abril de 1953 y la gran difusión que tuvo en los meses posteriores diluyó rápidamente cualquier resto de escepticismo acerca del papel del DNA como material hereditario, que ya no volvió a ser discutido. Todo ello supuso una auténtica revolución en el seno de las ciencias biológicas y el nacimiento de lo que se dio en llamar biología molecular, área del conocimiento que tuvo un gran desarrollo en las décadas siguientes y que ha contribuido de forma decisiva a nuestra comprensión actual del funcionamiento de los sistemas vivos.
ANIMACIONES








34. OTRAS ESTRUCTURAS DE LA MOLÉCULA DE ADN
La doble hélice del DNA tal como fue descrita por Watson y Crick representa la estructura más común de esta macromolécula (la llamada forma B). Años más tarde se demostró que el DNA puede existir en al menos dos formas alternativas (la forma A y la forma Z) que difieren ligeramente de la estructura original en aspectos como las distancias entre nucleótidos sucesivos o los ángulos de enlace entre los componentes de estos nucleótidos.
- ADN-B: ADN en disolución, 92% de humedad relativa, se encuentra en soluciones con baja fuerza iónica se corresponde con el modelo de la Doble Hélice.
- ADN-A: ADN con 75% de humedad, requiere Na, K o Cs como contraiones, presenta 11 pares de bases por giro completo y 23 Å de diámetro. Es interesante por presentar una estructura parecida a la de los híbridos ADN-ARN y a las regiones de autoapareamiento ARN-ARN
- ADN-Z: doble hélice sinistrorsa (enrollamiento a izquierdas), 12 pares de bases por giro completo, 18 Å de diámetro, se observa en segmentos de ADN con secuencia alternante de bases púricas y pirimidínicas (GCGCGC), debido a la conformación alternante de los residuos azúcar-fosfato sigue un curso en zig-zag. Requiere una concentración de cationes superior a la del ADN-B.
Por otra parte, se ha podido comprobar que en algunos virus el DNA aparece en estado monocatenario (una sola cadena polinucleotídica por molécula en lugar de dos), lo que constituye una excepción a la primitiva afirmación de que el DNA es siempre una doble hélice de cadenas polinucleotídicas. Sin embargo, se trata de una “excepción que confirma la regla”, ya que incluso en estos virus el DNA pasa por un estado bicatenario transitorio, que resulta imprescindible para su replicación durante el ciclo de reproducción viral.

ANIMACIONES

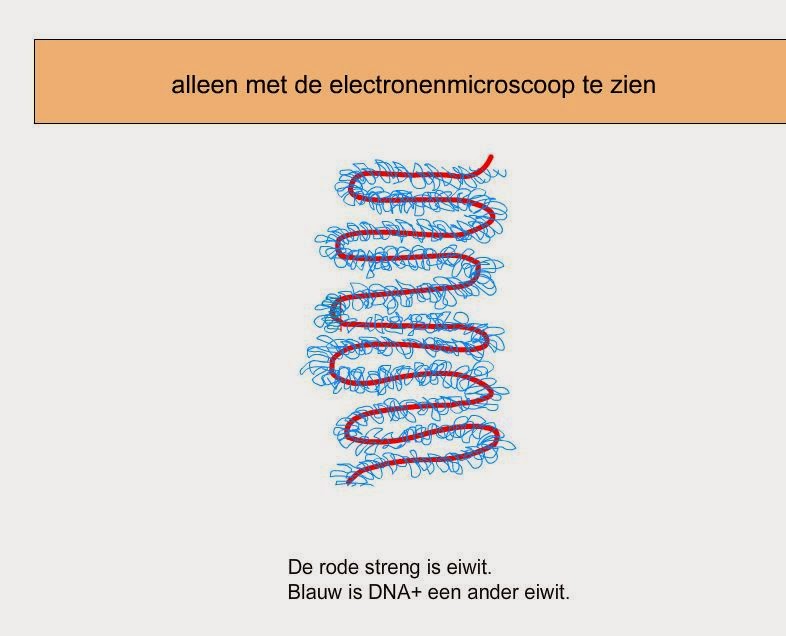
VISORES 3D
Estructura del ADN 3
ADN: estructura 4
La doble hélice 5
Estructura de la molécula de ADN 6
Estructura del ADN 7
Línea de tiempo en la genética
ADN: estructura 4
La doble hélice 5
Estructura de la molécula de ADN 6
Estructura del ADN 7
Línea de tiempo en la genética
35. DESNATURALIZACIÓN E HIBRIDACIÓN DEL ADN
La molécula de DNA es muy estable, gracias a la gran cantidad de puentes de hidrógeno que se establecen entre las bases nitrogenadas a lo largo de las cadenas polinucleotídicas y a las interacciones hidrofóbicas generadas entre los anillos aromáticos apilados de estas bases. Sin embargo, de manera similar a lo que ocurre con las proteínas, la molécula puede desestabilizarse y abandonar su conformación tridimensional característica en doble hélice como respuesta a cambios en el pH o a aumentos de temperatura. Este proceso se conoce con el nombre de desnaturalización y sucede a valores de pH próximos a 13 o temperaturas alrededor de 100 ºC .
La temperatura a la que un 50% de la doble hélice se encuentra separada se conoce como temperatura de fusión (Tm); su valor difiere de unas muestras de DNA a otras y está en función del contenido en pares G-C. Esto es debido a que, al estar los pares G-C unidos por tres puentes de hidrógeno frente a los dos de los pares A-T, es necesaria una mayor cantidad de energía para desestabilizar una doble hélice rica en pares G-C. Así, la temperatura de fusión de una muestra de DNA es un indicador de su composición en bases nitrogenadas.

La desnaturalización del DNA puede seguirse experimentalmente midiendo en un espectrofotómetro la absorción de luz ultravioleta por la disolución que lo contiene. La absorción de luz ultravioleta aumenta considerablemente con la desnaturalización debido a que los anillos aromáticos de las bases nitrogenadas absorben mucha más luz de esa longitud de onda cuando se encuentran desplegadas que cuando están apiladas en el interior de la doble hélice.
De manera análoga a lo que sucede con las proteínas, la desnaturalización del DNA es, en determinadas condiciones experimentales, reversible, siendo este proceso conocido como renaturalización. Si las cadenas polinucleotídicas que resultan de la desnaturalización se incuban a unos 65 ºC durante varias horas, se comprueba que las dobles hélices originales se reconstruyen espontáneamente. Paralelamente se produce el consiguiente descenso en la absorción de luz ultravioleta.
La renaturalización sirvió de base para el desarrollo de las llamadas técnicas de hibridación del DNA. Si se mezclan muestras de DNA desnaturalizado procedentes de especies diferentes y se incuba la mezcla en condiciones adecuadas para que se produzca la renaturalización, una fracción de las dobles hélices obtenidas serán híbridas, es decir, con cadenas polinucleotídicas de una y otra especie. El porcentaje de hibridación será mayor cuanto más parecidas sean las secuencias de nucleótidos de ambas especies, de manera que este porcentaje puede utilizarse como un indicador del parentesco evolutivo existente entre ellas. Antes de que estuviesen disponibles las actuales técnicas de secuenciación del DNA se utilizaron con profusión las técnicas de hibridación para el análisis de dicho parentesco.


36. ARN. ESTRUCTURA Y TIPOS
Se comprobó que en las células eucariotas la casi totalidad del DNA celular se encuentra en el interior del núcleo mientras que la mayor parte del RNA se encuentra en el citoplasma (aunque algunas zonas del núcleo, en particular el nucléolo, también son ricas en RNA). Por otra parte, del total de RNA citoplasmático una fracción muy importante se encontraba asociado a determinadas proteínas para formar unas partículas, visibles al microscopio electrónico, que fueron denominadas ribosomas. Experimentos realizados utilizando aminoácidos marcados radiactivamente pronto demostraron que los ribosomas eran el lugar de la célula donde se llevaba a cabo la síntesis de las proteínas, por lo que ya desde entonces se asoció al RNA con este proceso.
36.1. Eetructura y función del ARN
La estructura tridimensional del RNA difiere claramente de la del DNA. En general las moléculas de RNA son monocatenarias (una sola cadena polinucleotídica), por lo que su composición en bases nitrogenadas no se ajusta a la regla de equivalencia de Chargaff. Sin embargo, existen moléculas de RNA que, aun siendo monocatenarias, presentan tramos con secuencias de bases complementarias los cuales adoptan estructuras en doble hélice, denominadashorquillas, de características análogas a las del DNA. En ocasiones, cuando las secuencias complementarias no son contiguas, se forman bucles de bases no emparejadas dentro de las horquillas. En las dobles hélices de RNA la adenina se empareja con el uracilo, que tiene estructura similar e idénticas posibilidades de formar puentes de hidrógeno que la timina, y la guanina con la citosina.
Hoy sabemos que la función primordial del RNA en las células consiste en servir de intermediario para transferir la información genética cifrada en el DNA a la estructura tridimensional de las proteínas en el proceso de expresión de la información genética, que analizaremos más adelante en este capítulo.
De todos modos, en algunos virus el RNA constituye en sí mismo el material genético además de servir de intermediario en el proceso de síntesis de las proteínas virales. En algunos de estos virus la molécula de RNA que constituye el cromosoma viral es bicatenaria y presenta en toda su longitud estructura de doble hélice. También existen virus con cromosomas de RNA monocatenario.
36.2. Tipos de ARN
Existen varios tipos de RNA que difieren en el tamaño, estructura y función específica de sus moléculas. Todos ellos se sintetizan en el núcleo celular a partir de secuencias de DNA que sirven como molde y una vez sintetizados atraviesan los poros nucleares y se incorporan a sus diferentes destinos en el citoplasma.
a) ARN ribosómico (rRNA). Constituye alrededor del 80% del RNA celular total. Sus moléculas son monocatenarias y de gran longitud (varios miles de nucleótidos). Algunas de ellas presentan horquillas y bucles con secuencias internas complementarias. Se encuentra en el citoplasma donde, en asociación con diferentes proteínas, forma parte estructural de los ribosomas.

b) ARN de transferencia (tRNA). Sus moléculas son relativamente pequeñas (75 a 90 nucleótidos de longitud). Presentan una estructura característica con horquillas y bucles que les dan el aspecto de hojas de trébol cuando se representan sobre un plano: su estructura tridimensional presenta en realidad forma de L invertida. El tRNA presenta bases nitrogenadas diferentes a las características de los ácidos nucleicos en una proporción que puede alcanzar el 10% del total. Su función consiste en transportar de manera específica a los diferentes aminoácidos hasta los ribosomas para que allí sean ensamblados en las cadenas polipeptídicas en formación. Existen alrededor de 50 tipos de tRNAs que difieren en sus secuencias de nucleótidos y en algunos aspectos de su conformación tridimensional; sin embargo todos ellos comparten algunas características:
· En el extremo 5’ de la cadena polinucleotídica hay un triplete de bases nitrogenadas una de las cuales es siempre guanina.
· En el extremo 3’ la cadena polinucleotídica finaliza con la secuencia CCA y estas bases no están emparejadas. En este lugar es donde el tRNA se une a su aminoácido correspondiente.
· La molécula presenta tres brazos cada uno de los cuales consta de una horquilla con estructura en doble hélice y un bucle formado por bases sin emparejar (Figura 19.16). Se distinguen el brazo T (por donde la molécula se une al ribosoma), el brazo D (lugar que reconocen los enzimas específicos que unen los tRNA con sus aminoácidos correspondientes) y el brazo A (cuyo bucle presenta un triplete de bases, denominado anticodon, que es complementario de otro triplete, llamado codon, que se encuentra en el RNA mensajero, siendo esta complementariedad de gran importancia en el proceso de síntesis de proteínas).

c) ARN mensajero (mRNA). Sus moléculas están formadas en general por varios miles de nucleótidos y tienen una estructura lineal, aunque en ocasiones presentan horquillas y bucles. Su misión es trasladar la información genética almacenada en el DNA hasta los ribosomas para que allí se exprese en forma de proteínas. Los mRNA son en general moléculas de vida muy corta, ya que una vez cumplida su misión son degradados por unos enzimas llamados ribonucleasas.
d) ARN nucleolar (nRNA).-Se encuentra en el nucléolo, donde tiene lugar su síntesis. Una vez sintetizado se fragmenta por acción enzimática y da lugar a diferentes tipos de rRNA y tRNA.
ANIMACIONES


37. REPLICACIÓN DEL ADN
Cada vez que una célula se reproduce por división su material genético debe ser copiado para que las dos células hijas dispongan una copia completa del mismo. Uno de los requisitos que debería cumplir una eventual molécula de la herencia es precisamente la capacidad para crear copias fieles de sí misma de manera que la información pudiese ser transmitida en las sucesivas generaciones celulares.
Watson y Crick se percataron, y así lo sugerían en su artículo de Nature, de que el modelo de estructura en doble hélice que habían elaborado proporcionaba las bases físico-químicas para un mecanismo de replicación del DNA. En efecto, la estricta complementariedad de bases nitrogenadas a lo largo de la doble hélice permite que cada una de las dos cadenas polinucleotídicas que la forman pueda ser utilizada como molde para sintetizar una nueva cadena complementaria.
Así, desenrollando las dos cadenas de una hélice original y utilizando cada una de ellas como molde para sintetizar una nueva cadena, en la que los nucleótidos se irán añadiendo conforme a las reglas que rigen el emparejamiento de las bases, se obtendrán dos dobles hélices “hijas” idénticas, portadoras de la misma información.
El mecanismo que aquí se ha esbozado fue propuesto por Watson y Crick en un artículo publicado en el número de Nature de mayo de 1953, aclarando así lo que sugerían en su artículo del mes anterior. Tal mecanismo fue conocido como replicación semiconservativa para resaltar el hecho de que cada una de las dobles hélices hijas conserva la mitad, es decir, una de las cadenas, de la doble hélice original.

El modelo de replicación semiconservativa propuesta por Watson y Crick pareció acertado a muchos investigadores por su sencillez y elegancia. Sin embargo, se plantearon algunos modelos alternativos que no podían ser descartados a priori. Uno de ellos era el modelo de replicación conservativa, según el cual la doble hélice original, sin perder su integridad, sirve de patrón para sintetizar una doble hélice hija totalmente nueva, de manera que la doble hélice original se conserva intacta a lo largo de las sucesivas generaciones celulares. Otro era el modelo de replicación dispersiva, según el cual la doble hélice original se descompone en infinidad de pequeños fragmentos, cada uno de los cuales sirve de molde para sintetizar un fragmento complementario siguiendo las reglas de emparejamiento de bases; a continuación los fragmentos resultantes se empalman en el orden correcto para dar lugar a dos dobles hélices hijas cada una de las cuales contiene fragmentos de la original y fragmentos de nueva síntesis.


ANIMACIONES


38. RESUMEN ESQUEMÁTICO DE LAS BIOMOLÉCULAS
|
MONOSACÁRIDOS
| Triosas | Glieraldeído (aldotriosa) Dihidroxiacetona (cetotriosa) |
| Tetrosas | Eritrosa (aldotetrosa) Treosa (aldotetrosa) Eritrulosa (cetotetrosa) |
| Pentosas | Ribosa (aldopentosa), desoxirribosa (aldopentosa) (→ ácidos nucleicos) Arabinosa (aldopentosa) (monómero del polisacárido arabana → gomas veg.) Xilosa (aldopentosa) (monómero del polisacárido xilana de las maderas) Ribulosa (cetopentosa) (interviene en la fotosíntesis) Xilulosa (cetopentosa) (interviene en la fotosíntesis) |
| Hexosas | Glucosa (aldohexosa) (azúcar de uva) (monómero del almidón y de la celulosa) Galactosa (aldohexosa) (monómero del disacárido lactosa de la leche) Manosa (aldohexosa) (monómero de los polisacáridos manosanas) Frutosa (= levulosa) (cetohexosa) (azúcar de las frutas) (monómero de la sacarosa) |
| Heptosas | Sedoheptulosa |
OLIGOSACÁRIDOS (ósidos holósidos)
| Disacáridos | Lactosa [β-D-galactosa (1→4) ß-D-fructosa] (azúcar de la leche) Sacarosa [α-D-glucosa (1→2) ß-D-fructosa] (azúcar de la caña y remolacha) Celobiosa [β-D-glucosa (1→4) ß-D-glucosa] (← hidrólisis de la celulosa) Maltosa [α-D-glucosa (1→4) α-D-glucosa] (cereales) (← hidrólisis de la almidón) Isomaltosa [≈ maltosa, con uniones α(1→6)] (← hidrólisis del almidón y glucógeno) |
POLISACÁRIDOS (ósidos holósidos)
| Homopolisacáridos | Pentosanas: Xilanas (madera) Arabanas (gomas vegetales) |
| Hexosanas: Celulosa: Σ β-D-glucosa con enlaces β(1→4) (unidad repetitiva: celobiosa) Quitina: ∑ N-acetil-β-D-glucosamina con enlaces β(1→4) Almidón: Σ α-D-glucosa (amilosa + amilopectina) (→ amiloplastos) - Amilosa: Σ α-D-glucosa con enlaces α(1→4) (sin ramas) (unidad rep.: maltosa) - Amilopectina: Σ α-D-glucosa con enlaces α(1→4) (con ramificaciones α(1→6) cada 15-30 restos de glucosa) Glucógeno: ≈ amilopectina, pero más ramificado (cada 8-10 restos de glucosa) | |
| Heteropolisacáridos | En plantas y algas: Hemicelulosas, pectinas, agar-agar, gomas, mucílagos |
| En animales: Glucosaminoglucanos = mucopolisacáridos: - Ácido hialurónico - Condroitina: ambos se asocian a proteínas → mucinas = proteoglucanos Heparina |
ÓSIDOS HETERÓXIDOS = GLUCOCONJUGADOS
| Glucano (parte glucídica) + Aglucón (lípido o proteína) | |
| Glucoproteínas | Proteoglucanos = mucinas (glucano → mucopolisacáridos) Péptidoglucanos = mureína [glucano: Σ (N-acetil-glusamina + N-acetil-murámico); aglucón: tetrapéptido] → mucus Glucoproteínas de la membrana plasmática → glucocálix |
| Gluclolípidos | En el resumen de los lípidos |
LIPIDOS SAPONIFICABLES
| Ácidos grasos | Saturados | Ácido palmítico (16:0) (ácido hexadecanoico) Ácido esteárico (18:0) |
| Insaturados | Ácido oleico (octadecenoico) (18:1 ω 9) Ácido linoleico (octadecadienoico) (18:2 ω 6) Ácido linolénico (18:3 ω 3) Araquidónico (20:4 ω 6) | |
| Triacilglicéridos (= triacilgliceroles) o grasas | Glicerina (=glicerol) + 3 ácidos grasos (éster). - Simples: tripalmitina, triestearina, trioleína - Mixtos | |
| Ceras | Alcohol graso (de cadena larga) + ácido graso de cadena larga. Cera de abeja, lanolina, espermaceti,... | |
| Complejos o de membrana | Glicerolípidos | 2 ácidos grasos + 2 glicerol (éster) + sustituyente. Gliceroglucolípidos: sustituyente → monosacárido Glicerofosfolípidos = fosfolípidos ← ácido fosfatídico |
| Esfingolípidos | Ceramida + sustituyente Esfingoglucolípidos: sustituyente → monosacáridos - Cerebrósidos: sustituyente → glucosa o galactosa - Gangliósidos: sustituyente → oligosacáridos ramificados Esfingofosfolípidos → esfingomielinas Sustituyente → H3PO4 + etanolamina o colina | |
| Eicosanoides | Prostaglandinas ← derivan del prostanoato Tromboxanos Leucotrienos | |
LÍPIDOS INSAPONIFICABLES
| Terpenos o isoprenoides | Σ isopereno (2 metil-butadieno). Tenemos: |
| Monoterpenos → limoneno, mirceno, geraniol, mentol, pineno, timol, alcanfor,... Diterpenos → fitol, vitaminas A, E y K,... Triterpenos → escualeno, lanosterol (precursoras del colesterol) Tetraterpenos → carotenoides (carotenos → vit. A, licopenos y xantofilas),... Politerpenos → caucho | |
| Esteroides | Derivan del gonano (anillo-ciclopentanoperhidrofenantreno). Tenemos: |
| Sales biliares (derivan de los ácidos taurocólico y glicocólico): - Ácido cólico - Ácido desoxicólico | |
| Esteroles: - Colesterol → precursor de casi todos los demas esteroides - Grupo de la vitamina D - Estradiol | |
| Hormonas esteroideas: - Hormonas de la corteza suprarrenal: cortisona o cortisol, aldosterona,... - Hormonas sexuales masculinas: andrógenos (→ testosterona) - Hormonas sexuales femeninas: estrógenos, progesterona,... - Ecdisonas → regulan la muda de los artrópodos |
HOLOPROTEÍNAS
| Globulares | Estructura compacta esférica. Solubles en agua. Responsables de las act. biológicas de la célula. | |
| Albúminas | Función de transporte, de reserva de aminoácidos o de defensa. | |
| Ovoalbúmina (→ clara de huevo) | ||
| Seroalbúmina (→ sangre) | ||
| Lactoalbúmina (→ leche) | ||
| Globulinas | Ovoglobulina (→ huevo) | |
| Seroglobulina (→ sangre) | ||
| Lactoglobulina (→ leche) | ||
| α y β-globulinas (asociadas a la hemoglobina) | ||
| γ-globulinas = inmunoglobulinas (→ anticuerpos) | ||
| Actina | Junto con la miosina, es responsable de la contracción muscular | |
| Histonas → asociadas al ADN Protaminas → asociadas al ADN del espermatozoide | ||
| Fibrosas o esclero-proteínas | Forman haces paralelos. Insolubles en agua. Funciones estructurales o protectoras. | |
| Colágeno | En el tj. conjuntivo y la matriz extracelular. | |
| Miosina | Responsable, junto con la actina, de la contracción muscular. | |
| Queratinas | (← fibrinógeno). En la epidermis: cuernos, uñas, pelo y lana. | |
| Fibroína | Interviene en la coagulación sanguínea. | |
| Elastina | Conformación irregular → fibrosa y flexible (tj. conjuntivo). | |
HETEROPROTEÍNAS (grupo proteico + grupo prostético)
| Cromoproteínas | Grupo prostético → pigmento (proteína coloreada) | ||
| Porfirínicas | Grupo prostético → metalporfirina [anillo tetrapirrólico (4 anillos de pirrol) con un catión metálico en el centro] | ||
| HemoglobinaMioglobina | Grupo prostético → hemo (con un catión ferroso, Fe2+). Transportan O2, la mioglobina a los músculos. | ||
| Peroxidadas Catalasas Citocromos | Grupo prostético → hemino (con un catión férrico, Fe3+). Proxidadas, catalasas → enzimas. Citocromos → transportadores de e-. | ||
| Cloroplastinas (→ clorofila) | |||
| No porfirínicas | Hemocianina | Pig. azul transportador de O2 → Cu. Crustáceos y moluscos. | |
| Hemeritrina | Pig. respiratorio → Fe. En bivalvos y anélidos marinos. | ||
| Rodopsina | Grupo prostético → retinal (← vit. A). Pigmento capaz de absorber la luz. | ||
| Nucleoproteínas | Grupo prostético → ácido nucleico (+ protaminas / histonas). | ||
| Glucoproteínas | Grupo prostético → glúcido (son también glucoconjugados) | ||
| - Componentes estructurales de la matriz extracelular. - En las membranas celulares. - Como hormonas o como mucoproteínas (→ mucina). - Como anticongelantes (peces,...). | |||
| Sanguíneas: inmunoglobulinas, fibrinógeno. En la membrana de los eritrocitos → grupos sanguíneos. | |||
| Fosfoproteínas | Grupo prostético → H3PO4. | ||
| Caseína (= caseinógeno) (leche) Vitelina (yema del huevo) | |||
| Lipoproteínas | Grupo prostético → lípido. | ||
| Lipoproteínas de las membranas celulares | |||
| Lipoproteínas transportadoras de lípidos | Quilomicrones → en las células del intestino; de los enterocitospasan a la circulación y al hígado. | ||
| VLDL (lipoproteínas de densidad muy baja) | |||
| LDL (lipoproteínas de densidad baja) Transportan colesterol y fosfolípidos para formar las membranas celulares. La entrada de colesterol al int. celular depende dereceptores específicos de membrana. Si hay mucho colesterol en la célula, hay menos receptores y la acumulación de colesterol en la sangre puede producir ateromas arteriales. | |||
| HDL (lipoproteínas de densidad alta) | |||
| Tromboplastina | |||
39. PRÁCTICAS



Reconocimiento de proteínas
Reconocimiento de proteínas
Reconocimiento de proteínas. Texto
Enzimas. Texto
Desnaturalización de proteínas. Texto
Diferentes práct. y técnicas con proteínas
Muchas prácticas de proteínas y ADN
Cromatografía de proteínas
Extracción de ADN de cebolla
Extracción de ADN. Texto
Modelo de ADN. Texto
Maqueta de ADN. Texto
Electroforesis de ADN
Experimentos de Melsenson y Stahl
Electroforesis de ADN
Descifrando la vida
40. REPASO Reconocimiento de proteínas
Reconocimiento de proteínas. Texto
Enzimas. Texto
Desnaturalización de proteínas. Texto
Diferentes práct. y técnicas con proteínas
Muchas prácticas de proteínas y ADN
Cromatografía de proteínas
Extracción de ADN de cebolla
Extracción de ADN. Texto
Modelo de ADN. Texto
Maqueta de ADN. Texto
Electroforesis de ADN
Experimentos de Melsenson y Stahl
Electroforesis de ADN
Descifrando la vida





41. OTRAS PRESENTACIONES
Lípidos 1
Lípidos 3
Lípidos 4
Lípidos 5
Lípidos 6
Lípidos 3
Lípidos 4
Lípidos 5
Lípidos 6
Lípidos 7
Proteínas 1
Proteínas 2
Proteínas. Descarga 2
Proteínas. Descarga 4
Imágenes estructuras proteínas
Ácidos nucleicos
Ácidos nucleicos
Pp cromosomas
Ácidos nucleicos. Descarga 2
Ácidos nucleicos. Descarga 3
Ácidos nucleicos. Descarga 4
Imágenes ácidos nucleicos
Proteínas 1
Proteínas 2
Proteínas. Descarga 2
Proteínas. Descarga 4
Imágenes estructuras proteínas
Ácidos nucleicos
Pp cromosomas
Ácidos nucleicos. Descarga 2
Ácidos nucleicos. Descarga 3
Ácidos nucleicos. Descarga 4
Imágenes ácidos nucleicos
42. CUESTIONES
Cuestionario lípidos
Lípidos
Cuestiones resueltas
Cuestiones lípidos
Cuestiones lípidos 2
No hay comentarios:
Publicar un comentario